
20145326蔡馨熤《信息安全系统设计基础》第13周学习总结
20145326蔡馨熤《信息安全系统设计基础》第13周学习总结
教材内容总结
网络编程简单过了一遍
-
点分十进制:
-
检索并打印一个DNS条目

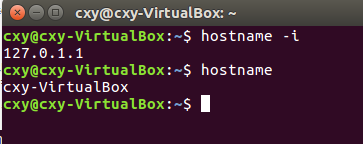
-
本机回送地址

-
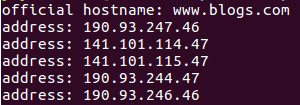
多个域名映射为同一个IP地址

-
多个域名映射到多个IP地址
并发编程(过多内容不再赘述)
- 程序级并发——进程
-
函数级并发——线程
-
三种基本的构造并发程序的方法:
-
进程:每个逻辑控制流是一个进程,由内核进行调度,进程有独立的虚拟地址空间
-
I/O多路复用:逻辑流被模型化为状态机,所有流共享同一个地址空间
-
线程:运行在单一进程上下文中的逻辑流,由内核进行调度,共享同一个虚拟地址空间
-
基于进程的并发编程
- 构造并发程序最简单的方法——用进程。常用函数如下:fork,exec,waitpid
- 构造并发服务器:在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。
-
需要注意的事情:
-
父进程需要关闭它的已连接描述符的拷贝(子进程也需要关闭)
-
必须要包括一个SIGCHLD处理程序来回收僵死子进程的资源
-
父子进程之间共享文件表,但是不共享用户地址空间
-
-
独立地址空间的优点是防止虚拟存储器被错误覆盖,缺点是开销高,共享状态信息才需要IPC机制
基于I/O多路复用的并发编程
- I/O多路复用技术使用select函数要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。
-
select函数处理类型为fd_set的集合,即描述符集合,并在逻辑上描述为一个大小为n的位向量,每一位b[k]对应描述符k,但当且仅当b[k]=1,描述符k才表明是描述符集合的一个元素。
-
描述符能做的三件事: 1、分配他们 2、将一个此种类型的变量赋值给另一个变量 3、用FDZERO、FDSET、FDCLR和FDISSET宏指令来修改和检查它们
- 当且仅当一个从该描述符读取一个字节的请求不会阻塞时,描述符k表示准备好可以读了
- 我们必须在每次调用select时都更新读集合
- 事件驱动程序:将逻辑流模型化为状态机。
-
一个状态机就是一组状态、输入事件和转移,其中转移就是将状态和输入事件映射到状态。
-
基于I/O多路复用的并发事件驱动服务器的流程如下:
- select函数检测到输入事件
- add_client函数创建新状态机
- check_clients函数执行状态转移(在课本的例题中是回送输入行),并且完成时删除该状态机。
基于线程的并发编程
- 线程:就是运行在进程上下文中的逻辑流。
- 线程由内核自动调度。每个线程都有它自己的线程上下文:
- 一个唯一的整数线程ID——TID
- 栈
- 栈指针
- 程序计数器
- 通用目的寄存器
- 条件码
进度图
- 进度图是将n个并发线程的执行模型化为一条n维笛卡尔空间中的轨迹线,原点对应于没有任何线程完成一条指令的初始状态。
-
当n=2时,状态比较简单,是比较熟悉的二维坐标图,横纵坐标各代表一个线程,而转换被表示为有向边
-
转换规则:
- 合法的转换是向右或者向上,即某一个线程中的一条指令完成
- 两条指令不能在同一时刻完成,即不允许出现对角线
- 程序不能反向运行,即不能出现向下或向左
一个程序的执行历史被模型化为状态空间中的一条轨迹线。
-
线程循环代码的分解:
- H:在循环头部的指令块
- L:加载共享变量cnt到线程i中寄存器%eax的指令。
- U:更新(增加)%eax的指令
- S:将%eax的更新值存回到共享变量cnt的指令
- T:循环尾部的指令块
-
几个概念:
- 临界区:对于线程i,操作共享变量cnt内容的指令L,U,S构成了一个关于共享变量cnt的临界区。
- 不安全区:两个临界区的交集形成的状态
- 安全轨迹线:绕开不安全区的轨迹线
实践过程
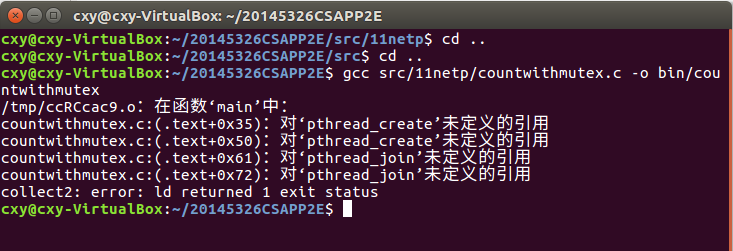
关于countwithmutex.c
- 首次编译时按照之前的方法编译,报错。根据错误提示,发现pthread库不是linux系统默认的库,因此pthread_creat创建线程时,在编译中要加上-lpthread参数。修正后顺利编译。

