


背景
最近在研究中产生了这样的需求:在三角网格(Mesh)表示的地形图上给出两个点,求得这两个点之间的地面距离,这条距离又叫做“测地线距离(Geodesic)”。计算三角网格模型表面两点间的测地线是计算几何中一个基础性的问题,已有的算法有精确算法和近似算法两类。一般来说,精确算法需要耗费较高的运算时间和运算空间;而近似算法在牺牲一定的计算精度的条件下,能够更快地得到三角网格表面测地线的近似值,因而也得到广泛的使用。在测地线距离比三角形的平均尺寸大的多的情况下,完全可以把三角网格模型当作一个无向带权图(Graph)。然后将求测地线距离的问题转化为求得图上两个节点的最短路径问题。这样就能让这条最短路径近似代替测地线距离使用。
首先解释一下为何无向图的最短路径只是近似估计了测地线距离。因为测地线距离形象的说是一个“表面距离”,可以想像一个点可以任意在三角网格表面移动,而无向带权图不存在所谓“表面”的概念,所有的路径都是由图的边(Edge)组成。可从下面两个图上路径的区别看出这一点:
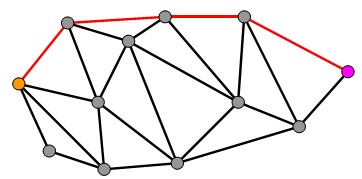 |
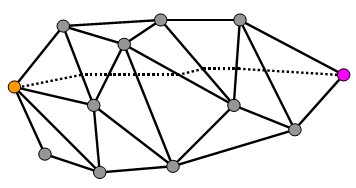 |
| 无向带权图的一条路径,路径均由边组成 | 三角网格的测地线,可从三角形面上经过 |
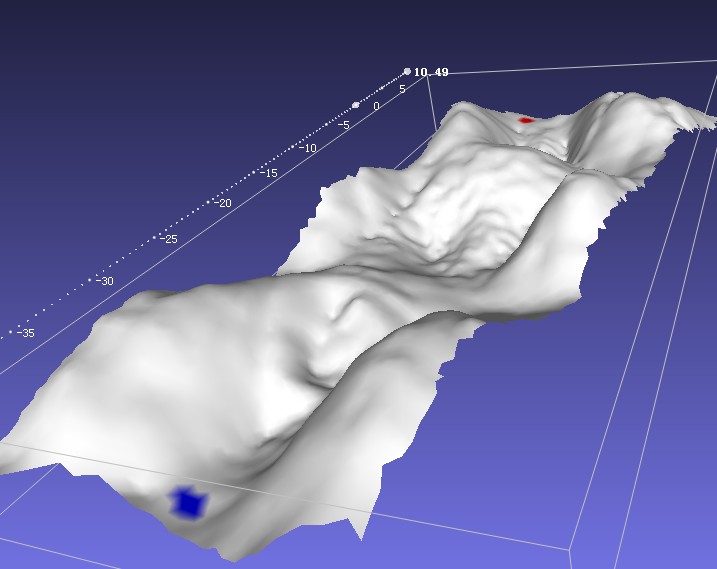
然后回到本篇的主题,如何使用带权图寻路算法求出一个地形网格上的近似最短路线,比如下图就是这样一个有起伏山路的模拟地形网格。
 |
 |
| 渲染效果 | 三角网格模型,可以当作无向带权图 |
使用MeshLab的画刷可以在网格上面把顶点上色,我们使用它给出了地形图上的一个起点区域和一个终点区域,分别使用蓝色和红色表示。这样我们可以将涂为蓝色的点集中任意一点作为起点S,涂为红色的点集中任选一点作为终点E。我们也可以尝试直观的标记出三条可能的最短路径。
 |
 |
| 计算时随机在蓝色区域选择一个起点,在红色区域选择一个终点 | 可能的最短路径,Meshlab上手画的 |
多种模型的Graph抽象
在介绍寻路算法之前,首先需要对带权图Graph做一个抽象数据结构的实现。在实际应用中,各种各样的模型都可以看做图,比如本文介绍的三角网格(Mesh),以及之后还会再讲到的方格图。在解决实际问题的过程中,虽然他们的表象有明显差别,但都能够抽象出一些共通点,然后采用相同的算法解决问题。
| 模型 | Mesh | 方格图 |
| 预览图 |  |
 |
| 节点 | 顶点(Vertex) | 非障碍物的方格(Squar) |
| 边 | 顶点的连线 | 方格的相邻关系 |
| 节点邻居 | 与节点相连的其他节点 | 非障碍物的4或8领域方格 |
关于Mesh的基础知识以及如何在Mesh上求取各个顶点的邻接点这些知识不在本文讨论范围内,感兴趣的可以参考之前的博文:“三角网格数据结构”与“三角网格数据结构-2”。在这里我们只需知道,Mesh可以当作Graph,我们只需对其进行一层抽象。
对于对于任何可以当作图来理解的数据结构,为了提供寻路算法必要的操作,我们都要为他实现下面AbstractGraph的接口,这些接口反映了这些模型的共通性,无论是对Mesh,还是对方格阵列。实现寻路算法的模块只需见到这样一个支持这个接口操作的对象,就可以应用算法逻辑,而不关心这个对象究竟是指代Mesh这样的地形图,还是方格阵列。
class AbstractGraph { public: virtual float GetWeight(int p0Index,int p1Index)=0; virtual float GetEvaDistance(int p0Index,int p1Index)=0; virtual std::vector<int>& GetNeighbourList(int pindex)=0; virtual int GetNodeCount()=0; };
对于本文距离用的Mesh,我们让他实现这个接口,这样Mesh就作为抽象基类的一个具体实现,在下文将要涉及Dijkstra算法和A*算法的逻辑中,就只见到AbstractGraph接口操作,而不会遇到和mesh的特性相关的东西。日后若要扩展寻路算法到其他种类的图上执行,只需将其他种类图的数据结构从AbstractGraph派生并实现接口即可。

