
爬虫项目设计文档
一、引言
1.1 目的
描述程序设计。
1.2 总体设计概述
提供网页爬取、内容分类、内容下载、图形分析等设计。
二、整体架构
2.1 应用技术
2.1.1 JAVA多线程
JAVA使用java.lang.Thread类或者java.lang.Runnable接口编写代码来定义、实例化和启动新线程。Java中,每个线程都有一个调用栈,即使不在程序中创建任何新的线程,线程也在后台运行着。一个Java应用总是从main()方法开始运行,mian()方法运行在一个线程内,它被称为主线程。一旦创建一个新的线程,就产生一个新的调用栈。线程的应用大大提高了JAVA程序的效率。
2.1.2 URL去重 -- 基于hash算法的存储
对每一个给定的URL,都是用一个已经建立好的Hash函数,映射到某个物理地址上。当需要进行检测URL是否重复的时候,只需要将这个URL进行Hash映射,如果得到的地址已经存在,说明已经被下载过,放弃下载,否则,将该URL及其Hash地址作为键值对存放到Hash表中。这样,URL去重存储库就是要维护一个Hash表,如果Hash函数设计的不好,在进行映射的时候,发生碰撞的几率很大,则再进行碰撞的处理也非常复杂。而且,这里使用的是URL作为键,URL字符串也占用了很大的存储空间。
2.1.3 爬虫策略 -- 广度优先搜索
广度优先策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先搜索策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
2.1.4 UI设计 -- Jframe
JFrame是java的GUI程序的基础,它是屏幕上window的对象,能够最大化、最小化、关闭。Swing 的三个基本构造块:标签、按钮和文本字段;但是需要个地方安放它们,并希望用户知道如何处理它们。JFrame 类就是解决这个问题的——它是一个容器,允许程序员把其他组件添加到它里面,把它们组织起来,并把它们呈现给用户。 JFrame 实际上不仅仅让程序员把组件放入其中并呈现给用户。比起它表面上的简单性,它实际上是 Swing 包中最复杂的组件。为了最大程度地简化组件,在独立于操作系统的 Swing 组件与实际运行这些组件的操作系统之间,JFrame 起着桥梁的作用。JFrame 在本机操作系统中是以窗口的形式注册的,这么做之后,就可以得到许多熟悉的操作系统窗口的特性:最小化/最大化、改变大小、移动。
2.2整体框架视图
2.2.1物理设计框架
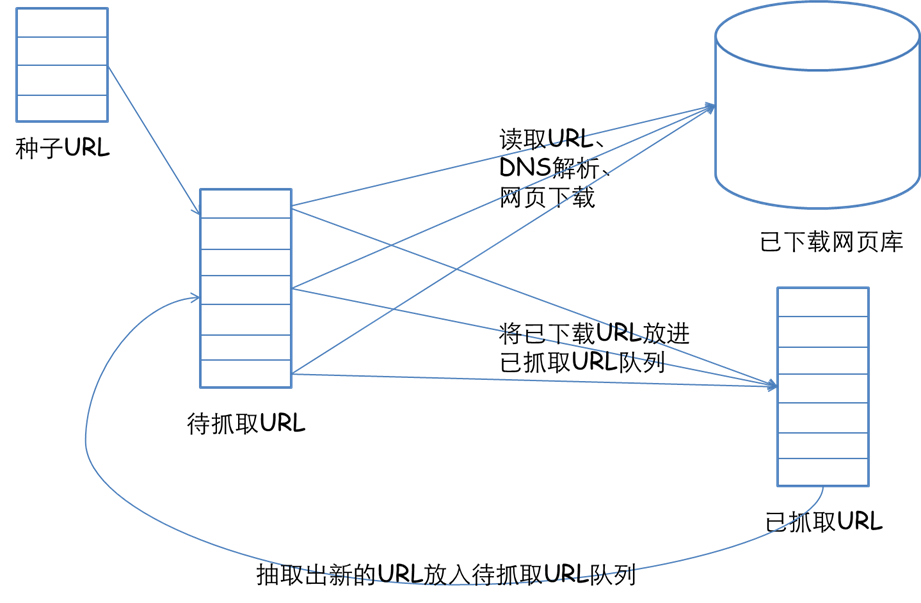
2.2.2程序设计框架
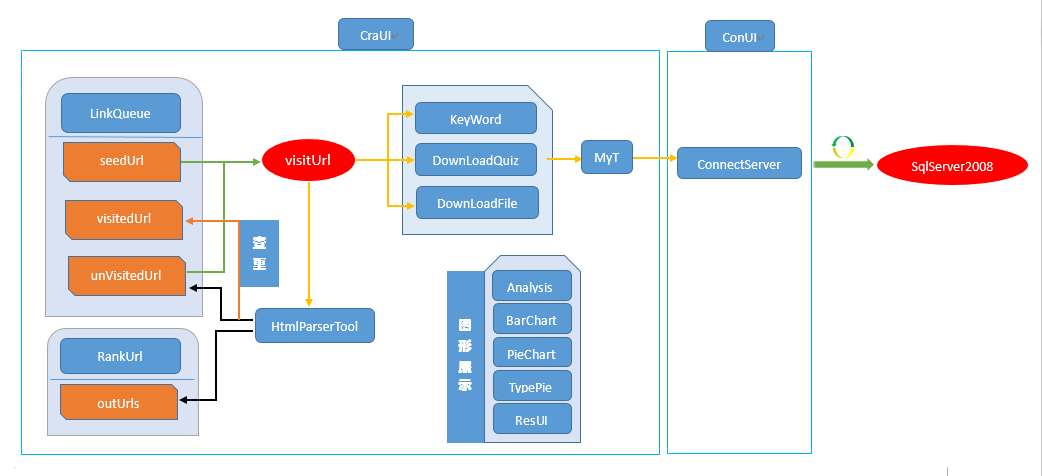
2.3 工作过程设计
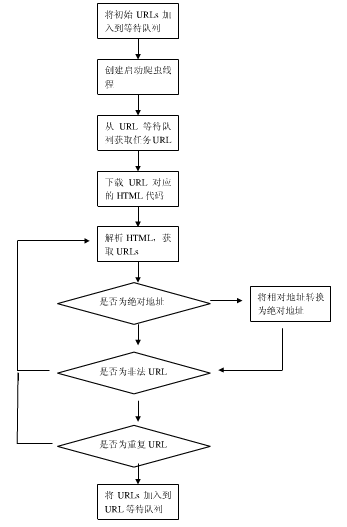
根据我们的两个视图,可以进一步设计出爬虫的如下工作方式:
①将给定的初始URL加入到URL等待队列。
②创建爬虫线程,启动爬虫线程
③每个爬虫线程从URL等待队列中取得任务URL。然后根据URL下载网页,然后解析网页,获取超链接URs。如果获取到的URL为相对地址,需要转换为绝对地址,然后淘汰外URLs,错误URLs或者不能解析的URL地址。再判断这些URL是否已经被下载到,如果没有则加入到URL等待队列。
④继续执行步骤③,直到结束条件停止。
如下是我们的工作流程图:
2.4 代码框架规范
crawler项目整体上分为url操作、服务器连接和数据库操作、内容下载、图形展示、UI设计五个部分。
(1)URL操作
URL存取:
public class LinkQueue:
//已访问的 url 集合
private static Set<RankUrl> visitedUrl = new HashSet<RankUrl>();
//已访问的 url 集合(.html)
private static Set<RankUrl> visitedHUrl = new HashSet<RankUrl>();
//待访问的 url 集合
private static ConcurrentLinkedQueue<RankUrl> unVisitedUrl = new ConcurrentLinkedQueue<RankUrl>();
//seed url集合
private static Queue<RankUrl> seedUrls = new LinkedList<RankUrl>();
//tag 集合
private static Hashtable<String, String> tagtext= new Hashtable<String, String>();
//Url得分表
private static Hashtable<RankUrl, Double> urlsScoreTable = new Hashtable<RankUrl, Double>();
//前十链接
private static ArrayList<String> topUrlsSort = new ArrayList<String>();
