WordCount 小作业
GitHub 项目地址
https://github.com/cosensible/WordCount
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 30 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 30 | 30 |
| Analysis | 需求分析(包括学习新技术) | 20 | 50 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 600 | 1200 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试 | 120 | 120 |
| Reporting | 报告 | 60 | 90 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 20 |
| 合计 | 950 | 1630 |
解题思路
拿到题目以后觉得基本功能实现起来挺简单的,扩展功能中觉得停用词表这个功能挺简单,只要将文件中的停用词读出来后放到一个ArrayList中即可,方便以后使用。递归读取文件一开始觉得有些乱,不知如何下手,在网上查了查,发现实现起来也挺简单的,具体参考这里。然而,对于 “代码行/空行/注释行” 的统计,我觉得这里的情况实在太多了,尤其是对注释行的判定,不过,仔细读了要求后算是大概知道规则了,不知道自己有没有理解错。最后,没时间和精力去完成高级功能了,因为自己身体这两天都快被掏空了。之后就开始编码了,因为自己这学期稍微看了一点Java,所以还算比较熟悉。但是,对于测试的编写,自己很迷惑,不知道如何去编写,想了一会儿,还是决定先把代码写完,实现功能再说。
还有一个要求是要生成exe文件,这个第一想法便是Google一下,于是便有了这个链接。
程序设计实现过程
由于功能看起来还算比较少,所以自己就没有详细思考如何组织代码,只是想着每个功能对应一个函数,先把基本功能做完再说。做完基本功能后,觉得代码量就有些多了,于是在扩展功能开始前,自己分析了一下应该如何组织这些功能对应的函数。基本想法是在主函数中对扩展功能的参数进行分析,因为他们基本都涉及到对文件的读写操作,然后将基本功能(-c -w -l -a)封装在一个函数中,方便递归分析功能(-s)的实现。由于输出结果要按照规定的顺序输出到文件中,所以在基本功能封装函数中用了一个TreeMap,它对里面的键值对可以按键大小自动排序,所以在读取信息时,可以按照规定的顺序输出。
程序流程
主流程:main函数
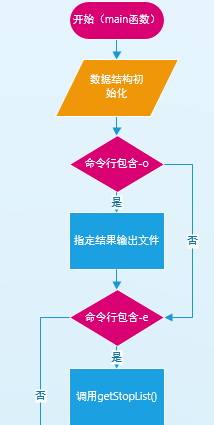
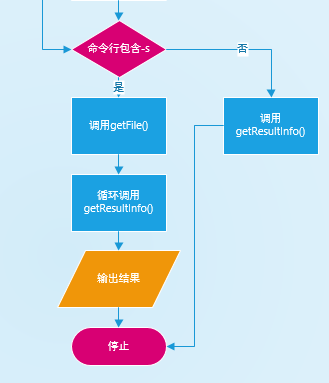
辅助流程:getResultInfo函数

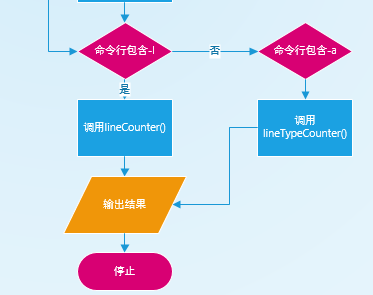
代码说明
返回字符数
主要使用FileReader的read()函数
while((fileReader.read())!=-1)
++num;
返回文件行数
主要使用FileReader的readLine()函数
while(fileReader.readLine()!=null)
++num;
返回单词数
主要用到String的split()函数对字符分割。首先跳过空行,然后将每行中的字符串按空字符(多个空格、制表符等等)分割后再按逗号分割。去掉空字符串后对单词进行统计,统计时要用到装有停用词的ArrayList。
while ((str = fileReader.readLine()) != null) {
if (!str.equals("")) {//跳过空行
for (String s : str.split("\\s+")) {//将一行以多个空字符分割
for (String word : s.split(",")) {//以逗号分割
if (!stopLists.contains(word)&&!word.equals(""))//stopList不含单词且不为空
num++;}}}}
返回 ”代码行/空行/注释行“ 数量
对 ”代码行/空行/注释行“ 的判断标准如下:
- 代码行:本行包括多于一个字符的代码。
- 空 行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