class Mesh: public AbstractGraph { public: std::vector<Point3d> Vertices; std::vector<Color> Vcolors; std::vector<Triangle> Faces; std::vector<std::vector<int>> AdjacentVerticesPerVertex; int AddVertex(Point3d& toAdd) { int index = Vertices.size(); Vertices.push_back(toAdd); return index; } int AddVertex(Point3d& toAdd,Color& color) { int index = Vertices.size(); Vertices.push_back(toAdd); Vcolors.push_back(color); return index; } int AddFace(Triangle& tri) { int index = Faces.size(); Faces.push_back(tri); return index; } void CaculateAdjacentVerticesPerVertex() { AdjacentVerticesPerVertex.resize(Vertices.size()); for (size_t i = 0; i < Faces.size(); i++) { Triangle &t = Faces[i]; std::vector<int> &p0list= AdjacentVerticesPerVertex[t.P0Index]; std::vector<int> &p1list= AdjacentVerticesPerVertex[t.P1Index]; std::vector<int> &p2list= AdjacentVerticesPerVertex[t.P2Index]; if (std::find(p0list.begin(), p0list.end(), t.P1Index)==p0list.end()) p0list.push_back(t.P1Index); if (std::find(p0list.begin(), p0list.end(), t.P2Index)==p0list.end()) p0list.push_back(t.P2Index); if (std::find(p1list.begin(), p1list.end(), t.P0Index)==p1list.end()) p1list.push_back(t.P0Index); if (std::find(p1list.begin(), p1list.end(), t.P2Index)==p1list.end()) p1list.push_back(t.P2Index); if (std::find(p2list.begin(), p2list.end(), t.P0Index)==p2list.end()) p2list.push_back(t.P0Index); if (std::find(p2list.begin(), p2list.end(), t.P1Index)==p2list.end()) p2list.push_back(t.P1Index); } } public: float GetWeight(int p0Index,int p1Index) { if(p0Index==p1Index) return 0; return Point3d::Distence(Vertices[p0Index],Vertices[p1Index]); } float GetEvaDistance(int p0Index,int p1Index) { return Point3d::Distence(Vertices[p0Index],Vertices[p1Index]); } std::vector<int>& GetNeighbourList(int index) { return AdjacentVerticesPerVertex[index]; } int GetNodeCount() { return (int)Vertices.size(); } };
