
大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接

Hive主要分为以下几个部分
⽤户接口
1.包括CLI,JDBC/ODBC,WebUI
元数据存储(metastore)
1.默认存储在⾃带的数据库derby中,线上使⽤时⼀般换为MySQL
驱动器(Driver)
1.解释器、编译器、优化器、执⾏器
Hadoop
1.⽤MapReduce 进⾏计算,⽤HDFS 进⾏存储
前提部分:Hive的安装需要在Hadoop已经成功安装且成功启动的基础上进行安装。若没有安装请移步至大数据系列之Hadoop分布式集群部署。
使用包: apache-hive-2.1.1-bin.tar.gz, mysql-connector-java-5.1.27-bin.jar
云盘,密码:seni
本文将Hive安装在Hadoop Master节点上,以下操作仅在master服务器上进行操作。
1. 切换至普通用户 su mfz
2. 将gz包上传至目录下
/home/mfz
3.解压
tar -xzvf apache-hive-2.1.1-bin.tar.gz
4.目录:

5.创建hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>ThriftURIfor theremotemetastore. Usedbymetastoreclientto connectto remotemetastore.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_13?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>locationofdefault databasefor thewarehouse</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>beeline.hs2.connection.user</name>
<value>mfz</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>111111</value>
</property>
</configuration>
5.1由配置文件可看出,我们需要mysql的数据库hive_13,数据库用户名为hadoop,数据库密码为hadoop.
6.安装mysql
6.1 安装参考文章:Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
6.2 建立mysql数据库、用户、权限 参考文章:使用MySQL命令行新建用户并授予权限的方法
7.启动验证Mysql是否安装配置成功 :使用hadoop用户登录
mysql -u hadoop -p

8.配置hive环境变量:
vi /home/mfz/.bash_profile #Hive CONFIG export HIVE_HOME=/home/mfz/apache-hive-2.1.1-bin export PATH=$PATH:$HIVE_HOME/bin #wq .bash_profile #生效配置 source /home/mfz/.bash_profile #验证是否生效 echo $HIVE_HOME [mfz@master apache-hive-2.1.1-bin]$ echo $HIVE_HOME /home/mfz/apache-hive-2.1.1-bin
9. 将mysql的java connector复制到依赖库中
cp resources/msyql/mysql-connector-java-5.1.27-bin.jar apache-hive-2.1.1-bin/bin/
10.启动hive,命令: hive; 若出现如下几种错误请参照对应解决方案;
错误1:
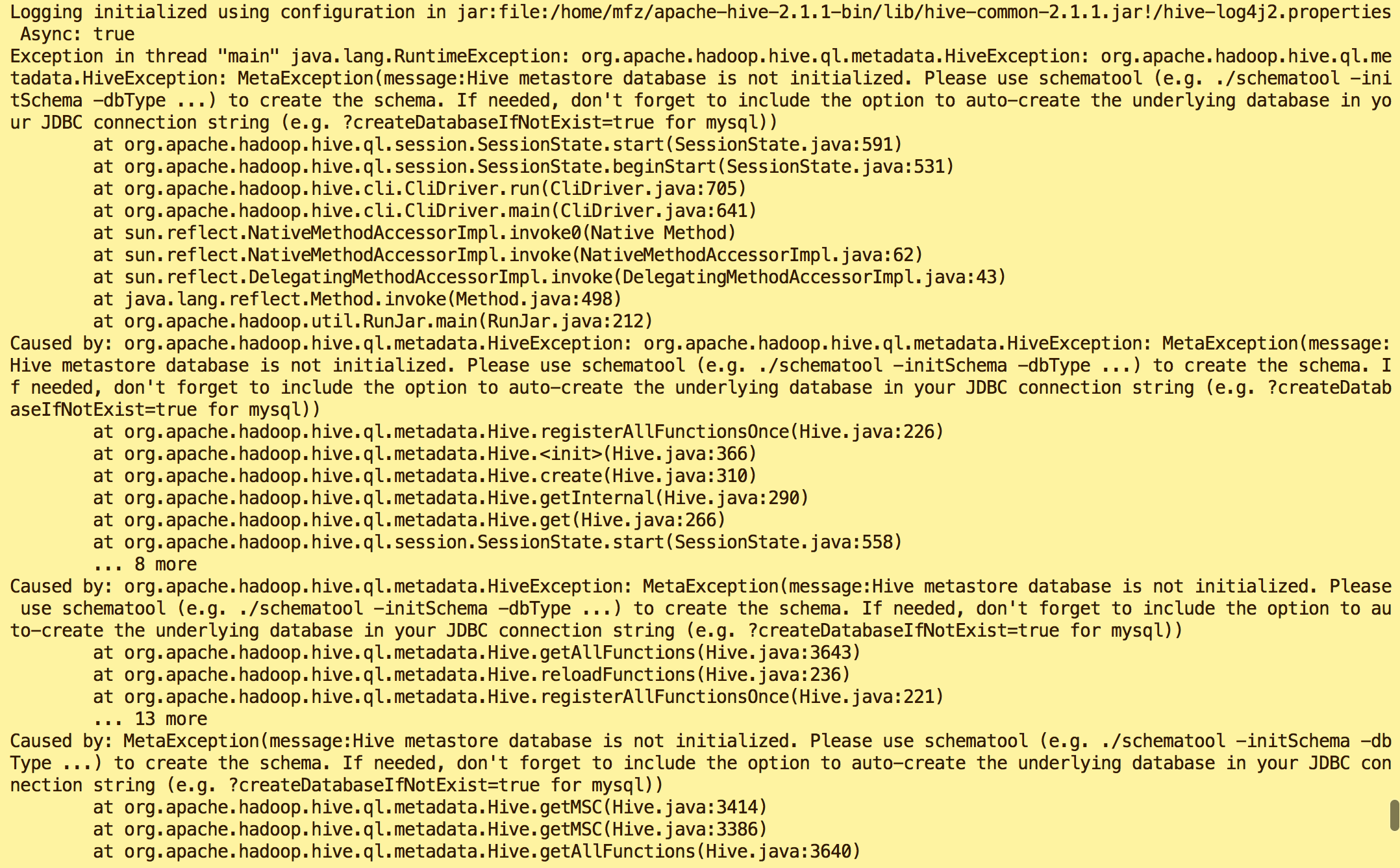
原因:Hive metastore database is not initialized
解决方案:执行命令
schematool -dbType mysql -initSchema
错误2:
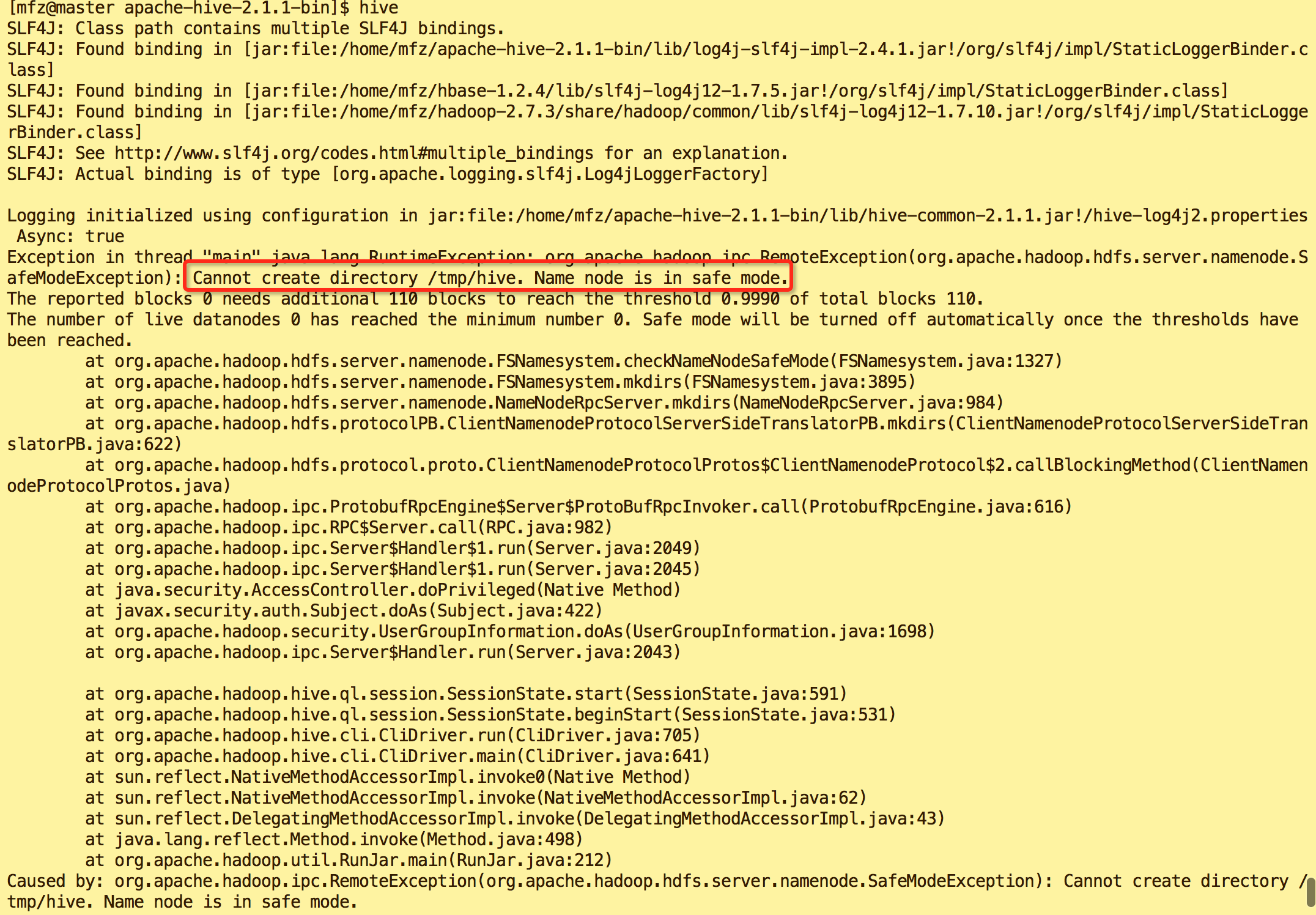
原因:hadoop 安全模式打开导致
解决方案:执行命令
#关闭hadoop安全模式 hadoop dfsadmin -safemode leave
11.启动hive.
A.方式1: hive命令

B.方式2(重要):
beeline
!connect jdbc:hive2://master:10000/default mfz 111111
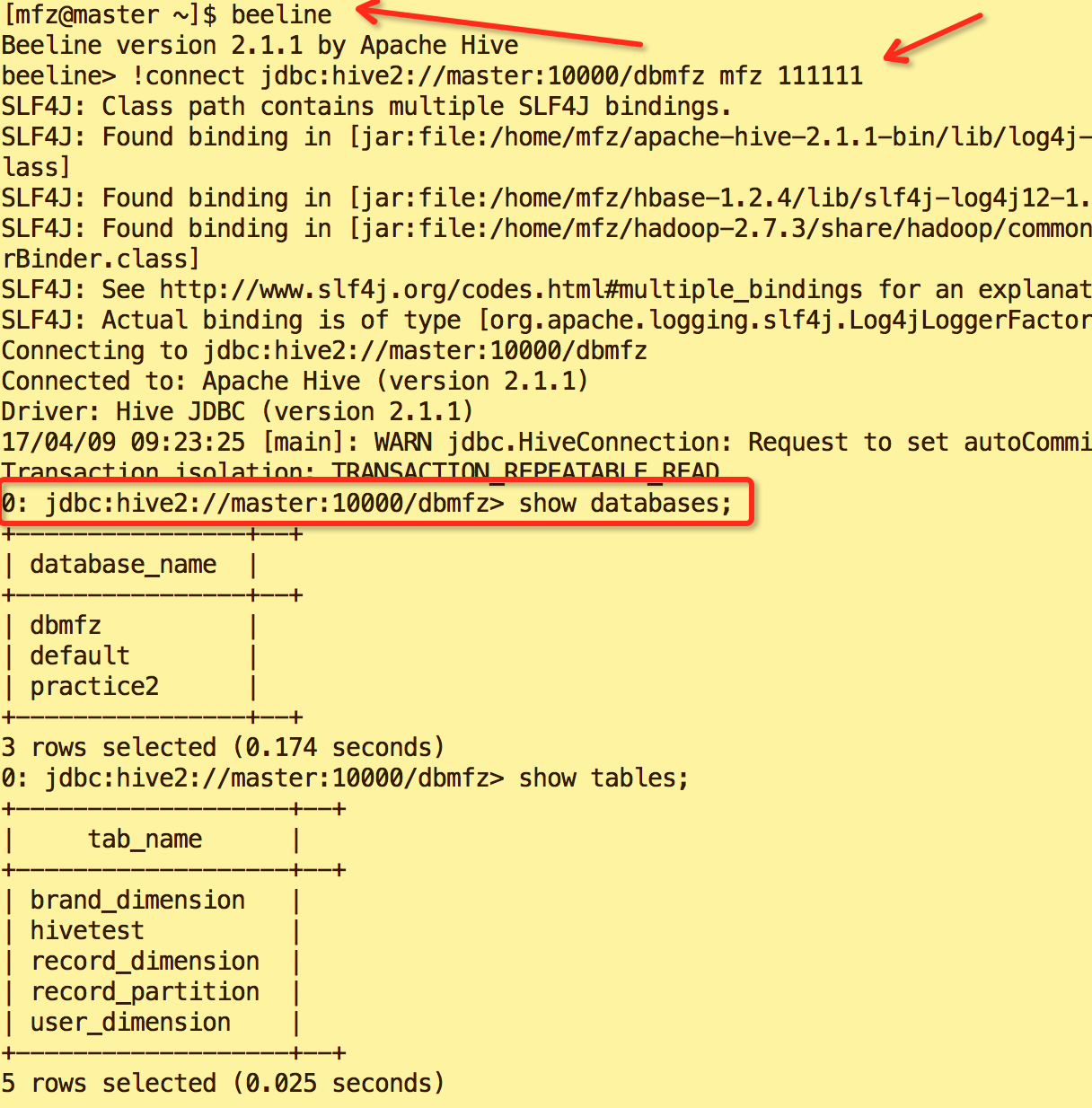
说明default是database名称,mfz是master服务器用户,111111是用户的登录密码.
因为beeline是取代hive客户端的新客户端,它访问HS2来发起hive操作,但是别急着敲下命令,继续往下看:这里涉及一个hadoop.proxy的概念:默认HS2是以user=anonymous身份访问Hdfs的,我们称HS2是hadoop的一个代理服务。但是,我们实际上希望以mfz身份去访问hdfs,因为此前创建的hive数据目录都是属于mfz用户的,anonymous是无法访问的,那么此时就需要给hadoop配置一个proxyuser,意思是HS2代理可以支持用户以mfz身份访问hdfs,而不是anonymous用户。
为了实现这个能力,需要修改hadoop项目的core-site.xml配置来实现(记得重启namenode和datanode):
<property>
<name>hadoop.proxyuser.mfz.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mfz.hosts</name>
<value>*</value>
</property>
10.hive 使用命令.
数据定义语句DDL
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
完~ 关于Hive的Nosql操作命令与Jdbc访问Hive方式见博文 大数据系列之数据仓库Hive使用
转载请注明出处:
作者:mengfanzhu

