
[DeeplearningAI笔记]卷积神经网络3.1-3.5目标定位/特征点检测/目标检测/滑动窗口的卷积神经网络实现/YOLO算法
4.3目标检测
觉得有用的话,欢迎一起讨论相互学习~




3.1目标定位
对象定位localization和目标检测detection
- 判断图像中的对象是不是汽车--Image classification 图像分类
- 不仅要判断图片中的物体还要在图片中标记出它的位置--Classification with localization定位分类
- 当图片中有 多个 对象时,检测出它们并确定出其位置,其相对于图像分类和定位分类来说强调一张图片中有 多个 对象--Detection目标检测
![]()

对象定位localization
- 对于普通的图像分类问题:在最后的输出层连接上softmax函数,其中softmax神经元的数量取决于分类类别数。
- 对于 定位分类 可以让神经网络多输出几个单元,输出一个边界框(bounding box),\(b_x,b_y,b_h,b_w\)
- 本节课程中将图片左上角标记为(0,0),右下角标记为(1,1),边界框中心标记为\(b_x,b_y\),边界框宽度表示为\(b_w\),高度表示为\(b_h\)
- 因此,训练集中的数据不仅包括神经网络要预测的 对象分类标签 还要有 对象的边框位置的四个参数值
![]()
- 假设图片中的对象有四类:1.pedestrian行人,2.car汽车,3.motorcycle摩托车,4.background背景,其中如果图片中没有1-3类对象,则默认其为背景。
- 对于目标标签(target label),其可表示为一个向量,其中第一个组件Pc表示是否有对象。如果对象属于前三类,则Pc=1,如果图片中没有目标对象,即是背景,则Pc=0.
![]()

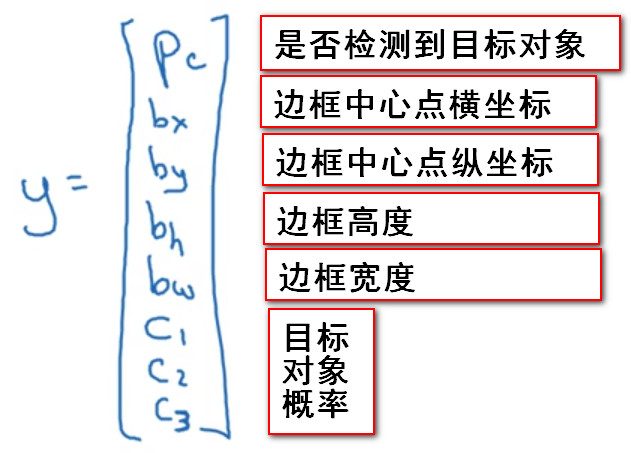
训练样本目标标签

损失函数
- 对于目标标签中不同的参数,也可以使用不同的损失函数,例如Pc使用逻辑回归而其余的使用平方和误差。
![]()
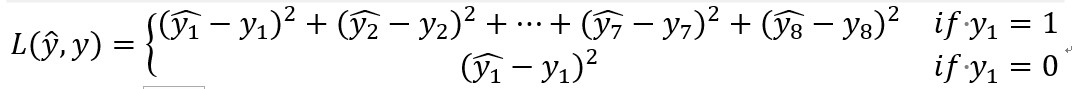
3.2特征点检测Landmark detection
- 对于特征点检测,给出一个识别面部表情的基本构造模块,即选取面部图片当中的64个坐标作为特征点。
- 注意:所有的特征点landmark在整个数据集中表示的含义应当一致
- 则目标标签的向量可表示为:
![]()
- 训练集中特征点的坐标都是人为辛苦标注的

人体姿态检测people post-detection
- 通过神经网络标注人物姿态的关键特征点,通过这些特征点的坐标可以辨别人物的姿态。
3.3目标检测Object detection
基于滑动窗口的目标检测算法(sliding windows detection algorithm)
- 对于训练集样本,X使用经过裁剪的,检测目标基本在图像中心的图片。Y表示样本图片中是否有需要检测的对象。训练完这个卷积神经网络,接下来就可以用它来实现滑动窗口目标检测。
![]()
- 首先选定一个特定大小的窗口,并使用以上的卷积神经网络判断这个窗口中有没有车,滑动目标检测算法会从左上角向右并向下滑动输入窗口,并将截取的图像都输入到 已经训练好的卷积神经网络中 以固定步幅滑动窗口,遍历图像的每个区域
- 然后使用比以上使用的窗口大一些的窗口,重复进行以上操作。然后再使用比上一次更大的窗口进行图像的截取与检测。
- 所以无论目标在图像中的什么位置,总有一个窗口可以检测到它。
![]()
- 但是滑动窗口目标检测算法有十分消耗计算成本的缺点,因为使用窗口会在原始图片中截取很多小方块,并且卷积神经网络需要一个个的进行处理。虽然使用较大的步长可以有效的节省计算成本,但是粗粒度的检测会影响性能,小步幅和小窗口就会大量的耗费计算成本
- 早些时候在普通的线性分类器上使用滑动窗口目标检测算法可以有很好的性能,但是对于卷积神经网络这种对于图像识别相当耗费性能的算法而言,需要对滑动窗口算法进行重新设计。


