
大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接
Hive的工作原理简单来说就是一个查询引擎
先来一张Hive的架构图:
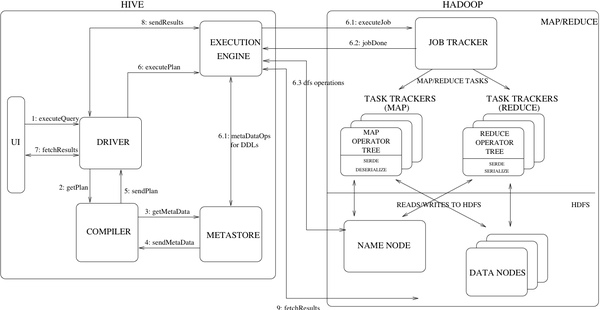
Hive的工作原理如下:
接收到一个sql,后面做的事情包括:
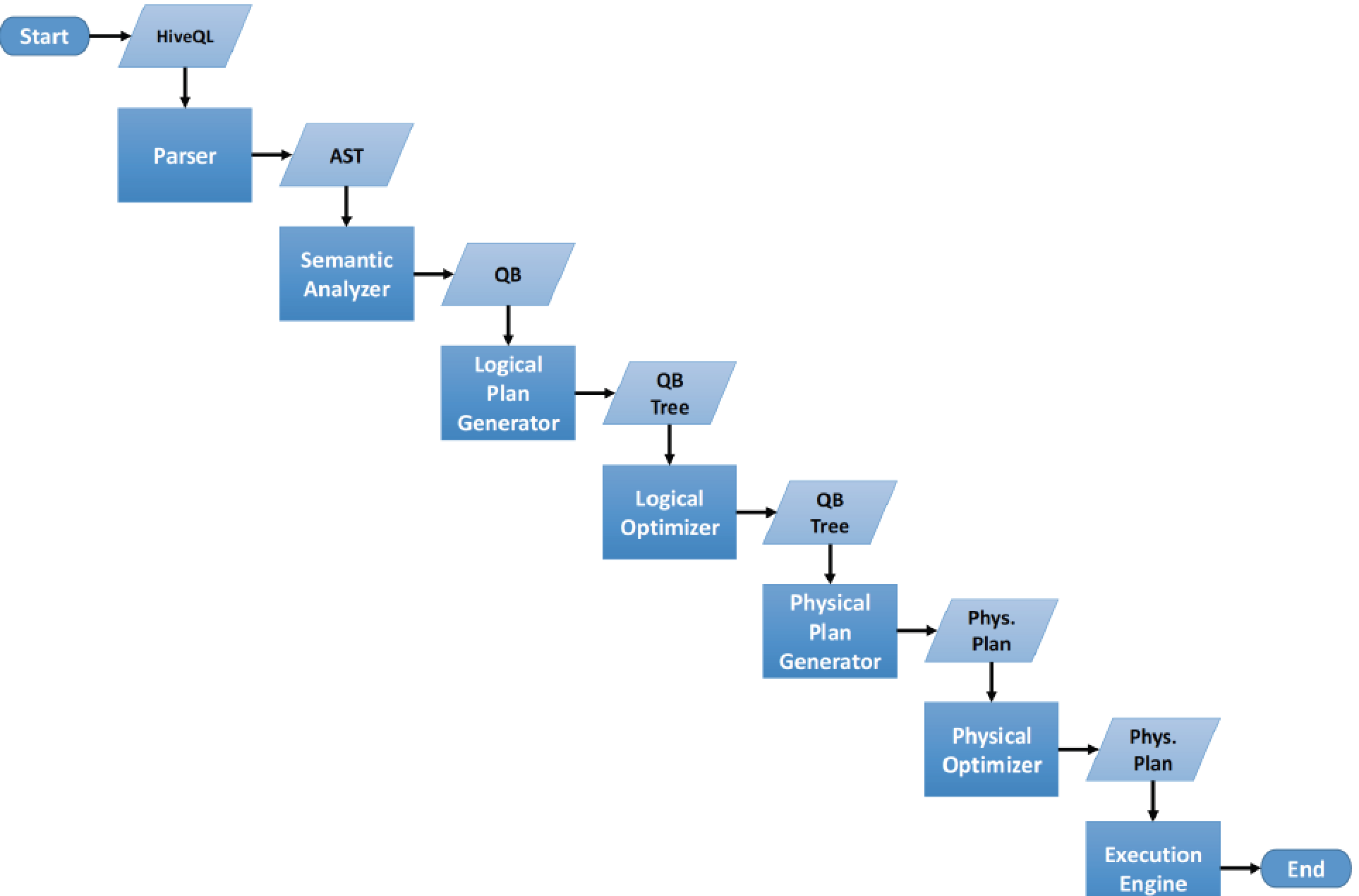
1.词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产
生成逻辑计划-算子树
4.逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成
将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行
将DAG发送到Hadoop集群进行执行
7.将查询结果返回
流程如下图:
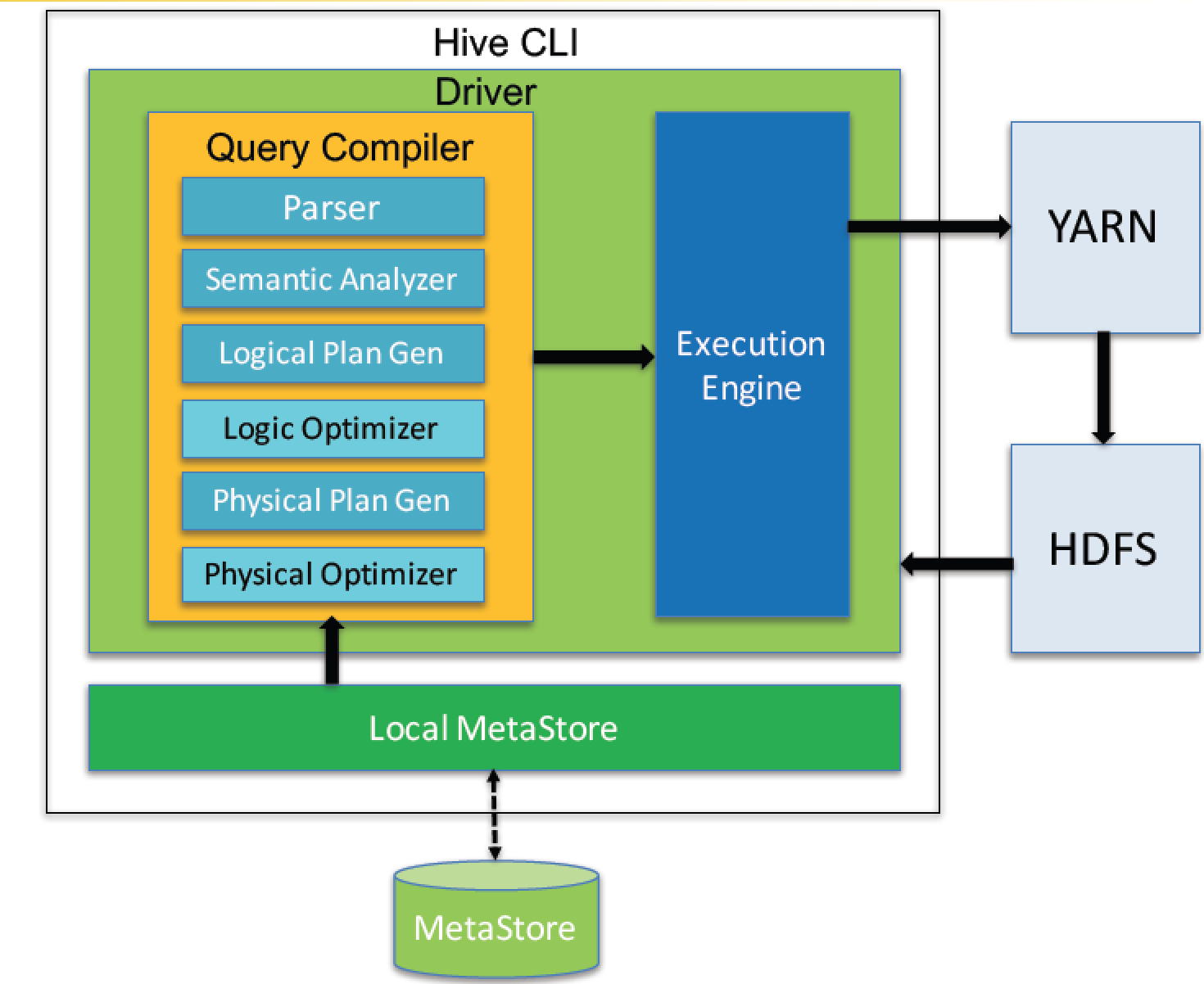
Query Compiler
新版本的Hive也支持使用Tez或Spark作为执行引擎。
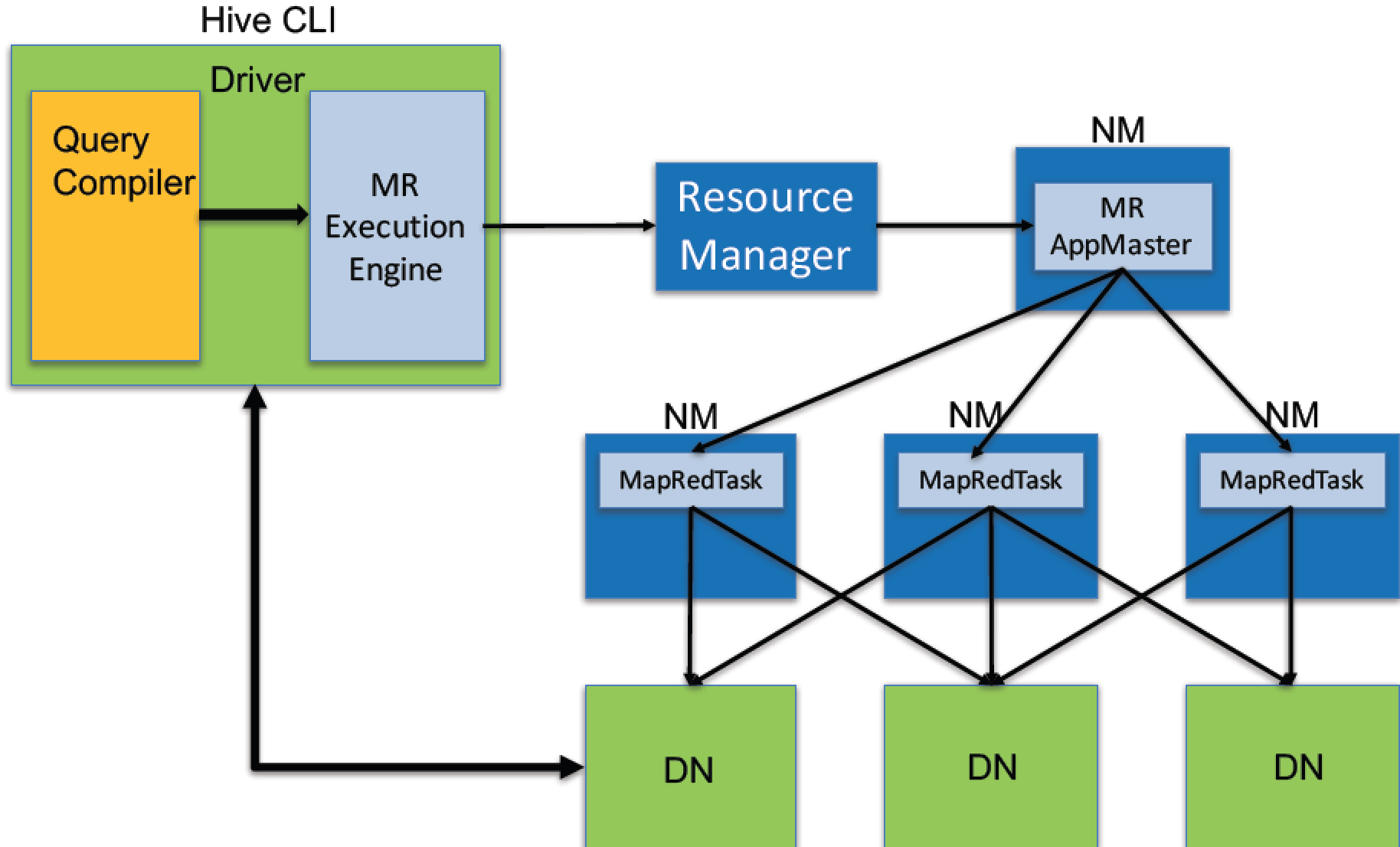

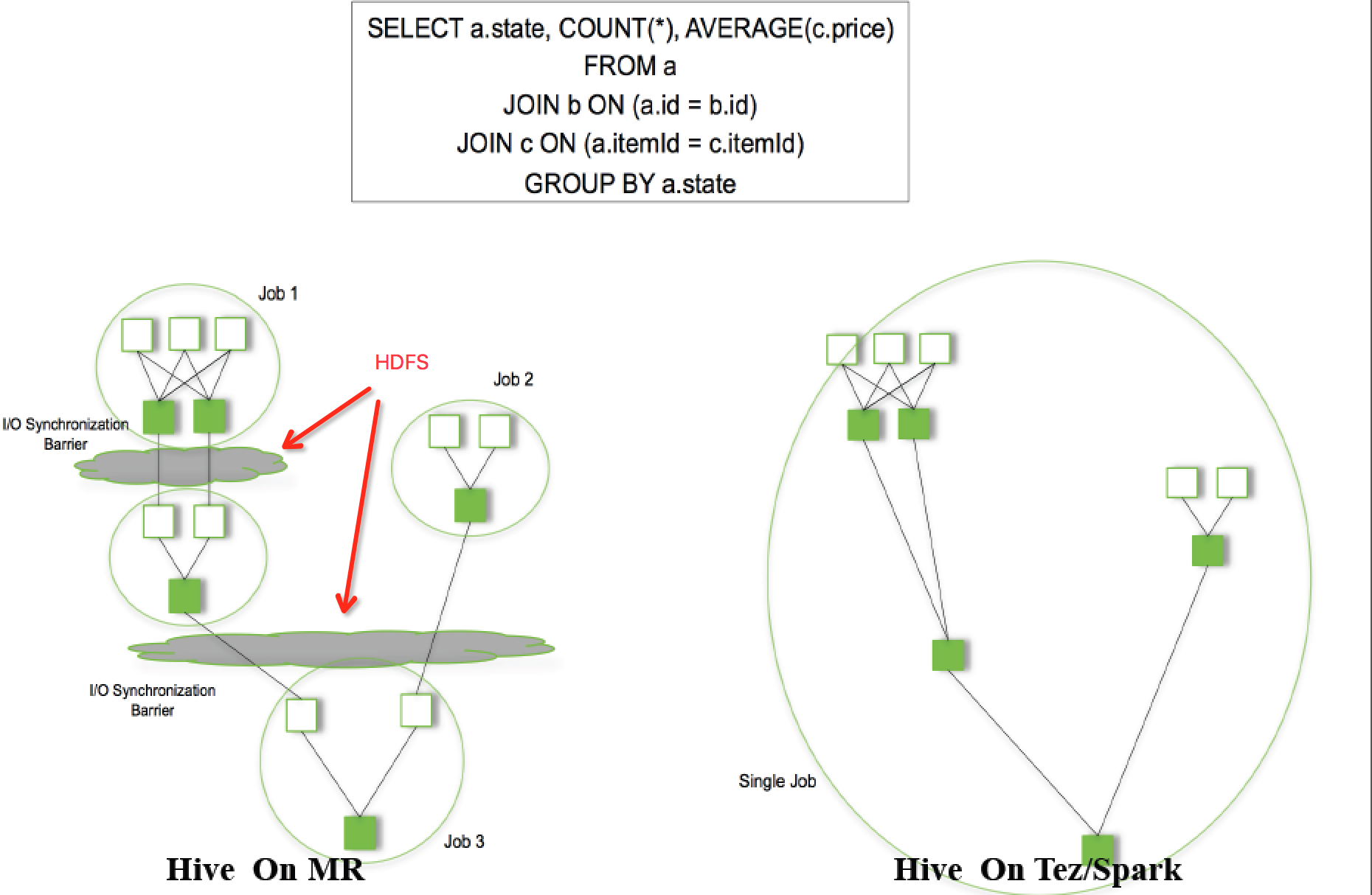
物理计划可以通过hive的Explain命令输出
例如:

