

Java容器:Map
1. Map概述
Map是一种把键对象和值对象进行关联的容器。一个值对象又可以是一个Map,以此类推,这样就可以形成一个多级映射。Map容器中的键对象不允许为重复,具有唯一性。值对象则没有唯一性要求。
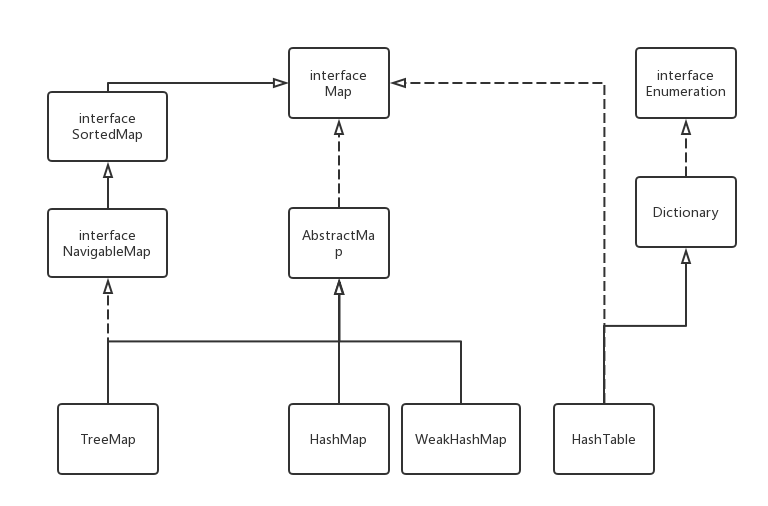
1.1. Map类的继承关系
1.2. 几个Map接口类概念
- Map 对应映射的抽象接口,不包含重复的键。
- SortedMap 有序的键值对接口。
- NavigableMap 继承SortedMap,具有了针对给定搜索目标返回最接近匹配项的导航方法的接口。
- AbstractMap 实现Map中绝大部分函数的接口,用于减少Map的几个实现类中的重复编码。
- Dictionary 任何可将键映射到相应值的类的抽象父类,目前被Map接口取代。
1.3. Map类的通用方法
Map插入方法:
void put(Object key,Object value)最基本的插入方法。void putAll(Map map)假设忽略构建一个需要传递给 putAll() 的 Map 的开销,使用 putAll() 通常也并不比使用大量的 put() 调用更有效率,但 putAll() 的存在一点也不稀奇。这是因为,putAll() 除了迭代 put() 所执行的将每个键值对添加到 Map 的算法以外,还需要迭代所传递的 Map 的元素。但应注意,putAll() 在添加所有元素之前可以正确调整 Map 的大小,因此如果您未亲自调整 Map 的大小(我们将对此进行简单介绍),则 putAll() 可能比预期的更有效。
Map查看方法:
我需要介绍一下Map.Entry类,尽管不是方法而是一个类型,但是作为铺垫还是要谈一下。在HashMap中的Entry类结构如下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
Entry是存储Map内容的基本单元。在说明了该类后,列出三种Map的查看方法。
Set entrySet()返回一个Map.Entry类的对象构成的集合。可以使用getKey(),getValue()来获取需要的Entry类对象,改变entrySet对象也会影响到Map。Set keySet()返回一个由键组成的Set,删除该Set中元素会影响Map中的映射。Set valueSet()返回一个由值组成的Set,删除该Set中元素会影响Map中的映射。
需要特殊注意的是,以上三种方法是查看Map的方法,即对以上三个方法返回的Map进行操作都会影响到原对象。因为以上三个对象均为Set对象,其迭代也应该遵守Set类的Iterator迭代。
Map读取方法:
Object get(Object key)最简单的通过键值获取value的方法。boolean containsKey(Object key)检查是否包含某个key。boolean containsValue(Object value)返回检查到的第一个value映射的key。boolean isEmpty()返回Map是否为空。int size()返回Map中条目的数量。
Map删除方法:
void remove(Object key)移除某个key对应的value。void clear()清空Map对象。
接下来简单介绍下几个实体类
2. HashMap
2.1. 构造函数
HashMap类构造函数为:
public HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity)
public HashMap()
public HashMap(Map<? extends K, ? extends V> m)
从HashMap的构造函数我们能够发现两个概念:初始容量initialCapacity,负载因子loadFactor。这两个参数会影响HashMap的性能。其中,容量表示哈希表中桶的数量,初始容量是创建哈希表时的容量,负载因子是哈希表在容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间使用程度,负载因子越大表示散列表的填装程度越高,反之越小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低。如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重的浪费。系统默认负载因子为0.75,一般情况下不去修改。
我们可以查看HashMap构造函数源码:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
(由于这段算法蛮有趣的,详细的说说tableSizeFor这个函数的内容)
tableSizeFor方法的实现如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
当实例化HashMap时,如果给定了initialCapacity,由于HashMap的capacity都是2的幂,这个方法用于找到大于等于initialCapacity的最小的2的幂。接下来逐行分析该算法。
int n = cap - 1;
防止cap已经是2的幂,如果已经是2的幂,后面几次右移后得到的capacity将是cap的2倍。另外,如果cap==1,那么n为0,几次右移仍为0,返回的值为n+1,仍为1。
n |= n >>> 1;
第一次右移,由于n!=0,n的二进制表示不会全为0,且最高位应为1。通过无符号右移1位,则将最高位右移了1位,再和n进行或操作,进而使n的二进制表示中最高位的右边一位也为1。即0……011XXXXX的形式。
n |= n >>> 2;
n已经经过了一次右移取或操作后,再无符号右移两位,会将最高位两个连续的1右移两位,再与原数进行或操作,最高位会变为4个连续的1。