- 代码中涉及到的函数:
pthread_creat:创建线程,若成功则返回0,若失败则返回出错编号。第一个参数为指向线程标识符的指针,创建成功时指向的内存单元被设置为新创建线程的线程ID;第二个参数设置线程属性;第三个参数是线程运行函数的起始地址;最后一个参数是运行函数的参数
pthread_join:用来等待一个线程的结束。当函数返回时,被等待线程的资源被收回。
pthreadmutexlock:线程调用该函数让互斥锁上锁。成功锁定时返回0,其他任何返回值都表示出现了错误。
pthreadmutexunlock:与pthreadmutexlock成对存在。释放互斥锁。
- 程序首先定义了一个宏PTHREADMUTEXINITIALIZER来静态初始化互斥锁。先创建tidA线程后运行doit函数,利用互斥锁锁定资源,进行计数,执行完毕后解锁。后创建tidB,与tidA交替执行。由于定义的NLOOP值为5000,所以程序最后的输出值为10000.程序的最后还需要分别回收tidA和tidB的资源。
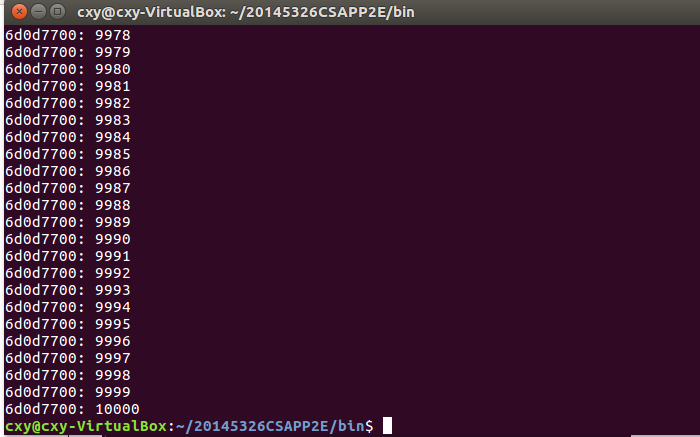
关于count.c
- 这个代码用于与countwithmutex.c进行对比,差别在于本代码doit函数的for循环中没有引入互斥锁,只进行了单纯的计数,创建两个线程共享同一变量都实现加一操作。运行结果如下。
每次运行的结果都不一样。是因为随机的覆盖吗?
关于condvar.c
- 这个代码演示的是生产者生产和消费者消费交替进行的过程。是线程间同步的一种情况。
-
主函数中用srand(time(NULL))设置当前的时间值为种子,在后面的producer和consumer函数中调用rand()函数产生随机数。
关于cp_t.c
• mmap函数
void* mmap(void* start,sizet length,int prot,int flags,int fd,offt offset);
将一个文件或者其他对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。 - 成功执行时,mmap()返回被映射区的指针,munmap()返回0.失败时,mmap()返回MAP_FAILED,munmap返回-1.
- lseek函数
-
•offt lseek(int fd,offt offset,int whence);
- fd表示要操作的文件描述符,offset是相对于whence(基准)的偏移量,whence可以是SEEK_SET(文件指针开始),SEEKCUR(文件指针当前位置),SEEKEND(文件指针尾)
-
lseek主要作用是移动文件读写指针,返回文件读写指针距文件开头的字节大小,若出错则返回-1.
-
运行如下