0: jdbc:hive2://master:10000/dbmfz> explain select count(*) from record_dimension; +------------------------------------------------------------------------------------------------------+--+ | Explain | +------------------------------------------------------------------------------------------------------+--+ | STAGE DEPENDENCIES: | | Stage-1 is a root stage | | Stage-0 depends on stages: Stage-1 | | | | STAGE PLANS: | | Stage: Stage-1 | | Map Reduce | | Map Operator Tree: | | TableScan | | alias: record_dimension | | Statistics: Num rows: 1 Data size: 543 Basic stats: COMPLETE Column stats: COMPLETE | | Select Operator | | Statistics: Num rows: 1 Data size: 543 Basic stats: COMPLETE Column stats: COMPLETE | | Group By Operator | | aggregations: count() | | mode: hash | | outputColumnNames: _col0 | | Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE | | Reduce Output Operator | | sort order: | | Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE | | value expressions: _col0 (type: bigint) | | Reduce Operator Tree: | | Group By Operator | | aggregations: count(VALUE._col0) | | mode: mergepartial | | outputColumnNames: _col0 | | Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE | | File Output Operator | | compressed: false | | Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE | | table: | | input format: org.apache.hadoop.mapred.SequenceFileInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | | | | Stage: Stage-0 | | Fetch Operator | | limit: -1 | | Processor Tree: | | ListSink | | | +------------------------------------------------------------------------------------------------------+--+ 42 rows selected (0.844 seconds)
除了DML,Hive也提供DDL来创建表的schema。
Hive数据存储支持HDFS的一些文件格式,比如CSV,Sequence File,Avro,RC File,ORC,Parquet。也支持访问HBase。
Hive提供一个CLI工具,类似Oracle的sqlplus,可以交互式执行sql,提供JDBC驱动作为Java的API。
转载请注明出处:
作者:mengfanzhu

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步