使用Dijkstra算法求取最短路径
学过数据结构的人都应该知道Dijkstra算法,这是最为经典的带权图寻路算法。其主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。而之后要介绍的A*算法也是在此基础上的一个启发式的改良,能够有效的减少计算遍历节点的个数。各种数据结构书和网上都有对Dijkstra算法的讲解与代码实现,不过少有详细对比二者程序结构区别的文章,而且部分文章的实现虽然简练但不宜理解,因此本文采用从一个较为形象的思路去理解算法,实现代码不求简练和高效,但求通俗易懂,并且利用了面向对象的思路去实现这一算法和A*算法。文章写的比较长,希望能覆盖到所有在实现该算法过程中可能产生疑惑的点,但愿对想了解或者回顾这个算法的人有所帮助。
1.重要的数据变量介绍——distance数组和previous数组
首先,这个算法为G中所有的节点开辟了一个distance数组和一个previous数组,很多其他的实现里distance数组就简写做d,previous数组简写成prev。下面介绍一下他们的含义。
- distance数组含义:假设图中的节点一共有n个,其中索引i表示G中第i个节点,节点间的边长类型为float,则distance数组是一个长度也为n的float数组。这个数组存储了所有节点到起点S的“当前最短距离”,即第i个节点到S的当前最短距离为distance[i],算法还没执行时,所有顶点对应的当前最短距离都是一个无穷大的数,记为MAX。
- previous数组含义:previous数组是一个长为n,类型为int的数组,其作用是可反推出S到每个节点i的最短路径。最短路径通常理解是应该用点序列来表示,例如从S到An的最短路径可以表示为S,A0,A1....An,这样我们要记录最短路径的话,似乎previous的每个元素应当是一个点序列才对。其实不然,previous只是一个长度为n的int数组,他存储的是对应节点的前驱节点索引。笔者初次接触Dijkstra算法的时候,一时半会还没能想明白为什么只需一个int数组就能记录下每个节点到S的一个最短路径。最后思考了一下,发现这样的设计是基于了如下的一个原理:
- 原理:若S,A0,A1...An是一条从S到An的最短路径,则对于最短路径上的任意一个节点Ai,S,A0,A1...Ai,也是S到Ai的一条最短路径。
- 解释:上述原理不难用反证证明:假如到Ai还有更短的其他路径,那从那条路经过Ai再到An肯定也会比S,A0,A1...An更短,与S,A0,A1...An最短矛盾。
这样的话,想要简单有效的记录路径,只需记录S到节点i最短路径在i之前的那一个节点索引,存到previous即可。previous[i]就是S到i的最短路径倒数第二个节点,又叫做i的前驱节点或者Parent节点。不难想到,要知道倒数第三个节点就算previous[i]的前驱节点,即previous[previous[i]]。这样设计可以极大程度避免存储冗余的信息,是一个非常巧妙的设计。如果要还原一条起始节点startIndex到终点节点endIndex的最短路径点序列,只需执行下列循环将每个前驱依次加入数组,再反转数组即可:
std::vector<int>& GetPath() { int cur=endIndex; while(cur!=startIndex) { resultPath.push_back(cur); cur=previous[cur]; } resultPath.push_back(startIndex); //resultPath是用来保存路径上的节点的数组 std::reverse(resultPath.begin(),resultPath.end()); //反转数组,因为节点是从后往前加进去的 return resultPath; }
2.主循环逻辑解释——节点类别与类别间的转换操作
