

Mysql加锁过程详解(4)-select for update/lock in share mode 对事务并发性影响
事务并发性理解
事务并发性,粗略的理解就是单位时间内能够执行的事务数量,常见的单位是 TPS( transactions per second).
那在数据量和业务操作量一定的情况下,常见的提高事务并发性主要考虑的有哪几点呢?
1.提高服务器的处理能力,让事务的处理时间变短。
这样不仅加快了这个事务的执行时间,也降低了其他等待该事务执行的事务执行时间。
2.尽量将事务涉及到的 sql 操作语句控制在合理范围,换句话说就是不要让一个事务包含的操作太多或者太少。
在业务繁忙情况下,如果单个事务操作的表或者行数据太多,其他的事务可能都在等待该事务 commit或者 rollback,这样会导致整体上的 TPS 降低。但是,如果每个 sql 语句都是一个事务也是不太现实的。一来,有些业务本身需要多个sql语句来构成一个事务(比如汇款这种多个表的操作);二来,每个 sql 都需要commit,如果在 mysql 里 innodb_flush_log_at_trx_commit=1 的情况下,会导致 redo log 的刷新过于频繁,也不利于整体事务数量的提高(IO限制也是需要考虑的重要因素)。
3.在操作的时候,尽量控制锁的粒度,能用小的锁粒度就尽量用锁的粒度,用完锁资源后要记得立即释放,避免后面的事务等待。
但是有些情况下,由于业务需要,或者为了保证数据的一致性的时候,必须要增加锁的粒度,这个时候就是下面所说的几种情况。
select for update 理解
select col from t where where_clause for update 的目的是在执行这个 select 查询语句的时候,会将对应的索引访问条目进行上排他锁(X 锁),也就是说这个语句对应的锁就相当于update带来的效果。
那这种语法为什么会存在呢?肯定是有需要这种方式的存在啦!!请看下面的案例描述:
案例1:
前提条件:
mysql 隔离级别 repeatable-read ,
事务1:
建表: CREATE TABLE `lockt` ( `id` int(11) NOT NULL, `col1` int(11) DEFAULT NULL, `col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `col1_ind` (`col1`), KEY `col2_ind` (`col2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 插入数据 。。。。。 mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
然后另外一个事务2 进行了下面的操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2= 144 where col2=14; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)
结果:可以看到事务2 将col2=14 的列改为了 col2=144.
可是事务1继续执行的时候根本没有觉察到 lockt 发生了变化,请看 事务1 继续后面的操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.01 sec) mysql> update lockt set col2=col2*2 where col2=14; Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
结果: 事务1 明明查看到的存在 col2=12 的行数据,可是 update 后,竟然不仅没有改为他想要的col2=28 的值,反而变成了 col2=144 !!!!
这在有些业务情况下是不允许的,因为有些业务希望我通过 select * from lockt; 查询到的数据是此时数据库里面真正存储的最新数据,并且不允许其他的事务来修改只允许我来修改。(这个要求很霸气,但是我喜欢。。)
这种情况就是很牛逼的情况了。具体的细节请参考下面的案例2:
案例2:
mysql 条件和案例1 一样。
事务1操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt where col2=20 for update; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事务2 操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2=222 where col2=20;
注意: 事务2 在执行 update lockt set col2=222 where col2=20; 的时候,会发现 sql 语句被 block住了,为什么会发现这种情况呢?
因为事务1 的 select * from lockt where col2=20 for update; 语句会将 col2=20 这个索引的入口给锁住了,(其实有些时候是范围的索引条目也被锁住了,暂时不讨论。),那么事务2虽然看到了所有的数据,但是想去修改 col2=20 的行数据的时候, 事务1 只能说 “不可能也不允许”。
后面只有事务1 commit或者rollback 以后,事务2 的才能够修改 col2=20 的这个行数据。
总结:
这就是 select for update 的使用场景,为了避免自己看到的数据并不是数据库存储的最新数据并且看到的数据只能由自己修改,需要用 for update 来限制。
如果看了前面的 select *** for update ,就可以很好的理解 select lock in share mode ,in share mode 子句的作用就是将查找到的数据加上一个 share 锁,这个就是表示其他的事务只能对这些数据进行简单的select 操作,并不能够进行 DML 操作。
那它和 for update 在引用场景上究竟有什么实质上的区别呢?
lock in share mode 没有 for update 那么霸道,所以它有时候也会遇到问题,请看案例3
案例3:
mysql 环境和案例1 类似
事务1:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事务2 接着开始操作
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.01 sec)
后面的比较蛋疼的一幕出现了,当 事务1 想更新 col2=20 的时候,他发现 block 住了。
mysql> update lockt set col2=22 where col2=20;
解释:因为事务1 和事务2 都对该行上了一个 share 锁,事务1 以为就只有自己一个人上了 S 锁,所以当事务一想修改的时候发现没法修改,这种情况下,事务1 需要使用 for update 子句来进行约束了,而不是使用 for share 来使用。
意向锁作用
下文之知乎大神观点:https://www.zhihu.com/question/51513268
innodb的意向锁有什么作用?
mysql官网上对于意向锁的解释中有这么一句话
“The main purpose of IX and IS locks is to show that someone is locking a row, or going to lock a row in the table.”
