
熟练掌握HDFS的Shell访问
HDFS设计的主要目的是对海量数据进行存储,也就是说在其上能够存储很大量文件(可以存储TB级的文件)。HDFS将这些文件分割之后,存储在不同的DataNode上, HDFS 提供了两种访问接口:Shell接口和Java API 接口,对HDFS里面的文件进行操作,具体每个Block放在哪台DataNode上面,对于开发者来说是透明的。
下面将介绍通过Shell接口对HDFS进行操作,HDFS处理文件的命令和Linux命令基本相同,这里区分大小写
目录
下面列举出几个常用场景下的命令
- 创建文件夹
HDFS上的文件目录结构类似Linux,根目录使用"/"表示。
下面的命令将在/middle(已存在)目录下建立目录weibo
[hadoop@ljc hadoop]$ hadoop fs -mkdir /middle/weibo
效果如下:

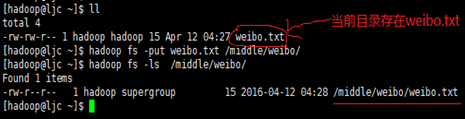
- 上传文件weibo.txt到weibo目录下
[hadoop@ljc ~]$ hadoop fs -put weibo.txt /middle/weibo/
效果如下:
还可以使用 -copyFromLocal参数。
[hadoop@ljc ~]$ hadoop fs -copyFromLocal weibo.txt /middle/weibo/
- 查看weibo.txt文件内容。
[hadoop@ljc ~]$ hadoop fs -text /middle/weibo/weibo.txt
效果如下:

还可以用 -cat、-tail 参数查看文件的内容。但是对于压缩的结果文件只能用 -text 参数来查看,否则是乱码。
[hadoop@ljc ~]$ hadoop fs -cat /middle/weibo/weibo.txt
[hadoop@ljc ~]$ hadoop fs -tail /middle/weibo/weibo.txt
- 通过终端向"/middle/weibo/weibo.txt"中输入内容
[hadoop@ljc ~]$ hadoop fs -appendToFile - /middle/weibo/weibo.txt
如下所示:

退出终端输入,按Ctrl + C
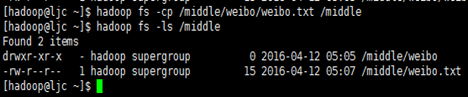
- 把"/middle/weibo/weibo.txt"复制到"/middle"
[hadoop@ljc ~]$ hadoop fs -cp /middle/weibo/weibo.txt /middle
效果如下:
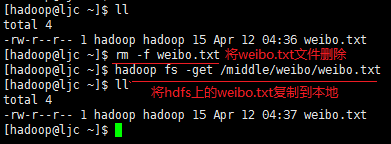
- 把weibo.txt文件复制到本地。
[hadoop@ljc ~]$ hadoop fs -get /middle/weibo/weibo.txt
效果如下:
还可以用 -copyToLocal 参数。
[hadoop@ljc ~]$ hadoop fs -copyToLocal /middle/weibo/weibo.txt
- 删除weibo.txt文件。
[hadoop@ljc ~]$ hadoop fs -rm /middle/weibo/weibo.txt
效果如下:

- 删除/middle/weibo文件夹。
[hadoop@ljc ~]$ hadoop fs -rm -r /middle/weibo
效果如下:

- 显示 /middle 目录下的文件。
[hadoop@ljc ~]$ hadoop fs -ls /middle
效果如下:

上面我们介绍的是访问单个HDFS集群,但是多个Hadoop集群需要复制数据该怎么办呢?幸运的是,Hadoop 有一个有用的distcp分布式复制程序,该程序是由 MapReduce作业来实现的,它是通过集群中并行运行的map来完成集群之间大量数据的复制。下面我们将介绍 distcp在不同场景下该如何使用
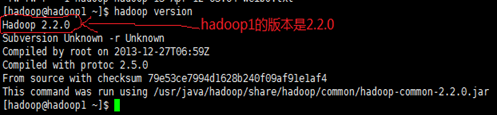
- 两个集群运行相同版本的Hadoop
确保两个集群版本相同,这里以hadoop1、hadoop2集群为例,如下所示
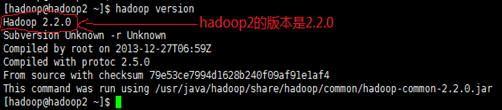
1)、两个 HDFS 集群之间传输数据,默认情况下 distcp 会跳过目标路径下已经存在的文件
[hadoop@hadoop1 ~]$ hadoop distcp /weather hdfs://hadoop2:9000/middle
效果如下:
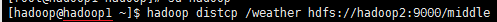
这条指令是在hadoop1中执行,意思是把/weather目录及其内容复制到hadoop2集群的/middle目录下,所以hadoop2集群最后的目录结构为/middle/weather
如下所示

