


索引优化--两张表
===============
两张表的索引优化,即两张表做关联查询
0 基于主键的关联查询
0.0 创建表;经典例子,员工和部门表
DROP TABLE IF EXISTS employee; CREATE TABLE IF NOT EXISTS employee ( id INT PRIMARY KEY auto_increment, name VARCHAR(50), dept_id INT ); DROP TABLE if EXISTS department; create table if NOT EXISTS department ( id INT PRIMARY KEY auto_increment, name VARCHAR(50) );
0.1 准备数据
INSERT INTO employee(name, dept_id) values ('Alice', 1); INSERT INTO employee(name, dept_id) values ('BOb', 2); INSERT INTO employee(name, dept_id) values ('David', 3); INSERT INTO department(name) VALUES('HR'); INSERT INTO department(name) VALUES('RD'); INSERT INTO department(name) VALUES('Sale');
0.2 查询
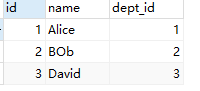
SELECT e.* FROM employee e left JOIN department d on e.dept_id = d.id;
结果:
0.3 Explain分析
EXPLAIN SELECT e.* FROM employee e left JOIN department d on e.dept_id = d.id;
结果:

分析:
- employee 表的 type=all 是全表扫描,这是没法避免的,因为查询的(想要的)就是 employee 的所有结果;
- department 表的 type=eq_ref 且 Using index,很理想;之所以这样是因为连接条件是 e.dept_id = d.id,d.id 本来就是 department 表的主键;
所以,如果是连表查询且右边表使用的是主键,则可以直接使用到索引,无须优化。
1 非主键的关联查询
想必每位小伙伴都在当当网(或者类似网站)上有过购书经历吧。这里,我们抽象一个非常简化版本的当当网,来分析两张表索引优化的安全。
每位小伙伴都需要先在当当网上注册一个账号,然后购买书籍,于是,小伙伴就是“顾客”表;当当网上有成千上万种图书,于是,每种书就是“书籍”表;当小伙伴下单买书时,得把哪位小伙伴购买了哪种书记录下来,这是“购书关系”表。
1.1 建表如下:
DROP TABLE IF EXISTS customer; create TABLE IF NOT EXISTS customer( id INT PRIMARY KEY auto_increment, name VARCHAR(50) ); DROP TABLE IF EXISTS book; create TABLE IF NOT EXISTS book( id INT PRIMARY KEY auto_increment, name VARCHAR(50) ); DROP TABLE IF EXISTS `order`; create TABLE IF NOT EXISTS `order`( id INT PRIMARY KEY auto_increment, customer_id INT, book_id INT );
1.2 插入数据
INSERT INTO customer(name) VALUES('Alice'); INSERT INTO customer(name) VALUES('Bob'); INSERT INTO customer(name) VALUES('David'); INSERT INTO book(name) VALUES('Java编程思想'); INSERT INTO book(name) VALUES('Spring实战'); INSERT INTO book(name) VALUES('Mysql技术内幕'); INSERT INTO `order`(customer_id, book_id) VALUES(1, 1); INSERT INTO `order`(customer_id, book_id) VALUES(1, 2); INSERT INTO `order`(customer_id, book_id) VALUES(1, 3); INSERT INTO `order`(customer_id, book_id) VALUES(2, 1); INSERT INTO `order`(customer_id, book_id) VALUES(2, 2); INSERT INTO `order`(customer_id, book_id) VALUES(3, 3);
1.3 需求
查询顾客的订单。这里,我们特意使用 customer 表连接 order 表的方式来查询,以验证并优化索引。
1.4 查询
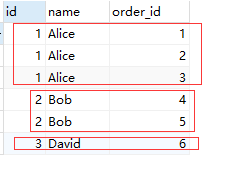
select c.id, c.name, o.id as order_id FROM customer c LEFT JOIN `order` o ON c.id = o.customer_id
1.5 结果
1.6 Explain分析
EXPLAIN select c.id, c.name, o.id as order_id FROM customer c LEFT JOIN `order` o ON c.id = o.customer_id
结果:

分析:
- 两张表的 type=all,全表扫描,不理想;
- rows 分别为3,6,也是全表扫描;
- 还使用了连接缓存。
结论:全部是全表扫描,需要优化。
2 优化
先想一想,为什么 ‘基于主键的关联查询’ 能够使用上索引,而 ‘非主键的关联查询’ 就没有使用上呢?很简单,因为主键本身就有索引!所以,也就很容易想到优化点了,即,给右表的连接字段加上索引(这不就是仿照主键的做法嘛)。
2.1 建立索引
CREATE INDEX idx_order_id ON `order`(customer_id);
2.2 再次Explain
EXPLAIN select c.id, c.name, o.id as order_id FROM customer c LEFT JOIN `order` o ON c.id = o.customer_id
结果:

分析:
- type=ref ,很理想;
- key=索引
- ref 也引用到了 customer 表的 id 字段(主键);
- Using Index
3 如果是右连接呢
3.1 查询
SELECT c.id, c.name, o.id as order_id FROM `order` o RIGHT JOIN customer c ON c.id = o.customer_id
注意:使用的是右连接
3.2 结果
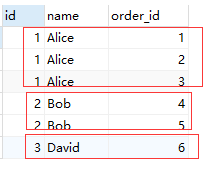
结果肯定是一样的
3.3 Explain分析

还是一样的,索引能够被正常使用上
4 结论
左连接右表建索引,右连接左表建索引——连接相反建。

