
[DeeplearningAI笔记]第三章1.4-1.7开发集测试集划分与满足与优化指标
觉得有用的话,欢迎一起讨论相互学习~




吴恩达老师课程原地址
1.4 满足和优化指标
Stisficing and optimizing metrics
- 有时候把你要考虑的所有事情组合成单实数评估指标,有时候并不容易,这时候使用满足和优化指标很重要.
- 假设以下是一个猫分类器,在我们已经考虑准确度的情况下,我们还要考虑运行时间(即区分一张猫图片所用的时间)
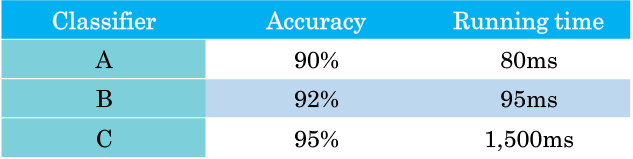
- 我们的做法是在满足运行时间的条件下,最大限度的提高准确度.例如我们这里选取运行时间必须满足小于100ms的条件,达到最大的准确度.即我们会选择满足条件的B分类器.
- 此时 准确度 是一个优化指标, 运行时间 是一个 满足指标
- 再举一个在 语音识别唤醒 中的例子, 优化指标是唤醒率(即输入语音后进行唤醒成功的概率,在用户说出唤醒词后,设备能够最大可能性的被唤醒) , 满足指标是"假阳性概率",即设备被用户意外唤醒的概率,这个只需要满足小于一天之内被唤醒一次就够了,即是一个(满足指标) .
1.5 训练/开发/测试集划分
- dev集也叫做开发集(development set)有时也被称为保留交叉验证集(hold out cross validation set).
- 在机器学习中的开发流程是:尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善模型在开发集上的性能直到你在开发集上的cost function的到的结果令你满意,然后再用测试集去评估这个模型.
dev set(开发集)和单实数评估指标就是机器学习团队开发的目标,这个目标必须足够准确,并且开发集和测试集一定得来自同一数据分布,应该将获得的所有数据随机的平均分布到开发集和测试集中,避免测试集测试模型时和开发集优化模型时的目标效果不统一.
1.6 开发集和测试集的大小
- 在机器学习的早期时代,我们的数据集数量只有 几千个 或者 几万个 这时候我们划分数据集的方式一般为:

- 但是现在数据集一般在100万的数据集及以上,我们不必使用大规模的数据去构成开发集和测试集.假如我们现在有100万条数据,我们只需要取出2%的数据来构成开发集和测试集.
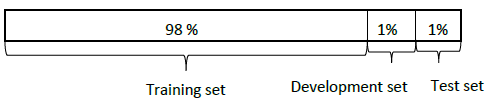
经验法则
- 如果你对最终投产的系统有一个很精确的指标,需要大量的数据.如果你的应用不需要很高的置信度,测试集不需要海量数据.
- 测试集可以帮助评估最终分类器的性能,取决于总体的数据量.如果总体数据量很大,测试集会少于数据集的30%.
- 开发集要足够大能够测试不同的模型.
1.7什么时候需要改变开发集/测试集和评价指标
cat dataset example
- 假设你的产品是一个猫分类器,指定的指标是分类误差(classification error) .以下展示算法A和算法B的误差率.

- 从评价指标和开发集的角度来看,我们应该选择A模型,但是某种原因,A算法会让更多的Pron图片通过识别.即是在这个指标中A算法看起来更好,但是在产品实际运用中,公司和用户更加青睐于B种方案.因为B方案没有Pron图片会通过. 在这个例子中我们发现,B算法其实优于A算法,而评价指标没有发挥应有的作用.
- 因此,在这个例子中,我们需要更改评价指标,以及更新开发集和测试集.
- 原有的误差率函数为:
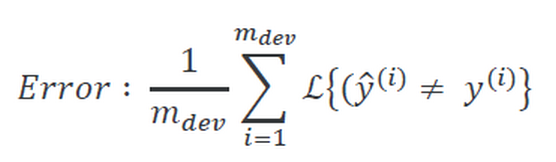
这表示的是开发集上经过归一化后的误差率.
- 原有评价指标的缺点在于:将Pron图片和非Pron图片平等对待,我们解决这个问题的方法可以是,将Pron图片加上更高的误差权重.

经验法则
- 对于评价指标的选取和训练的过程实际上遵循正交化的原则,即先指定一个评价指标,然后使算法在开发集和测试集上的表现越来越好.在实际的运用中,如果出现适应性问题,再修改评价指标和适当的改变开发集和测试集.
- 总体上说你当前的开发测试集和评价指标和你真正关心必须做好的事情关系不大,我们真正应该关注的是实际应用中你需要处理好的用户数据.通过实际中的表现调整开发测试集合评价指标,让他们更好的反应你真正需要处理好的数据.
- 有一个评估指标和开发集让你可以更快的作出决策,判断算法A还是算法B更优,这真的可以加速你和你的团队迭代的速度.所以即使你当前无法定义一个很完美的评估指标和开发集,你可以直接快速设立出来,然后使用它们来驱动你们的团队的迭代速度.在这之后,如果你发现选的不好,你有更好的想法,那么完全可以马上修改.对于大多数团队建议不要在没有评估指标和开发集时跑太久.因为这样会减慢你的团队的迭代和改善算法的速度.
posted @
2017-10-31 13:19
WUST许志伟
阅读(
757)
评论()
编辑
收藏
举报

