
第9章--基于水色图像的水质评价(一个svm实例)
from sklearn import svm
1. 数据预处理
针对《Python数据分析与挖掘实战》一书中第9章“基于水色图像的水质评价”。需要对原始的203张图片进行预处理,得到专家样本集。然后再使用svm分类器进行训练测试。
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 #数据预处理 4 5 from PIL import Image 6 import matplotlib.pyplot as plt 7 import os 8 import numpy as np 9 import pandas as pd 10 11 inputfile='../data/images' 12 outputfile='../data/result.xls' 13 14 #注意此处:得到一个包含图片名(如:'1_10.jpg')的列表 15 imgslist=os.listdir(inputfile) 16 17 result=[] 18 for i in range(len(imgslist)): #203张待处理图片 19 #label,number=imgslist[i].rstrip('.jpg').split('_') #label,number分别表示类别和序号 20 la=imgslist[i].rstrip('.jpg').split('_') 21 #将列表中数字字符串转换为数值 22 la_numbers=[int(x) for x in la] 23 24 '''1.图片切割''' 25 img=Image.open(inputfile+'/'+imgslist[i]) 26 M,N=img.size 27 box=[N/2-50,M/2-50,N/2+50,M/2+50] 28 roi=img.crop(box) 29 '''切割完成(100×100)''' 30 31 '''2.特征提取''' 32 #R,G,B=roi.split() #分离三个颜色通道 33 roi3=np.array(roi)/[256.0,256.0,256.0] 34 E=1.0/10000*(roi3.sum(axis=0).sum(axis=0)) #一阶颜色矩;有100×100个像素 35 err=roi3-E 36 delta=np.sqrt(1.0/10000*(err**2).sum(axis=0).sum(axis=0)) #二阶颜色矩 37 #s=pow(1.0/N*(pow(roi3-E,3).sum(axis=0).sum(axis=0)),1.0/3) 38 a=1.0/10000*(pow(err,3).sum(axis=0).sum(axis=0)) 39 s=abs(a)**(1.0/3)*-1 #三阶颜色矩;注意:负数开立方方法 40 ''' 41 r_E,g_E,b_E=E 42 r_del,g_del,b_del=delta 43 r_s,g_s,b_s=s 44 ''' 45 re=np.concatenate((la_numbers,E,delta,s)) #数组水平拼接,concatenate((a,b),axis=0) 46 result.append(re) 47 '''特征提取完毕''' 48 49 cols=[u'水质类别',u'序号',u'R通道一阶矩',u'G通道一阶矩',u'B通道一阶矩',\ 50 u'R通道二阶矩',u'G通道二阶矩',u'B通道二阶矩',\ 51 u'R通道三阶矩',u'G通道三阶矩',u'B通道三阶矩',] 52 res=pd.DataFrame(result,columns=cols) 53 res.to_excel(outputfile,index=False) #index=False
2. svm
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import pandas as pd 5 import numpy as np 6 7 inputfile='../data/moment.csv' 8 data=pd.read_csv(inputfile,encoding='gbk') #读取数据,指定编码为gbk 9 data=data.as_matrix() 10 11 ''' 12 出现问题:采用random.shuffle(data)导致data发生不可预知的变化 13 解决办法:采用numpy.random.shuffle(data)没有问题 14 ''' 15 #from random import shuffle #引入随机函数 16 np.random.shuffle(data) 17 data_train=data[:int(0.8*len(data)),:] #选取80%为训练数据 18 data_test=data[int(0.8*len(data)):,:] #选取20%为测试数据 19 20 x_train=data_train[:,2:]*30 #放大特征 21 y_train=data_train[:,0].astype(int) 22 x_test=data_test[:,2:]*30 #放大特征 23 y_test=data_test[:,0].astype(int) 24 25 '''导入模型相关的函数,建立并且训练模型''' 26 from sklearn import svm 27 model=svm.SVC() 28 model.fit(x_train,y_train) 29 30 '''保存/加载模型''' 31 import pickle 32 pickle.dump(model,open('../tmp/svm.model','wb')) 33 #model=pickle.load(open('../tmp/svm.model','rb')) 34 35 '''导入输出相关的库,生成混淆矩阵''' 36 from sklearn import metrics 37 cm_train=metrics.confusion_matrix(y_train,model.predict(x_train)) #训练数据的混淆矩阵 38 cm_test=metrics.confusion_matrix(y_test,model.predict(x_test)) #测试数据的混淆矩阵 39 40 '''保存结果''' 41 outputfile1='../tmp/cm_train.xls' 42 outputfile2='../tmp/cm_test.xls' 43 pd.DataFrame(cm_train,index=range(1,6),columns=range(1,6)).to_excel(outputfile1) 44 pd.DataFrame(cm_test,index=range(1,6),columns=range(1,6)).to_excel(outputfile2)
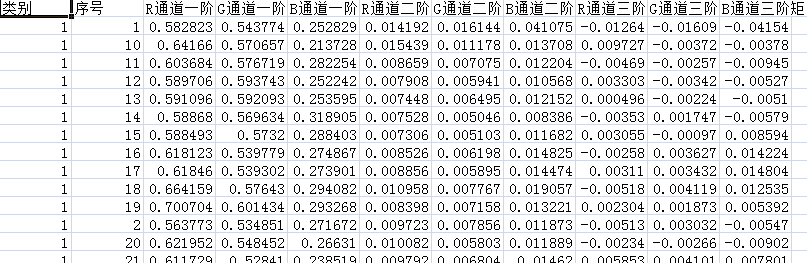
部分原始数据展示:
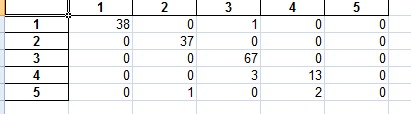
得到结果:
cm_train:
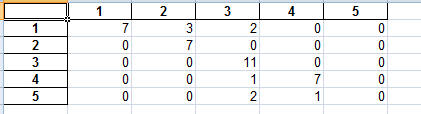
cm_test:
遇到问题:
11 '''
12 出现问题:采用random.shuffle(data)导致data发生不可预知的变化(破坏了原数据)
13 解决办法:采用numpy.random.shuffle(data)没有问题
14 '''