//获得tag表
public static Hashtable<String, String> getTagtext();
//添加到访问过的URL队列中
public static void addVisitedUrl(RankUrl url);
//添加种子链接
public static void addSeedUrl(RankUrl url);
//未访问的URL出队列
public static Object unVisitedUrlDeQueue();
//保证每个 url 只被访问一次
public static void addUnvisitedUrl(RankUrl url, RankUrl inUrl);
//获得已经访问的URL数目
public static int getVisitedUrlNum();
//判断未访问的URL队列中是否为空
public static boolean unVisitedUrlsEmpty();
//使用PageRank算法计算Url的重要性排序
public static void getUrlsScores();
//获得排序top10以内的Url和分数
public static Hashtable<String, Double> getTopRankUrls();
URL评分:
public class RankUrl :
//获取网址URL
public String getUrl();
//得到网址排名集合
public Set<RankUrl> getOutUrls();
//添加网址排名
public void addOutUrl(RankUrl url);
//得到网址排名集合的大小
public int getOutUrlsSize();
//返回网址数量
public int getOutUrlsSize();
//输出已访问url
public void print();
子链接操作:
public class HtmlParserTool:
//过滤并获取网站子链接
public static Set<String> extracLinks(String url, LinkFilter filter);
//过滤并获取网站子链接
public static Set<String> extracLinks_gb(String url, LinkFilter filter);
关键词过滤:
public class Keyword:
//根据提供的URL,获取此URL对应网页的纯文本信息
public static String getText(String url);
//给出指定URL是否符合过滤条件
public static boolean accept(String url);
主函数入口:
public class MyCrawler:
//使用种子初始化 URL队列
private void initCrawlerWithSeeds(String[] seeds);
//开始抓取pdf过程
public void pdfCrawling(String[] seeds);
//开始抓取ppt过程
public void pptCrawling(String[] seeds);
//开始抓取doc过程
public void docCrawling(String[] seeds);
//开始抓取stackoverflow页面过程
public void STCrawling(String[] STseeds);
//开始抓取q.cnblogs页面过程
public void CNCrawling(String[] CNseeds);
//开始抓取dwen页面过程
public void DWCrawling(String[] DWseeds);
//开始抓取zhidao.baidu页面过程
public void BZCrawling();
(2)服务器连接和数据库操作
public class ConnectServer:
//初始化数据库连接
public static void dbConn();
//断开数据库连接
public static void dbClose();
//执行sql查询
public static ResultSet dataset(String sql);
//得到全部网页个数
public static String getSum_webpage();
//得到全部问答页个数
public static String getSum_quiz();
//得到全部doc个数
public static String getSum_doc();
//得到全部ppt个数
public static String getSum_ppt();
//得到全部pdf个数
public static String getSum_pdf();
//互斥更新数据库
public static synchronized int update(String sql) throws SQLException;
//获取数据库最大ID号