在算法开始之前,我们只知道S到S的最短距离是0,即distance[S]=0,而其他的包括终点E在内的所有点到S的距离都是不知道的,所以将他们都初始化为MAX。previous数组则全部初始化为-1,因为S不需要前驱,其他的点前驱还没算出来。
算法的主逻辑是一个while循环,该循环始终围绕着一个容器Q进行,这个容器初始时候只包含S,然后随着循环的执行,不断的有节点进入Q和从Q中弹出,直到Q为空或者遇到终点E为止。下面的GIF显示了Dijkstra算法的循环过程,其中不同的节点颜色代表节点的当前类别,可以看出Dijkstra算法是从S出发不断的向外扩充寻找的过程,在这个过程中节点的类别也不断变化。所以下面将详细解释算法的主循环如何执行,节点的类别究竟是怎么回事,类别又是如何变化的。
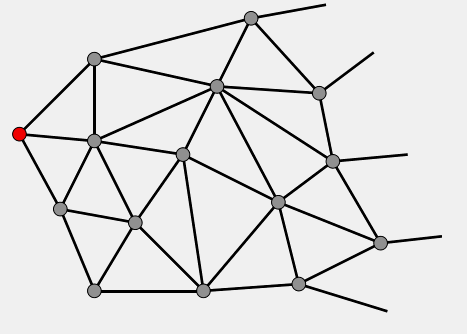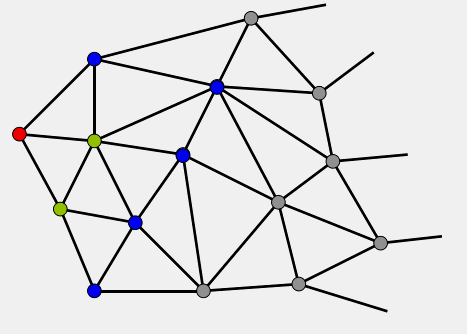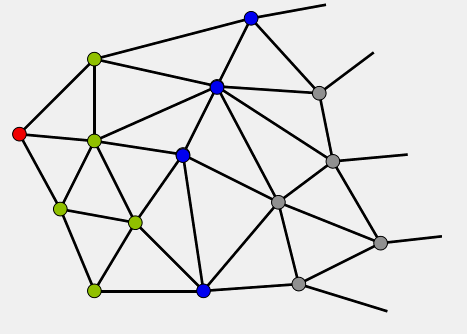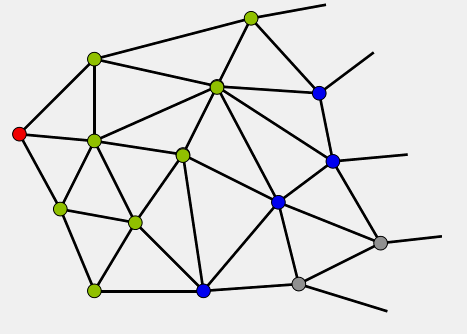 |
 |
| Dijkstra算法ABC三类节点扩展动画 | 说明(不好意思这个终点没标出来,不过可以认为它在千里之外..) |
算法在执行循环迭代的过程中,其实是将图中的节点分成了如下三类,上文GIF中的“绿”“蓝”“灰”即对应着节点的类别:
- 第一类节点,是GIF中的绿色节点,简称Type A,又可以叫做“闭节点”。这一类节点的特点是它们已经知道自己到起点S的最短路径,“知道路径”的含义是既知道到S的最短路径的长度,也知道该怎么走。假如终点E成为A类节点,那么算法的任务就完成了。算法迭代的过程就是A类节点不断增加的过程。
- 第二类节点,是GIF中的蓝色节点,简称Type B或者可以叫做“候选节点”、“开节点”,这一类节点的特点如下:
- B类节点是从A类节点由邻居关系找到的,因而G中所有A类节点的非A类邻居都属于B类节点。
- B类节点已经有一条到S的“当前最短路径”,这个路径可能是实际最短的,也可能不是。
- B类节点对应的distance都已不是MAX,而是一个小于MAX的数。
- 随着算法继续运行,这些B类节点的distance可能会被更小的值代替。用新的更小的distance代替旧的distance的操作又被称作“松弛操作(Relaxation)”。
- 在算法执行过程中,这类节点一定处在容器Q中,容器Q中的节点也都是B类节点。Q中的B类节点通过容器的ExtractMin操作弹出并转化为A类节点。
- 算法开始时起点S被加入容器Q作为第一个B类节点,随后他会被弹出并标记为A类,他的邻居们则被加入容器Q作为新的B类节点。
- 第三类节点,是GIF中的灰色节点,简称Type C,这类节点是算法迭代中还没有访问过的节点,这类节点的特点是:
- C类节点的对应distance都是MAX。
- 在进入主循环之前,除了S之外所有的所有节点都是C类。
- 一个C类节点一旦被第一次次访问到,由于其distance是MAX,所以“松弛操作”一定能够对其执行。执行之后该C类节点即转化为B类节点。
算法每一次循环都会将一个B类节点转为成A类节点,然后将这个B类节点的C类邻居转为B类,直到容器为空或者终点E被转为A类节点为止。由B变为A的核心操作为容器的ExtractMin;松弛操作则既可对B类节点执行,也可对C类节点执行,对C类执行时则将C类节点变成了B。节点类型和操作的关系图可以使用下图直观的展示:
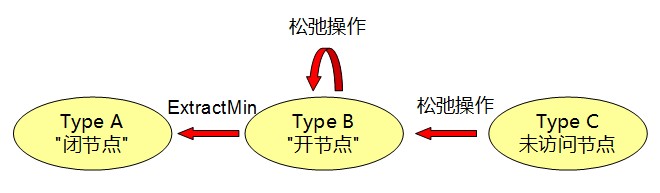
ExtractMin操作和松弛操作的具体行为如下:
- ExtractMin操作:操作对象为容器。从在容器中的B类节点中选择一个具有最小distance的节点,从容器中删除改节点并返回它。这个操作就好比是这个容器的选择器一样,他的作用就是选择。选择的原则是distance最小。
- 松弛操作:操作对象为两个节点p、q。对与节点p相邻的节点q,求出经过p再到q的距离,即distance[p]+edge(p,q),若这个值比q的当前最短距离更小,则更新q他们的当前最短距离为distance[p]+edge(p,q),更新q的前驱为p,否则什么也不做。