- 注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:}//注释,在这种情况下,这一行属于注释行。
int[] lineTypes=new int[3];//分别为代码行,空行,注释行
while((str=fileReader.readLine())!=null){
str=str.replaceAll("\\s+","");
//行内无字符或者有一个字符且为'{'或'}'时,为空行
if (str.equals("")||str.length()==1&&(str.equals("{")||str.equals("}")))
lineTypes[1]++;
else if (str.contains("/*")){
//以/*开头,且位于行首或者前面有一个字符且为'{'或'}'时,为注释行
if (str.indexOf("/*")==0||str.indexOf("/*")==1&&(str.charAt(0)=='{'||str.charAt(0)=='}')){
lineTypes[2]++;
if (str.contains("*/"))// 注释结束符*/在本行
continue;
while((str=fileReader.readLine())!=null){//注释结束符不在同一行
if (str.contains("*/")){
if (str.indexOf("*/")==(str.length()-2)) //注释结束符在当前行末尾,是注释行
lineTypes[2]++;
else
lineTypes[0]++;//不在末尾,代码行
break;
}
lineTypes[2]++;//没遇到*/结束注释前,行都为注释行
}
}
}
//以//开头,且位于行首或者前面有一个字符且为'{'或'}'时,为注释行
else if (str.indexOf("//")==0||str.indexOf("//")==1&&(str.charAt(0)=='{'||str.charAt(0)=='}'))
lineTypes[2]++;
else//其他行为代码行
lineTypes[0]++;
}
递归读取文件
这里用到File类,它有两个函数:isFile()和isDirectory(),分别判断文件对象是文件还是目录。如果是文件,判断它是否符合条件(后缀),符合就加入一个ArrayList文件集。如果是一个目录就进行递归查找。
for(int i=0;i<files.length;i++) {
if(files[i].isFile()) {//如果是文件
String tmp=files[i].getName();
//判断文件名是否符合条件(比如后缀)
if (tmp.indexOf(".c")==tmp.length()-signal.length())//如果包含signal
fileList.add(files[i].getCanonicalPath());//添加文件路径
}
else if(files[i].isDirectory()) {//如果是文件夹
if (files[i].getName().equals("jre")) {//跳过程序依赖环境的目录查找
System.out.println("ignore this catelog named jre.");
continue;
}
//文件夹需要调用递归
fileList.addAll(getFile(files[i].getPath(),signal));
}
}
以上便是主要功能实现的函数,详细代码可根据文首给出的项目地址查看。
测试设计
白盒测试介绍
根据软件产品的内部工作过程,在计算机上进行测试,以证实每种内部操作是否符合设计规格要求,所有内部成分是否已经过检查。这种测试方法就是白盒测试。白盒测试把测试对象看做一个打开的盒子,允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。通过在不同点检查程序的状态,确定实际的状态是否与预期的状态一致。这里主要采用基于独立路径的测试方法。
统计字符数或行数
统计字符数和行数类似,加入了停用单词表的参数后,只需要最后一个分支节点加一个判定条件即可,对以下程序图无影响。该程序图有一个分支节点,所以有两条独立路径。
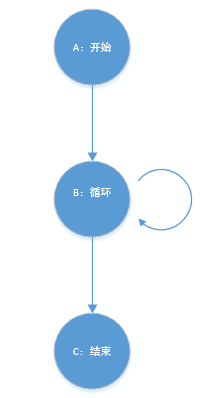
