
python学习之路-爬取boss直聘的岗位信息
背景
想了解从事python相关岗位需要具备什么技能,于是就想从招聘网站上的职位需求入手,把信息获取下来后,生成词云,这样就能很直观的看出来哪些技能是python相关岗位需要具备的了。
技术概览
- scrapy
- request
- wordcloud
- jieba
- python37
- XPATH
- 正则表达式
具体内容
- 获取到上海+python的岗位页面
- 获取每页30个的岗位的职位信息
- 自动翻页获取
- 解决反爬的问题
- 生成词云
关于scrapy的介绍可以参考左边链接,我就直接开始介绍我是怎么实现的吧。
- 一
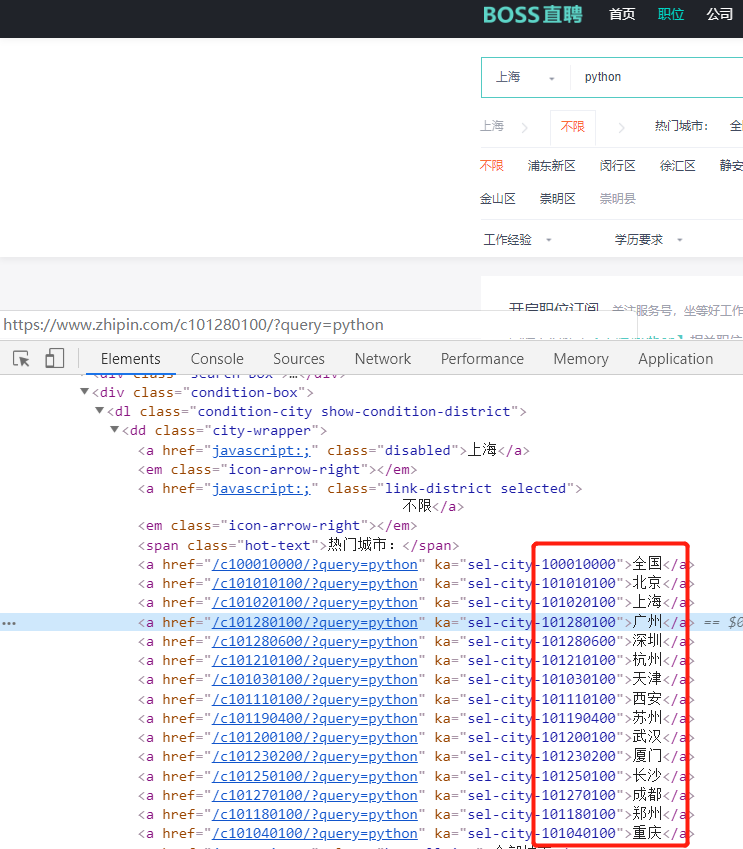
打开boss直聘的web页面,定位就是上海,输入python之后,发现url发生了变化(query的值是python,city的值是101020100)这里我们可以验证下,把query改成java后面就跳转到java相关岗位的页面,而city也是一样的,101020100是上海市的编号,其他城市的编号可以直接在web源码上获取。


- 二
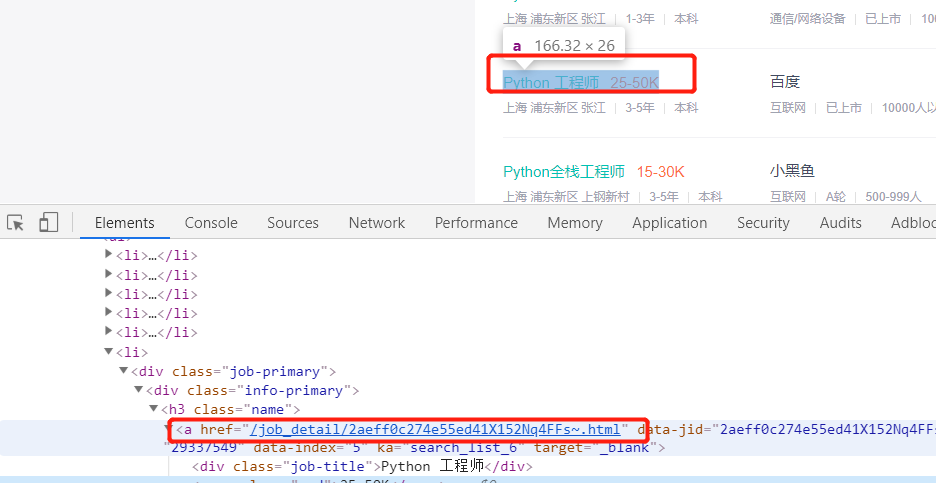
现在我们来看如何获取岗位信息,手动操作的话就是点击岗位标题即可进入详细岗位介绍的界面,打开开发者工具可以发现岗位标题这里实际上是个跳转链接,我们可以通过xpath(//[@class="name"]//@href)来获取当前页面的链接再配合正则'/job_detail.?.html'精确我们需要的链接,最后跟('https://www.zhipin.com')组合起来就是完整的url。
def parse(self, response):
job = response.xpath('//*[@class="name"]//@href').extract()
job = re.findall('/job_detail.*?.html', str(job))
print('job:{}'.format(job))
for i in range(30):
print('当前在{}项岗位'.format(i))
job_url = 'https://www.zhipin.com'+job[i]
yield scrapy.Request(url=job_url, callback=self.parse_job)
def parse_job(self, response):
item = BossItem()
item['job_desc'] = response.xpath('//*[@class="job-sec"]//div[@class="text"]/text()').extract()
yield item
- 三
翻页,手动点击翻页可以看到page信息发生了变化,page的值就是实际的页数,可以尝试修改page验证下,尤其是第一页有可能不适用这个方法,scrapy自带的start_urls列表就可以实现手动的翻页。

start_urls = ['https://www.zhipin.com/c101020100/?query=python&page=1',
'https://www.zhipin.com/c101020100/?query=python&page=2',
'https://www.zhipin.com/c101020100/?query=python&page=3',
'https://www.zhipin.com/c101020100/?query=python&page=4',
'https://www.zhipin.com/c101020100/?query=python&page=5',
'https://www.zhipin.com/c101020100/?query=python&page=6',
'https://www.zhipin.com/c101020100/?query=python&page=7',
'https://www.zhipin.com/c101020100/?query=python&page=8',
'https://www.zhipin.com/c101020100/?query=python&page=9',
'https://www.zhipin.com/c101020100/?query=python&page=10']
- 四
反爬,我是设置了随机的useragent以及ip代理。useragent可以帮助我们的爬虫伪装成普通的浏览器,而代理ip解决被服务器识别并且封ip的问题。这里不得不提一个坑,就是python37+scrapy1.7.1的环境跟旧的环境中间件的设置有变化的地方,就是request.meta['proxy']一定要改成request.meta['http_proxy'],才能用,不然就会一直各种报错(10060,10061还有就是403,302等http的状态码)。我们也可以在setting文件中设置CONCURRENT_REQUESTS(Scrapy downloader 并发请求的最大值)为1,DOWNLOAD_DELAY(下载器在下载同一个网站下一个页面前需要等待的时间)为30s,这样也可以防止我们被封ip。免费的ip代理池的话可以通过右边链接的教程获取,亲测可用。免费ip代理获取教程
class MyUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, agents):
self.agents = agents
@classmethod
def from_crawler(cls, crawler):
return cls(
agents=crawler.settings.get('USER_AGENTS')
)
def process_request(self, request, spider):
agent = random.choice(self.agents)
request.headers['User-Agent'] = agent
print('now user-agent is:' + agent)
def process_response(self,request,response,spider):
return response
class ProxyMiddleware(HttpProxyMiddleware):
'''
设置Proxy
'''
def __init__(self, ip):
self.ip = ip
@classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES'))
def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['http_proxy'] = ip
print('now ip is:'+ip)
def process_response(self,request,response,spider):
if response.status != 200:
ip = random.choice(self.ip)
request.meta['http_proxy'] = ip
print('change ip is:' + ip)
return request
return response
- 五
最后的词云生成一开始我是写在pipeline.py文件里,这样scrapy会自动在获取到数据后进行生成词云,但是我发现每获取一次生成一次也很浪费时间,还是全部获取完另外生成比较方便,这里就用到jieba分词,分完后可以通过wordcloud设置词云的大小,词汇量,背景,颜色,字体等等,有不合适的词汇设置停用词去掉即可。
class BossItem(scrapy.Item):
#写在item.py文件里
# define the fields for your item here like:
job_desc = scrapy.Field()
class BossPipeline(object):
#写在pipeline.py文件里
def process_item(self, item, spider):
text = ''.join(item['job_desc'])
d = path.dirname(__file__)
with open(path.join(d, 'zhipin.txt'), 'a', encoding='utf-8') as f:
f.write(text)
return item
# encoding:utf-8
from os import path
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import jieba
#词云制作
d = path.dirname(__file__)
text = open(path.join(d, 'zhipin.txt'),encoding='utf-8').read()
stopwords = [line.strip() for line in open(path.join(d, 'ban.txt'), 'r').readlines()]
wordlist = jieba.cut(text)
outstr = ''
for word in wordlist:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
wordcloud = WordCloud(width=1000, height=1000, font_path='HYQiHeiY4-95W.otf').generate(outstr)
wordcloud.to_file(path.join(d,"cloud_word.png"))
总结
以上就是我使用scrapy框架的Spider来爬取BOSS直聘上职位信息的具体实现方式,其实一开始我想要爬不同地区的python相关的岗位,但是这样一来就不能简单的通过start_urls列表来实现翻页,因为不同地区的页数不固定,得先获取到总页码,这里就涉及到:不同地区的url队列、同一个地区的不同页面的url队列、同地区同页面的不同岗位的url队列,因此简单的Spider无法实现,需要用到CrawlSpider,这里我就先写了简单版的,有机会再学习下CrawlSpider。这里生成的词云好像也没有什么特别的参考价值,大家还是找一找自己心仪的岗位有针对性的去学习吧哈哈哈。源码的话可以去我的github获取。

