
java架构之路-(Redis专题)Redis的高性能和持久化
上次我们简单的说了一下我们的redis的安装和使用,这次我们来说说redis为什么那么快和持久化数据
在我们现有的redis中(5.0.*之前的版本),Redis都是单线程的,那么单线程的Redis为什么还会有那么高的效率呢?因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换中性能损耗的问题,正因为Redis是单线程,所以我们要小心使用Redis指令,对于那些耗时的指令(比如keys),我们一定要谨慎使用。
在并发环境中,我们Redis的单线程并不是线程1请求了,而我们的线程2就无法继续请求了,而他的内部是采用了IO多路复用,redis利用epoli来实现IO多路复用,将连接信息和事件放在队列中,依次放到事件分派器,事件分派器将事件分发给我们的事件处理器来执行指令操作。
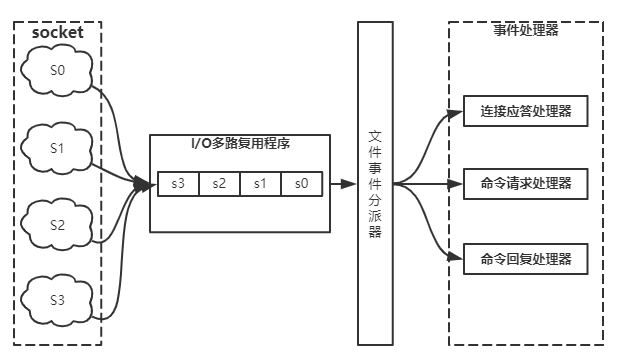
redis默认支持最大连接数是10000,我们通过设置我们的redis.conf来指定我们的最大连接数,# maxclients 10000 => maxclients 100,大致在539行,或者我们输入/maxclients 可以快速查找到我们需要改的配置,进入我们的客户端,输入$ CONFIG GET maxclients,即可查看我们的客户端最大连接数。
127.0.0.1:6379> CONFIG GET maxclients 1) "maxclients" 2) "100"
高级命令
我们输入keys *,既可以返回我们的全部键的数据,一般不推荐使用,如果数据量过大,会相当消耗性能的。
scan,scan提供了三个参数,第一个是cursor整数值,第二个是key的正则模式。第三个是第一次遍历的key的数量,并不是符合条件的结果的数量,第一次遍历时,cursor值为0,然后我们将返回结果中第一个整数作为下一次遍历的cursor。一直遍历到cursor值为0时结束。
127.0.0.1:6379> scan 0 match key* count 5 1) "6" 2) 1) "key6" 2) "key4" 3) "key1" 127.0.0.1:6379> scan 6 match key* count 5 1) "0" 2) 1) "key5" 2) "key2" 3) "key3"
Info:查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
Server 服务器运行的环境参数
Clients 客户端相关信息
Memory 服务器运行内存统计数据
Persistence 持久化信息
Stats 通用统计数据
Replication 主从复制相关信息
CPU CPU 使用情况
Cluster 集群信息
KeySpace 键值对统计数量信息
日志
redis.conf文件配置logfile来配置我们的log日志信息。大概在137行。
logfile "logForRedis.log"
Redis持久化
持久化主要分为三种,RDB,AOF和混合模式(4.0.*以后的模式)。
RDB快照模式
在默认情况下,Redis将内存数据库快照保存为*.rdb的二进制文件。我用的是5.0.5版本,默认是开启我们的RDB快照模式的,大致在253行,我们看到dbfilename dump.rdb,就是我们要以dump.rdb的文件来存储,存储位置在263行的dir ./ 也就是我们的当前路径(这里可以设置绝对路径)。
我们在大概218行可以看到三个save,也就是我们RDB的保存策略
save 900 1 //表示在900秒内,发生了一次变动,我们就生成一次快照,变动只是数据的变动,get并不算变动
save 300 10 //表示在300秒内,发生了十次变动,我们就生成一次快照
save 60 10000 //表示在60秒内,发生了一万次变动,我们就生成一次快照
三者条件满足其一就保存一次,他们之间是一个或者的关系,如果三个条件都未满足,这时宕机可能造成数据的丢失。
我们还可以通过进入redis-cli客户端以后,我们手动输入save或者bgsave来生成我们的dump.rdb文件。我们的redis服务端配置是采用bgsave的方式来保存的。我们来看一下save和bgsave的比较。
| 命令 | save | bgsave |
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函数时会有超级短暂的阻塞) |
| 时间复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
AOF命令模式