3.4卷积的滑动窗口实现Convolutional implementation of sliding windows
- 3.3中使用的基于滑动窗口的目标检测算法效率很低十分消耗计算成本,本节将介绍使用于卷积神经网络的滑动窗口算法。
将全连接层转换为卷积神经层Turning FC layer into convolutional layers
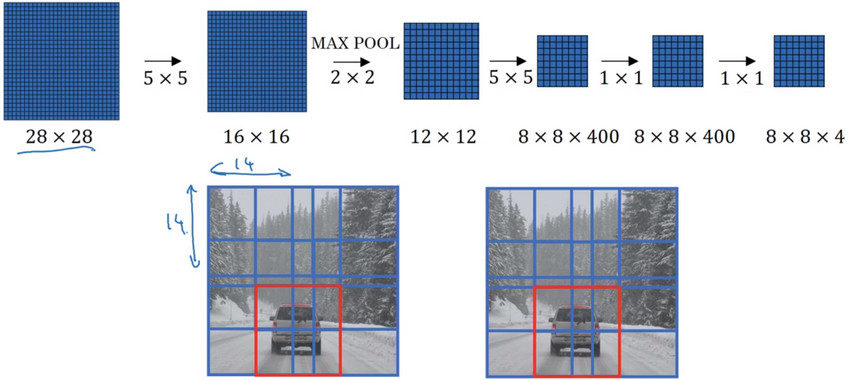
- 使用大小为\(14*14*3\)的图片作为图片数据,使用16个\(5*5\)的卷积核做卷积操作,得到\(10*10*16\)的特征图,然后使用\(2*2\)的max-pooling池化算法,得到\(5*5*16\)的特征图.将结果输入到两层具有400个神经元节点的全连接层中,然后使用softmax函数进行分类--表示softmax单元输出的4个分类出现的概率。
![]()
- 接下来要将最后连接的两个全连接层FC1和FC2转换为卷积层。
![]()
- 方法是 使用与得到的特征图大小相同的卷积核进行卷积,卷积核的数量对应全连接层中神经元节点的数量

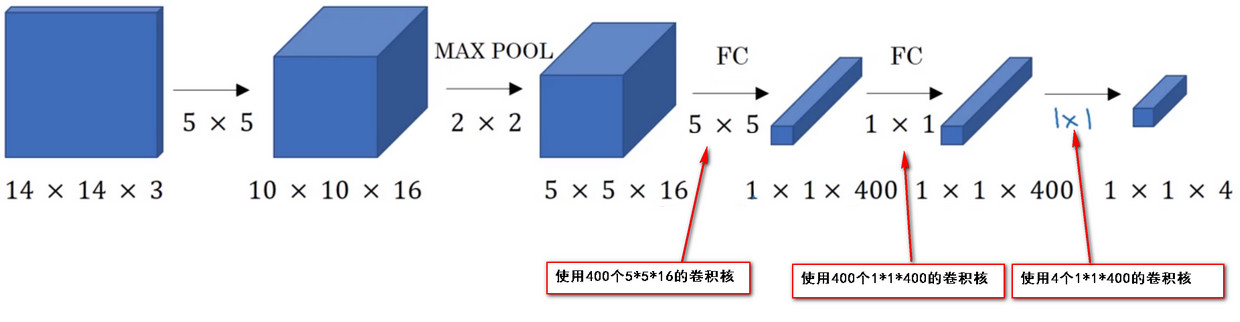
卷积层的滑动窗口实现Convolution implementation of sliding windows
参考文献
Sermanet P, Eigen D, Zhang X, et al. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks[J]. Eprint Arxiv, 2013.
- 使用卷积层代替全连接层的网络结构