关于createthread.c
- 程序主要演示了创建线程函数pthread_create()函数的使用,用来打印进程和线程的ID
- 主函数中先利用pthreadcreate()函数创建一个线程,接着调用printids函数(打印标识符的函数)打印主线程号,最后线程函数thrfn中打印出新建的线程号。
关于semphore.c
- seminit函数
-
seminit(sem_t *sem, int pshared, umsigned int value);
- 函数初始化一个定位在sem的匿名信号量;pshared参数为0指明信号量是由进程内线程共享,若为非0值则信号量在进程之间共享;value参数指定信号量的初始值。
- sem_init()成功时返回0;错误时返回-1,并把errno设置为合适的值。
-
semdestroy()函数用于销毁由sem指向的匿名信号量。只有通过seminit()初始化的信号量才应该使用该函数销毁。函数成功时返回0,错误时返回-1,并把errno设置为合适的值。
-
这个函数和之前的condvar.c一样都是展示生产者和消费者交替工作的过程。区别是本程序实现生产或消费的过程是利用semwait()和sempost(),它们的作用分别是从信号量的值减去一个“1”和从信号量的值加上一个“1”
关于share.c
- 代码运行结果如下
关于threadexit.c
- 运行如下:
关于hello_multi.c
- 程序中的print_msg()函数中:在printf后的fflush(stdout);说明要立刻将要输出的内容输出,每输出一次停1秒,并循环5次。

关于hello_multi1.c
- 运行结果只输出hello99
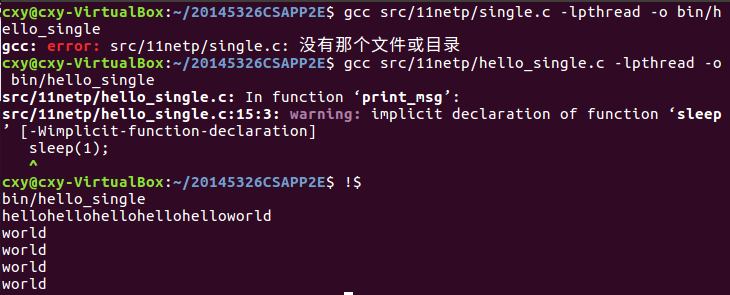
关于hello_single.c
- 根据代码,先单独执行print_msg("hello");——输出5个hello,后输出5个带换行的world
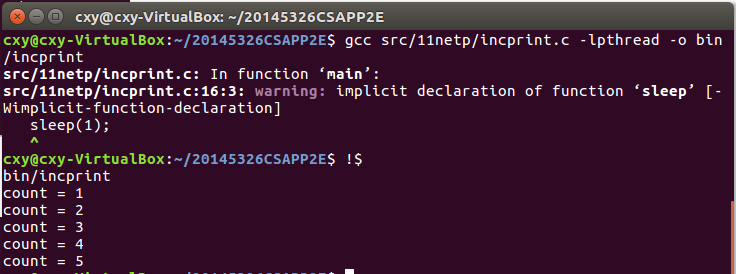
关于incprint.c
- 由于定义中NUM=5,所以输出的count为1到5。
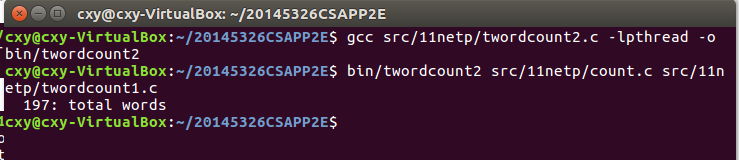
twordcount1&twordcount2
- 用法:./twordcount1 [文件1] [文件2]
- 用来统计文件1及文件2两个文件的总字数
- 运行结果:

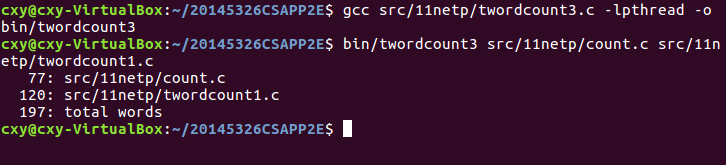
twordcount3
- 用法:./twordcount3 [文件1] [文件2]
- 分别对文件1、文件2两个文件进行字数统计,并把两个文件的字数加起来统计两个文件的总字数
- 运行结果:
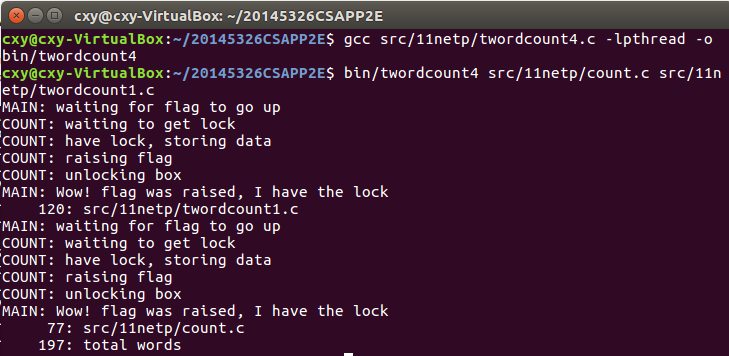
twordcount4
- 用法:./twordcount4 [文件1] [文件2]
- 分别运行代码,根据锁的情况分别统计字数,再把两个文件的字数加起来统计两个文件的总字数
- 运行结果:
代码托管
心得体会
-
本周在学习完教材上的内容后,我把老师给的代码逐一进行实践,在运行代码的过程中,由于程序中调用的一些函数都是比较生疏的,需要一个一个的去理解其中每个参数的含义和函数的返回值,所以整个过程耗费了我大量的时间,不过收获还是很大的。最初看代码的时候,只能根据程序运行的结果来大致的猜测每一句代码的含义,不过在结合课本的知识后,对其又有了进一步的深刻体会。
-
不知不觉已经上了娄老师两个学期的课了,从最开始完全排斥反抗这种教学模式,到最后将这些学习方式变为自己的习惯。我现在静静一想,才明白娄老师的良苦用心。 以写博客的方式来记录自己的学习过程,不仅锻炼了文笔还理清了思绪,说得长远一点,其实是在积累自己的人生财富!不一定只有学计算机相关知识,才能发博客,看完一本书的感想或者记录平时的心情,博客园都是一个很好的平台。平时有什么问题也可以在园子里提问,博客园里面藏龙卧虎! 我们还要学会使用git托管,虽然最开始在下载方面或者使用方面比较麻烦,但万事开头难,一旦上手,受益匪浅!比如以后电脑出现“数据流失”的话,就不用害怕了。再比如几个人要做项目的话,学会git共享代码,也会省事儿很多!学会用Markdown来编写文档,其实是强调了一种规范意识! 有的人也许会说,我以后要当公务员,跟程序员没半毛钱关系。 这句话是极其愚昧的,或者说这个同学没有领会到娄老师教学的精髓,娄老师一直强调的是什么,不是要我们学多少知识,因为知识是学不完的,也是会忘记的,娄老师要的是我们培养一种学习方法,培养一种学习习惯,培养一种思维方式,这才是会伴随我们一生的财富~
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/2 | 20/20 | |
| 第二周 | 58/58 | 1/3 | 20/40 | |
| 第三周 | 150/208 | 1/4 | 22/62 | |
| 第五周 | 150/358 | 1/5 | 21/83 | |
| 第六周 | 136/494 | 1/6 | 25/108 | |
| 第七周 | 115/609 | 2/8 | 24/132 | |
| 第八周 | 0/609 | 2/10 | 22/154 | |
| 第九周 | 109/718 | 3/13 | 20/174 | |
| 第十周 | 472/1190 | 1/14 | 21/195 | |
|
第十一周 |
1883/3073 | 3/17 | 21/216 | |
| 第十二周 | 0/3073 | 2/19 | 20/236 | |
| 第十三周 | 1023/4096 | 1/20 | 21/257 |
posted on 2016-12-11 18:56 20145326蔡馨熠 阅读(281) 评论(0) 编辑 收藏 举报