我们为什么成为AOF叫做命令模式呢?我们的AOF其实是保存了我们每一个操作的动作,也就是我们每一个Redis指令,我们只需要设置appendonly yes即可,大概在699行。下面的appendfilename是我们需要保存aof的文件名,rdb中提到的dir对应的也是aof文件的保存路径。这样的持久化,其实也不是每次都要向磁盘写入数据的,他有三个选项供我们来修改。
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
大概在728-730行设置这三种策略,默认的每秒一次,也是推荐使用的,三种策略只能选择其中一种生效。一组set testkey testvalue命令大概这样的
| *3 | 表示占了几个位置,*3表示占了三个位置,也就是*** *** *** 样式的命令 |
| $3 | 表示下面命令占位的长度 |
| set | 就是我们实际的命令 |
| $7 | 表示下一个命令占位的长度 |
| testkey | 就是我们实际的命令 |
| $9 | 表示下一个命令占位的长度 |
| testvalue | 就是我们实际的命令 |
我们假象一下输入了一百次incr article:xiaocai命令,我们现在要使用AOF来恢复我们的文件,那么指令incr article:xiaocai就要存储100次,恢复100次,貌似效率不高啊。这里就提到了我们的AOF文件重写。也就是把一些指令重新组合生成新的指令,但保证数据的准确性。我们来看一下,我们先经历三次set命令,key值是一样的,我很容易知道,这里set了三次,但前两次并没有什么卵用,最后一次将我们的值已经覆盖掉了。
127.0.0.1:6379> set xiaocai 123 OK 127.0.0.1:6379> set xiaocai 456 OK 127.0.0.1:6379> set xiaocai 666 OK 127.0.0.1:6379> BGREWRITEAOF Background append only file rewriting started 127.0.0.1:6379>
这时应该生产三条AOF指令,我们来执行我们的AOF重写命令$ BGREWRITEAOF,重写之后,前面的set就不见了,相同键的set,只保留最后一次的set。可能造成乱码(我们5.0.5默认开启了混合模式,后面会说),但是确实压缩了,恢复也是可以成功的。我们来看一下我该掉默认配置后的AOF重写文件。
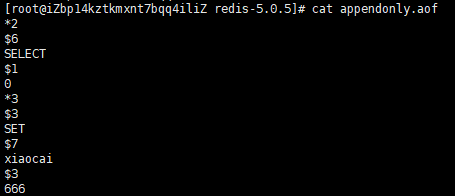
我们可以看到我们前两条指令被优化去掉了,这也就是我们的AOF重写。
auto-aof-rewrite-min-size 64mb //表示当我们的aof文件达到64M时,我们就重写一次,建议使用默认配置就可以,太多了,重写耗时长,太小了,经常重写,消耗性能。
auto-aof-rewrite-percentage 100 这个表示。//当我们的配置增加了100%我们就重写一次
说到这,两种持久化的方式就都说完了,我们来看一下谁才是王者,谁才是最优质的。
| 命令 | RDB | AOF |
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢失数据 | 根据策略决定 |
注意:当我们同时开启RDB和AOF时,当我们重启redis时,Redis会优先去加载AOF文件来恢复我们的数据,相对来说AOF的数据更完整
混合模式
重启redis时,我们很少使用RDB来恢复内存数据,因为会丢失大量的数据。通常我们使用AOF指令来恢复,但AOF的性能相比RDB要慢很多,看到这我们还是觉得并没有一种完美的解决方案,来持久化我们的数据,这时Redis4.0就引出了我们混合持久化。我们可以通过设置 # aof-use-rdb-preamble yes来开启我们的混合持久化,这时我们生成的持久化文件内部还是AOF的,但我们重写的时候,会将这些AOF的指令重写为二进制文件。这样我们就综合了RDB和AOF的优势,在恢复数据的时候大部分是执行二进制文件的,小部分来执行我们的AOF指令操作,使我们的恢复数据的效率更高,在备份的时候是以AOF来备份的,也保证了数据的安全性。
总结
这次我们主要说了我们的Redis的内存高性能,Redis在内存来计算的,再就是我们的高级设置keys *(少用或者别用)和我们的scan命令,再就是Redis的持久化,两种RDB和AOF,RDB持久化可能数据丢失,但是二进制文件恢复的快,AOF持久化几乎不会丢数据,但是是指令的模式,恢复数据效率低。由于都有缺点我们引入了混合模式,保存用AOF来存,恢复用RDB+AOF来恢复。再就是一个重点是save和bgsave的区别。记住bgsave是后台执行的,需要fork子进程,消耗内存,但是不阻塞Redis的其它线程。
今天就说这么多,下次博文我们说说我们的主从模式,哨兵模式和我们的Redis集群。


最进弄了一个公众号,小菜技术,欢迎大家的加入