- 假设\(14*14*3\)的图像是从\(16*16*3\)的图像中截取出来的,即原始图像的大小为\(16*16*3\).即首先截取原始图片中的红色区域输入网络,然后截取绿色区域,接着是黄色区域,最后将紫色区域截取出来作为图像数据集。
- 结果发现,滑动窗口得到的图片进行的这四次卷积运算中的很多计算都是重复的
- 得到的最终的\(2*2*4\)的稠密特征图各不同颜色部分都对应了原始图片中相同颜色的经过卷积操作后的结果。
![]()
- 所以正确的卷积操作的原理是我们不需要把输入图片分割成四个子集,分别传入卷积神经网络中进行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中共有的区域可以共享很多计算
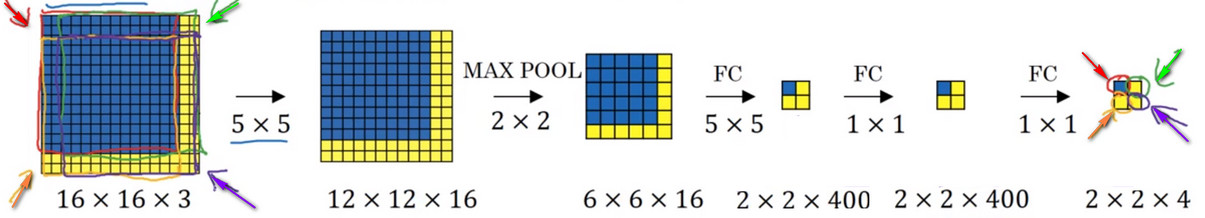
总结
- 对于卷积神经网络的滑动窗口实现,不需要依靠连续的卷积操作来识别图片中的汽车,而是可以对整张图片进行卷积操作,一次得到所有的预测值。如果足够幸运,神经网络便可以识别出汽车的位置。
![]()
补充
- 卷积神经网络的滑动窗口实现提高了整个算法的效率,但是这个方法仍然存在一个缺点: 边界框的位置可能不够准确
3.5得到更精确的边界框Bounding box predictions
- 有时边界框并没有完整的匹配图片中的对象,或者最佳的边界框并不是正方形,而是横向略有延伸的长方形。
YOLO algorithm
Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:779-788.
-
其中一个可以得到较精确的边界框的算法时YOLO算法--即You only look once
-
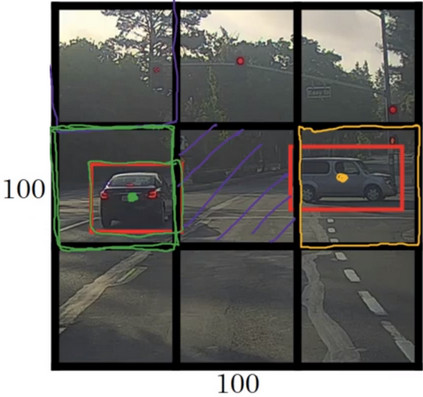
具体操作方式是:假设图像的大小是\(100*100\),然后在图像上放一个网格,为了描述的简洁,在此使用\(3*3\)的网格,实际中会使用更加精细复杂的网格,可能是\(19*19\).
- 基本思想是使用图像分类和定位算法(image classification and Localization algorithm)然后将算法应用到九个格子上。
![]()
- 更具体的是:你需要对每个小网格定义一个8维向量的目标标签,
如何编码边界框how to encode the bounding boxes
\[\begin{equation} A=\left[ \begin{matrix} p_{c}\\ b_{x}\\ b_{y}\\ b_{h}\\ b_{w}\\ 0\\ 1\\ 0\\ \end{matrix} \right] \left[ \begin{matrix} 使用0和1表示网格中是否有目标物体\\ 边框中心点横坐标值的范围在(0,1)之间\\ 边框中心点纵坐标的范围在(0,1)之间\\ 边框高可以大于1,因为有时候边框会跨越到另一个方格中\\ 边框宽可以大于1,因为有时候边框会跨越到另一个方格中\\ 行人\\ 汽车\\ 摩托车\\ \end{matrix} \right] \end{equation}\]- YOLO算法使用的是取目标对象边框中心点的算法,即考虑边框的中心点在哪个格子中。对于中间的三个边框,认为目标对象只存在于第二排第一个和第二排第三个网格中。
![]()
- 由于有3*3个网格,所以输出的标签的大小为\(3*3*8\),即8表示目标标签的深度,标签堆叠成为了一个长方体的形式而不是二维的堆叠方式
- 基本思想是使用图像分类和定位算法(image classification and Localization algorithm)然后将算法应用到九个格子上。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号