在阅读了上述说明之后读者或许会产生这样的一个问题:为何ExtractMin所返回的节点可以认为找到了最短路径,就能直接转为A类节点?
- 解释:首先我们我们知道所有的B类节点都处在容器中,他们全都是A类节点的直接邻居,他们的当前最短路径的前驱必是一个A类节点。假设节点i是目前在B类节点中distance最小的节点,那么他的当前最短路径一定是实际最短路径。这可以用反证说明:不妨假设它的当前最短路径不是实际最短,那么实际最短应该是经过另外一个B类节点x再到i。而通过x到i需要的路程为distance[x]再加上一条长度肯定是正数值的x到i的路线,又因为已经有distance[x]>distance[i],所以经过x的路程肯定大于distance[i],即不可能最短。所以到i的最短路径就是当前记录在distance[i]和previous[i]的这条,不可能再有别的。或者我们反过来想,假如不选择i变为A类,而选择另一个x节点变为A类,那么万一有一条从i到x的路径满足 d(i,x)+distance[i]<distance[x],这样的话这条从i绕的路径就更短了,所以x节点变为A类是不合理的,只有i才能变为A。
- 注意:上述解释基于的假设是G中所有边都是正权值,若带有负权值上述解释则不成立,这也是为什么Dijkstra算法不适用于带负权图的原因。
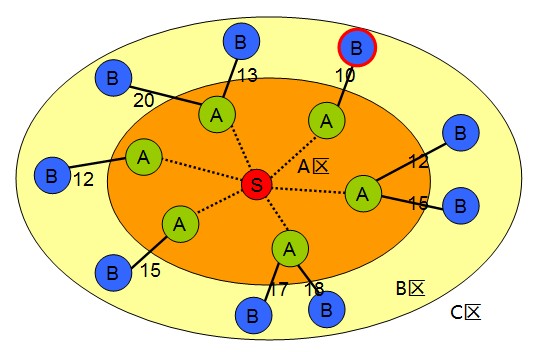 |
|
举例如上图,带红圈的B为当前所有B类节点中具有最短到S距离的节点,路径长度为10,不可能存在一条 比10更小的通往红圈B的路,因为这些路必然经过其他的B,而到S其他B的路径已然比10长。 |
为了标记一个节点是A类节点,可使用一个bool数组类型变量flagsmap_close来实现,节点i为A类节点,只需简单设置flagsmap_close[i]=true即可,初始情况flagsmap_close则全部为false。存储B类节点的容器Q由于需要支持不断的从中获取distance最小的节点操作,因此可以采用“堆”(Heap)来实现。C类节点的特征明显,一个节点i的当前最短距离distance[i]若等于MAX,则该节点即为C类节点,一旦distance[i]被置为小于MAX的值,则意味着此节点类型由C转成B。在明白了Dijkstra算法的主循环逻辑,已经相应的3种节点类型和2种转化操作之后,可以用下面的伪代码来描述算法的主逻辑。
输入:图G,起点S,终点E 初始化distance数组为MAX 初始化previous数组为-1 初始化flagsmap_close数组为false; 初始化集合Q 将S加入Q While(Q不为空) { p=Q.ExtractMin();//执行ExtractMin操作 flagsmap_close[p]=true;//设置p为A类节点 if(p为终点E){跳出循环结束函数;} 对p的所有邻居n { if(flagsmap_close[n]==true) //若n为A类节点 {continue} else if(distance[n]!=MAX) //若n为B类节点 { 对<p,n>执行松弛操作。 } else //若n为C类节点 { 对<p,n>执行松弛操作,此操作无需判断小于distance[n],因为distance[n]是MAX。 } } }
咋一看这还离实现细节差的远,不过不要拙计,由于本文的核心是实现基于堆的Dijkstra算法,所以在引入正式的算法代码之前,还需要介绍一下算法使用的这个堆,因为它和一般的堆还有一些不一样的地方。
3.容器Q的实现—线性表与堆的实现中的统一和区别以及Dijkstra算法中堆的特殊性
从上述算法中发现了一个很重要的问题,即容器Q的实现问题。容器Q中始终存储着所有的B类节点,并且需要支持频繁的ExtractMin操作,有数据结构基础的读者不难想到堆是一个实现这个容器的很好选择。在网上搜的Dijkstra算法有很多的版本,大多数的版本中容器Q是基于线性表实现的。我们必须明确这一点:无论容器Q是采用什么样内部实现,它必须有统一的外在表现。根据上文的伪代码,我们发现容器Q至少需要支持下列操作:
- Add操作,Q支持将节点索引p加入Q中。
- IsEmpty操作,Q支持判断是否为空。
- ExtractMin操作,Q支持找出distance值最小的节点p索引并返回之。
使用线性表来实现Q是一种最简单直观的方式,我们将实现的代码写成下面的模样,其中DijkstraSet_Linear类就是对Q的一个实现:
class DijkstraSet_Linear { private: std::vector<int> linearContainer; std::vector<float>* distance_key; public: DijkstraSet_Linear(int maxsize,std::vector<float>* key) { this->distance_key=key; } ~DijkstraSet_Linear(){distance_key=0;} void Add(int pindex) { this->linearContainer.push_back(pindex); } int ExtractMin() { int insetIndex=GetMinIndex(); int ret=linearContainer[insetIndex]; RemoveAt(insetIndex); return ret; } bool IsEmpty() { return linearContainer.size()==0; }
private: void RemoveAt(int index) { linearContainer[index]=linearContainer[linearContainer.size()-1]; linearContainer.pop_back(); //swap element to the end then pop it } int GetMinIndex() { //execute O(N) process to find min distance float min=MAX_DIS; int index=-1; for(size_t i=0;i<linearContainer.size();i++) { if((*distance_key)[linearContainer[i]]<min) { min=(*distance_key)[linearContainer[i]]; index=i; } } return index; } };
从上述代码可以看出,distance数组的值作为Q需要使用的比较关键字,他的地址直接通过构造函数被传入了DijkstraSet_Linear类内部。DijkstraSet_Linear类包含一个数组成员linearContainer用来存放Add进来的节点索引,函数GetMinIndex通过顺序搜索容器中的索引来找到distance值最小的索引位置。ExtractMin操作从linearContainer中删除并返回了该索引。注意这个删除和一般顺序容器删除不同,无需循环移动元素保持先后顺序,只需将待删除的位置的元素和最后一个元素交换并popback即可。可以看出整个实现逻辑并不复杂,顺序搜索的开销是Q中B节点的总数,这个总数是动态变化的。
采用二叉堆来实现Dijkstra算法是本文的重点,所以这里重点讲述如何用堆来实现集合Q,这之中涉及到很多需要注意的小问题。
“堆”是一种被广泛使用的数据结构,在各种需要快速求得集合极值的场合往往都能见到它的身影。对它最为简单普遍的实现叫做“二叉堆(Binary Heap)”,二叉堆采用完全二叉树来表示,完全二叉树又是采用线性表来表示的。二叉堆的原理网上和书上有太多的介绍,原理也不难,调整的过程很形象直观。因此本文假定读者已经有了这方面知识储备,本文就不对堆内部的各种调整操作做原理介绍,诸如GetParent、GetLeftChild、GetRightChild、ShiftUp、ShiftDown这类操作的作用和细节都假设读者是明白的,这样我们就把重点放在用于Dijkstra算法的堆和一般的堆的区别上。