意思是说加意向锁的目的是为了表明某个事务正在锁定一行或者将要锁定一行。
那么,意向锁的作用就是“表明”加锁的意图,可是为什么要表明这个 意图呢?
如果仅仅锁定一行仅仅需要加一个锁,那么就直接加锁就好了,这里要表明加锁意图的原因是因为要锁定一行不仅仅是要加一个锁,而是要做一系列操作吗?
作者:尹发条地精
我最近也在看这个,我说一下我的理解
①在mysql中有表锁,LOCK TABLE my_tabl_name READ; 用读锁锁表,会阻塞其他事务修改表数据。LOCK TABLE my_table_name WRITe; 用写锁锁表,会阻塞其他事务读和写。
②Innodb引擎又支持行锁,行锁分为共享锁,一个事务对一行的共享只读锁。排它锁,一个事务对一行的排他读写锁。
③这两中类型的锁共存的问题考虑这个例子:
事务A锁住了表中的一行,让这一行只能读,不能写。之后,事务B申请整个表的写锁。如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。
数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。
数据库要怎么判断这个冲突呢?
step1:判断表是否已被其他事务用表锁锁表
step2:判断表中的每一行是否已被行锁锁住。
注意step2,这样的判断方法效率实在不高,因为需要遍历整个表。
于是就有了意向锁。在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。在意向锁存在的情况下,
上面的判断可以改成
step1:不变
step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。
注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请。
总结:为了实现多粒度锁机制(白话:为了表锁和行锁都能用)
可能用到的情景和对性能的影响
使用情景:
1. select *** for update 的使用场景
为了让自己查到的数据确保是最新数据,并且查到后的数据只允许自己来修改的时候,需要用到 for update 子句。
2. select *** lock in share mode 使用场景
为了确保自己查到的数据没有被其他的事务正在修改,也就是说确保查到的数据是最新的数据,并且不允许其他人来修改数据。但是自己不一定能够修改数据(比如a,b都拿了锁,a更改了数据,因为b还拿着锁,a提交不了,直到超时),因为有可能其他的事务也对这些数据 使用了 in share mode 的方式上了 S 锁。
性能影响:
select for update 语句,相当于一个 update 语句。在业务繁忙的情况下,如果事务没有及时的commit或者rollback 可能会造成其他事务长时间的等待,从而影响数据库的并发使用效率。
select lock in share mode 语句是一个给查找的数据上一个共享锁(S 锁)的功能,它允许其他的事务也对该数据上 S锁,但是不能够允许对该数据进行修改。如果不及时的commit 或者rollback 也可能会造成大量的事务等待。
for update 和 lock in share mode 的区别:前一个上的是排他锁(X 锁),一旦一个事务获取了这个锁,其他的事务是没法在这些数据上执行 for update ;后一个是共享锁,多个事务可以同时的对相同数据执行 lock in share mode。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
例子实验
1.lock in share mode死锁情况
|
a |
b |
|
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
SET AUTOCOMMIT=0; |
|
|
|
|
|
BEGIN |
BEGIN |
|
SELECT * FROM test |
SELECT * FROM test |
|
|
|
SELECT * FROM test WHERE a='1' LOCK IN SHARE MODE; |
SELECT * FROM test WHERE a='1' LOCK IN SHARE MODE; |
|
|
|
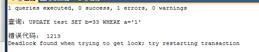
UPDATE test SET b=111 WHERE a='1'
|
|
|
|
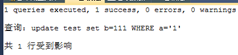
UPDATE test SET b=222 WHERE a='1' |
|
|
|
|
B死锁了,释放掉了s锁,所以a就成功了 |
|
|
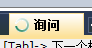
UPDATE test SET b=222 WHERE a='1' |
|
|
|
|
COMMIT |
|
|
|
A提交后B才更新成功,因为死锁后B丢了锁,A才成功
|
|
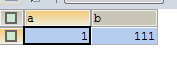
SELECT * FROM test |
|
|
|
|
|
SELECT * FROM test |
|
|
|
|
|
COMMIT |
|
SELECT * FROM test |
SELECT * FROM test |
|
|
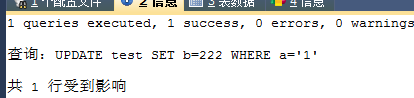
例子2 for update锁
|
a |
b |
|
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
SET AUTOCOMMIT=0; |
|
|
|
|
|
BEGIN |
BEGIN |
|
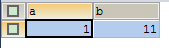
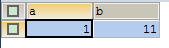
SELECT * FROM test |
SELECT * FROM test |
|
|
|
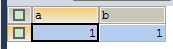
SELECT * FROM test WHERE a='1' FOR UPDATE; |
|
|
SELECT * FROM test WHERE a='1' FOR UPDATE; |
|
|
|
|
COMMIT |
COMMIT |
|
ForUpdate只能一个人拿到锁,是x(排他)锁 |
|
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参考:http://www.cnblogs.com/liushuiwuqing/p/3966898.html