n |= n >>> 4;
类似的,使最高位变为8个连续的1,后面两行以此类推,由于容量最大为32bit,因此该过程只持续到16,也就是32个1,但此时已经大于MAXIUM_CAPACITY,所以结果会取MAXIUM_CAPACITY。在右移过程中,如果数字不够大,则会右移为全0,和原数字或操作后会恢复为原数字。因此,这种方法可以最快的获得大于等于一个数字的最小2的幂。之后,这个值被赋值给threshold作为阈值。当HashMap的size达到了这个阈值后会扩容。
(题外话完毕)
在上面给threshold赋值后,首次运行put()操作时,会进行初始化。
2.2. 数据结构
HashMap是一种支持快速存取的数据结构,想要了解其性能必须了解它的数据结构。Java中最常用的两种结构是数组和模拟指针(引用),几乎所有的数据结构都可以用这两种结构来组合实现,HashMap也是如此。HashMap是一个链表散列,它的数据结构大体为一个数组,只是数组的每个项都是一条链表。 参数initialCapacity代表了该数组的长度。
HashMap的Node节点结构如下(省略了一些简单的set,get以及初始化函数):
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
Node包含了key,value,下一个节点next以及hash值,正因为这样,table数组的每项正式由Node以及其链表所组成。table的声明如下:
transient Node<K,V>[] table;
2.3. 存储实现
HashMap的put方法由于较为复杂,此处就不展开说明。大概过程即,如果key为null,则调用空key的put方法。否则,计算key的hash值,根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来的value(因此HashMap中不会有两个相同的key),否则将元素保存在链头(即最先保存的元素在链尾)。若table数组在该处没有元素,则直接保存。
hash方法相关代码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
其中,hashCode()方法为Object()类的原生方法,此处仅仅进行了一次无符号16位位移并异或操作。对于小于16位的数,会为全0,即仍保持原hashCode。
当HashMap中的元素越来越多,则发生碰撞的概率会越来越大,所产生的链表长度就会越来越长,这样将会影响HashMap的速度。为了保证效率,系统需要在上面讲到的临界点数组长度threshold*loadFactor时进行扩容。但扩容是一个很消耗时间的过程,因此,如果我们对数据规模有着预先的估计,那么最好进行预设。
3. HashTable
HashTable是继承自Dictionary实现了Map接口的类。由于对外功能上,HashTable和HashMap基本相同,包括通过initialCapacity和loadFactor进行初始化等操作以及put,get等方法,因此我不再对HashTable进行详解。其和HashMap的主要区别为以下几点:
- 从定义上看,HashTable基于Dictionary类,HashMap基于AbstractMap类,因而HashTable的实现本身要比HashMap复杂。
- HashMap允许值为null的key,且对于value没有任何要求,只要是对象就可以;HashTable遇到null时,会直接抛出NullPointerException异常。
- HashMap仅支持Iterator遍历,HashTable支持Iterator遍历和Enumeration遍历。
- HashTable中方法均有synchronized修饰,是线程安全的。而HashMap方法不是。因此,在多线程操作中,建议使用HashTable。(另外,可以采用Collections类中的静态方法synchronizedMap()来创建一个线程安全的Map对象。synchronizedMap是一个有条件的线程安全变量,单个操作是线程安全的,但多个操作组成的序列则可能导致数据争用。该方法的具体探讨会放在以后说。)
4. WeakHashMap
WeakHashMap是一种特殊的HashMap,简单而言,它的key采用了弱引用WeakReference的方式,关于对象的引用可以参考我的这篇Java基础:Java的四种引用。因此,其特点为,当除了自身的弱引用外,若WeakHashMap中的key没有其他引用(强引用),那么map会自动丢弃此值。需要注意的是,废弃key的回收发生在对WeakHashMap对象的访问时,如果不对其进行访问,则不会释放内部废弃对象。
5. TreeMap
TreeMap的实现基于红黑树,理解了红黑树,也就基本理解了TreeMap。阅读此部分前,需要先阅读我的博文:
5.1. 数据结构
TreeMap继承了NavigableMap接口和AbstractMap类,后者说明其支持Map的所有基本功能,前者说明其支持一系列的导航方法。
TreeMap的Entry类和HashMap相比,略有不同,结构如下:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
我们可以看到该类包含了基本的key,value以及独有的左子节点left,右子节点right,父节点parent,颜色属性。我们可以发现TreeMap完全就是一棵红黑树。而key和value则是该树存储的信息。其插入,删除元素的方法均符合红黑树的插入,删除方法。具体实现可以自行查阅源代码,大致内容和在二叉树,AVL树和红黑树中已有的伪代码相同。另外,查阅TreeMap代码时,我们很容易发现,TreeMap实现过程中和HashMap一样也并没有考虑线程安全,需要使用时加以注意。