| 路径 | 输入 | 预期输出 | 实际输出 |
|---|---|---|---|
| A->B->C | NULL | 0 | 0 |
| A->B->B->C | 'a' | 1 | 1 |
统计单词数
共有五个分支节点,故有六条独立路径。
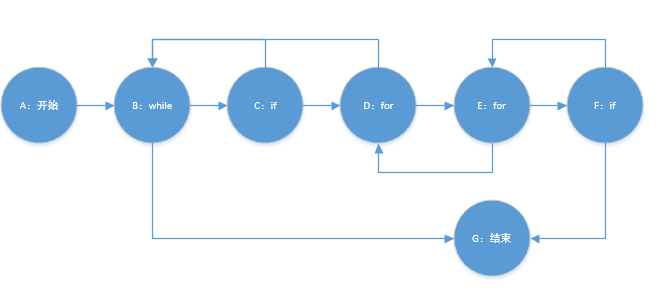
| 路径 | 输入 | 预期输出 | 实际输出 |
|---|---|---|---|
| A->B->C->D->E->F->G | 空字符 + ,test | 1 | 1 |
| A->B->G | NULL | 0 | 0 |
| A->B->C->B->C->D->E->F->G | 空行 + 空字符 + ,test | 1 | 1 |
| A->B->C->D->B->C->D->E->F->G | 不存在 | ||
| A->B->C->D->E->D->E->F->G | 不存在 | ||
| A->B->C->D->E->F->D->B->G | 空字符行 | 0 | 0 |
统计”代码行/空行/注释行“
由于代码行/空行/注释行的判定标准很复杂,所碰到的情况也很多,会产生很多判定节点,其程序图如下图所示:

这个程序图非常复杂,我尽量画得很简洁了,但是看起来依旧不好看。可以看到,图中有11个判定节点,所以共有12条独立路径,具体的测试过程非常复杂,以下直接给出测试的文本文件:
test()
{
File writename = new File(outputPath);
writename.createNewFile();
codeLine*/
BufferedWriter out = new BufferedWriter(new FileWriter(writename));
//noteLine
out.write(outputBuffer);
/*noteLine
/*noteLine
*/
/*noteLine*/
/*noteLine
//noteLine
*/codeLine
out.flush();
out.close();
}//noteLine
for(){
}/*noteLine*/
预期输出:atest.c, 代码行/空行/注释行: 10/3/9
实际输出:atest.c, 代码行/空行/注释行: 10/3/9
返回统计结果
这个函数组装几个基本功能(-c -w -l -a 参数),主要用来给递归统计信息功能服务。以下是基本程序图:
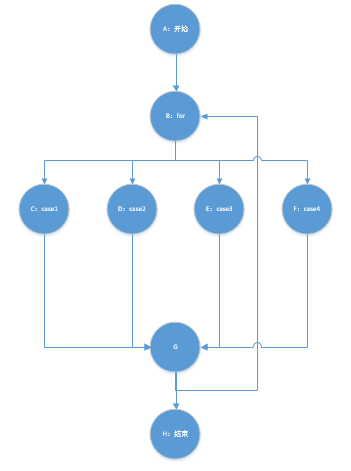
通过分析知道有5条独立路径。
| 路径 | 输入 | 预期输出 | 实际输出 |
|---|---|---|---|
| A->B->C->G->H | 输入命令-c | 输出字符统计结果 | 输出字符统计结果 |
| A->B->D->G->H | 输入命令-w | 输出单词统计结果 | 输出单词统计结果 |
| A->B->E->G->H | 输入命令-l | 输出行数统计结果 | 输出行数统计结果 |
| A->B->F->G->H | 输入命令-a | 输出行类型统计结果 | 输出行类型统计结果 |
| A->B->C->G->B->D->G->H | 输入命令-c -w | 输出字符和单词统计结果 | 输出字符和单词统计结果 |
递归获取满足条件的文件
该函数递归获取当前目录下的所有给定后缀的文件路径,且返回文件路径结果集,这里的分析以".c"后缀为例。程序图如下图所示:
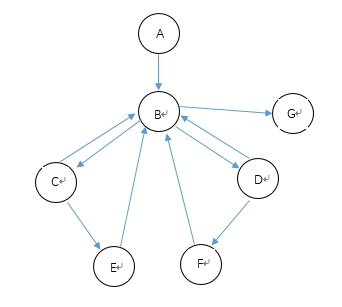
只有五条独立路径是有效的,如下表所示:
| 路径 | 输入 | 预期输出 | 实际输出 |
|---|---|---|---|
| A->B->G | 目录下无文件且无目录 | 空文件集 | 空文件集 |
| A->B->C->E->B->G | 目录下只有一个文件且后缀为".c" | 返回一条结果 | 返回一条结果 |
| A->B->C->B->G | 目录下只有一个文件且后缀不是".c" | 空文件集 | 空文件集 |
| A->B->D->F->B->G | 目录下只有一个jre目录 | 空文件集 | 空文件集 |
| A->B->D->B->C->E->B->G | 目录下有一个只含有一个".c"文件的不为jre的目录 | 一条结果 | 一条结果 |
以上内容就是主要功能的测试设计。
WordCount 使用说明
具体使用说明详见项目地址。