如果/middle 不存在,则新建一个。也可以指定多个源路径,并把所有路径都复制到目标路径下。
这里的目标路径(hadoop2)必须是绝对路径,源路径(hadoop1)可以是绝对路径,也可以是相对路径,因为我是在hadoop1中执行的,且默认是HDFS协议
在执行这条指令时可能会报错
如下所示
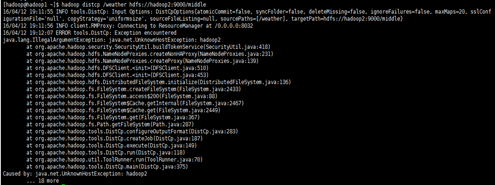
这是因为没有把hadoop2(hadoop2对应IP:192.168.233.130)追加到/etc/hosts文件中,如下所示

如果指令在hadoop2中执行,可以这样写,如下
[hadoop@hadoop2 ~]$ hadoop distcp hdfs://hadoop1:9000/weather /middle
效果如下:
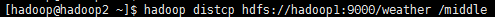
这时,源路径就必须写绝对路径,目录路径可以是绝对路径,也可以是相对路径,因为我是在hadoop2中执行的,且默认是HDFS协议,如果报错,请参考上面
2)、两个 HDFS 集群之间传输数据,覆盖现有的文件使用overwrite
[hadoop@hadoop1 ~]$ hadoop distcp -overwrite /weather hdfs://hadoop2:9000/middle/weather
如下所示

注意,在overwrite时,只是将/weather中的内容覆盖到"hdfs://hadoop2:9000/middle/weather"中,不包含/weather目录本身,所以在overwrite时,目录路径加上了/weather
3)、两个 HDFS 集群之间传输数据,更新有改动过的文件使用update。
[hadoop@hadoop1 ~]$ hadoop distcp -update /weather hdfs://hadoop2:9000/middle/weather
效果如下:

注意,在update时,只是将/weather中的内容覆盖到"hdfs://hadoop2:9000/middle/weather"中,不包含/weather目录本身,所以在update时,目录路径加上了/weather
- 两个集群运行不同版本的Hadoop
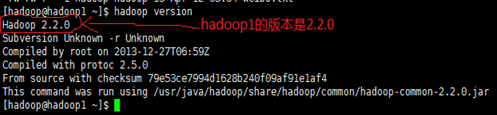
不同版本Hadoop集群的RPC是不兼容的,使用distcp复制数据并使用hdfs协议,会导致复制作业失败。想要弥补这种情况,可以在下面两种方式选择一种;下面以hadoop1、hadoop3两个集群为例,版本如下

1)、基于hftp实现两个HDFS集群之间传输数据
[hadoop@hadoop3 ~]$ hadoop distcp hftp://hadoop1:50070/weather /middle
如下所示
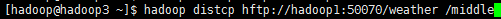
有三点需要说明:
1、这个命令必须运行在目标集群上,进而实现hdfs RPC版本的兼容
2、hftp地址由dfs.http.address属性决定的,其端口默认值为50070
3、该命令是将hftp://hadoop1:9000/weather中内容传输到/middle目录中,不包含/middle目录本身
2)、基于webhdfs实现两个HDFS集群之间传输数据
如果使用新出的webhdfs协议(替代 hftp)后,对源集群和目标集群均可以使用 HTTP协议进行通信,且不会造成任何不兼容的问题
[hadoop@hadoop3 ~]$ hadoop distcp webhdfs://hadoop1:50070/weather webhdfs://hadoop3:50070/middle
如下所示

掌握了 shell 如何访问 HDFS,作为 Hadoop 管理员,还需要掌握如下常见命令
- 查看正在运行的Job。
[hadoop@hadoop1 ~]$ hadoop job –list
如下所示

- 关闭正在运行的Job
[hadoop@hadoop1 ~]$ hadoop job -kill job_1432108212572_0001
如下所示

- 检查 HDFS 块状态,查看是否损坏。
[hadoop@hadoop1 ~]$ hadoop fsck /
- 检查 HDFS 块状态,并删除损坏的块。
[hadoop@hadoop1 ~]$ hadoop fsck / -delete
- 检查 HDFS 状态,包括 DataNode 信息。
[hadoop@hadoop1 ~]$ hadoop dfsadmin -report
- Hadoop 进入安全模式。
[hadoop@hadoop1 ~]$ hadoop dfsadmin -safemode enter
如下所示

- Hadoop 离开安全模式。
[hadoop@hadoop1 ~]$ hadoop dfsadmin -safemode leave
如下所示

- 平衡集群中的文件
[hadoop@hadoop1 ~]$ /usr/java/hadoop/sbin/start-balancer.sh
start-balancer.sh命令位于hadoop安装路径下的/sbin下
如下所示

文档链接:下载
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【刘超★ljc】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号