public static int idNumber();
(3)内容下载
public class DownloadFile:
//构造函数
public DownloadFile(RankUrl url,LinkFilter filter);
//开始下载
public void run();
//通过ID获得文件名
public String getFileNameByID(int _id,String contentType);
//通过网址得到文件名
public String getFileNameByUrl(String url,String contentType)
//更新数据库
public void DataBase(String IntoDataBase,String FilePath) throws SQLException;
//保存网页字节数组到本地
private void saveToLocal(byte[] data, String filePath);
public class DownloadQuiz extends Thread:
//构造函数
public DownloadQuiz (RankUrl url,int kind);
//开始下载问答页
public void run();
//更新数据库
public void DataBase(String IntoDataBase,String FilePath) throws SQLException;
//通过ID获得文件名
public String getFileNameByID(int _id,String contentType);
//通过网址得到文件名
public String getFileNameByUrl(String url,String contentType);
//保存网页字节数组到本地
private void saveToLocal(byte[] data, String filePath);
(4)图形展示
饼状图:
public class Analysis extends JFrame:
//构造函数,设计饼状图
Analysis();
public class PieChart:
//构造函数,设计饼状图
public PieChart();
//得到pdf,quiz,webpage的数据集
private static DefaultPieDataset getDataSet();
//获取饼状图
public ChartPanel getChartPanel();
柱状图:
public class BarChart:
//构造函数,设计柱状图
BarChart();
(5)UI设计
主界面:
public class CraUi extends JFrame implements ActionListener, Runnable, ItemListener:
//构造函数,设计UI布局
public CraUi();
//根据给定的数据创建图表
public JFreeChart createChart(CategoryDataset dataset);
//创建供图表显示的面板
public JPanel createPanel();
//刷新面板
public static void updatePanel(int visited,int succeed,int failed,int passed);
//配置事件监听器动作
public void actionPerformed(ActionEvent e);
//在指定位置插入已访问URL
public void UIinsertURLs(String newURL);
//UI开始运行
public void run();
//配置下拉框状态改变响应触发
public void itemStateChanged(ItemEvent e);
//得到关键字
public String getTxt();
//设置关键字
public void setTxt(String txt);
团队LOGO:
public class Logo extends JWindow implements Runnable:
//构造函数,设置Logo参数
public Logo(String name);
//显示Logo
public void run();
//使Logo消失
public void setNotVisible();
三、软件支持
| 类型 | 软件 |
| 服务器 | 由老师提供 |
| 数据库 | sql server2008 |
| 开发平台 | Eclipce |
四、其他设计
4.1 异常处理
由于数据的保存涉及到了数据库,所以异常处理主要涉及的是SQLException,在需要操作到数据库的方法里,都抛出了SQLException,捕获然后给相应提示信息。还有其他基本异常处理不一一罗列。
4.2 用户性能设计
通过三个设计提高软件的性能:
(1)hash存储
(2)java多线程
(3)pagerank算法
高效率运行的软件有利于提高用户的体验指数。