在Dijkstra算法中,我们需要实现的二叉堆和一般的二叉堆有相似也有不同。在各种语言的标准库或者第三方数据结构库中,一般都有堆的实现(有时也被称为优先级队列),这些堆一般都至少支持Add操作和ExtractMin操作。假如我们能够将这些标准的堆实现应用到我们的算法中,那将会很省事,但遗憾的是,这些封装好的堆实现往往难以满足我们的要求,这是因为Dijkstra算法在与堆数据结构打交道时产生了如下特殊的情况,导致这个堆数据结构的外部表现和内部实现和一般的堆有所不同:
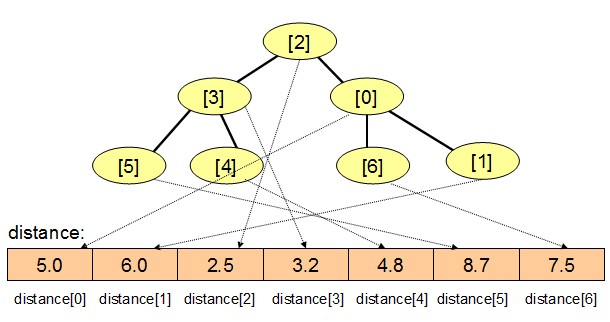
- 外部表现的不同:Dijkstra算法的堆中存储着一系列节点索引值,但其关键的key值则存储在distance数组中因而暴露在外。众所周知,堆会根据key值为对应的节点安排合适的堆内位置,key值的变化会影响对应节点的堆内位置,在不变化节点堆内位置的情况下改变key,会破坏堆特性并导致错误。而在松弛操作中我们知道节点n的distance的值会被更新为新的更小的值,这样原本存在堆上的n,其在堆中的位置就可能有所变化。因此,这个堆结构需要给外界调用者暴露一个方法DecreaseKey,每次在松弛操作更新n的distance中还需调用Q.DecreaseKey(n)。
- 内部实现的不同:为了实现DecreaseKey并保证效率,堆还必须要内置一个哈希表indexInHeap,用来查询n在堆中的索引。因为无论是ShiftUp操作还是ShiftDown操作,其操作参数都是堆内索引,而不是n。所以需要知道n在堆内的什么位置,然后再将这个位置拿去调用ShiftUp,这就是为何需要哈希表indexInHeap的原因,而一般的通用库中的堆往往不会实现DecreaseKey,也就没必要使用哈希表indexInHeap。
 |
 |
|
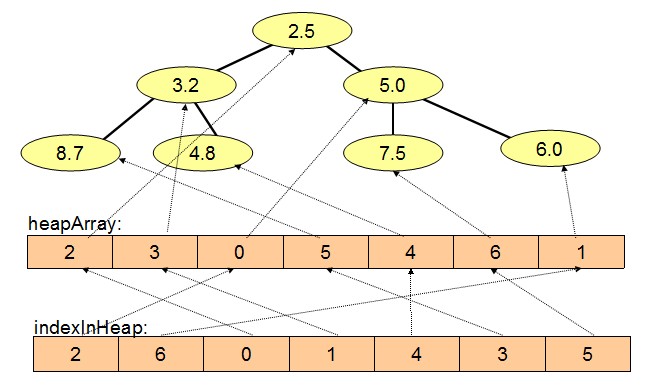
上面两图示意Dijkstra的堆在依次加入节点6、5、4、3、2、1、0之后的堆情况,左图显示堆上的节点索引,右图显示堆上的distance数值,可以看出节点2由于distance值最小因而处在堆最高的位置。假如需要对节点0更新更小的distance的值,例如5.0修改为1.0,则堆的DecreaseKey操作先根据indexInHeap数组找到节点0在堆中的索引indexInHeap[0]为2,然后调用ShiftUp(2)操作将的节点0调整到堆顶。 |
|
说了一大堆不如来看实现,下面的C++类DijkstraSet_Heap就是实现二叉堆的代码:
class DijkstraSet_Heap { private: std::vector<int> heapArray; std::vector<float>* distance_key; std::vector<int> indexInHeap;// stores the index to heapArray for each vertexIndex, -1 if not exist public: DijkstraSet_Heap(int maxsize,std::vector<float>* key) { this->distance_key=key; this->indexInHeap.resize(maxsize,-1); } ~DijkstraSet_Heap(){distance_key=0;} void Add(int pindex) { this->heapArray.push_back(pindex); indexInHeap[pindex]=heapArray.size()-1; ShiftUp(heapArray.size()-1); } int ExtractMin() { if(heapArray.size()==0) return -1; int pindex=heapArray[0]; Swap(0,heapArray.size()-1); heapArray.pop_back(); ShiftDown(0); indexInHeap[pindex]=-1; return pindex; } bool IsEmpty() { return heapArray.size()==0; } void DecreaseKey(int pindex) { ShiftUp(indexInHeap[pindex]); } private: int GetParent(int index) { return (index-1)/2; } int GetLeftChild(int index) { return 2*index+1; } int GetRightChild(int index) { return 2*index+2; } bool IsLessThan(int index0,int index1) { return (*distance_key)[heapArray[index0]]<(*distance_key)[heapArray[index1]]; } void ShiftUp(int i) { if (i == 0) return; else { int parent = GetParent(i); if (IsLessThan(i,parent)) { Swap(i, parent); ShiftUp(parent); } } } void ShiftDown(int i) { if (i >= heapArray.size()) return; int min = i; int lc = GetLeftChild(i); int rc = GetRightChild(i); if (lc < heapArray.size() && IsLessThan(lc,min)) min = lc; if (rc < heapArray.size() && IsLessThan(rc,min)) min = rc; if (min != i) { Swap(i, min); ShiftDown(min); } } void Swap(int i, int j) { int temp = heapArray[i]; heapArray[i] = heapArray[j]; heapArray[j] = temp; indexInHeap[heapArray[i]]=i;//record new position indexInHeap[heapArray[j]]=j;//record new position } };
可以看出和DijkstraSet_Linear相比,public方法多出了DecreaseKey操作。内部实现多出了indexInHeap数组用作哈希表使用。private方法诸如GetParent、ShiftUp、ShiftDown等操作都是堆的基本操作,其工作原理不做赘述。为了实现容器Q的外部行为上的统一,我们实现抽象类DijkstraSet,让DijkstraSet_Linear与DijkstraSet_Heap都派生于这个抽象类,统一他们的操作行为,就像我们对Mesh类做的事情一样。
/** \brief Dijkstra set. parameter pindex represents the id(index) of a certain graph node, */ class DijkstraSet { public: virtual void Add(int pindex)=0;// required operations, add new pindex into set virtual int ExtractMin()=0;// required operations, remove and return the pindex which has the minimum distance virtual bool IsEmpty()=0;// required operations, return true if the element count in set==0 virtual void DecreaseKey(int pindex)=0;// necessary if implemented as a heap, when update shorter distance :dist[v]=dist[u] + dist_between(u, v) ; };
4.Dijkstra算法的C++面向对象实现
在依次介绍了Graph的实现,算法主逻辑与容器Q的实现后,我们就可以着手实现代码了。首先我们根据上面的描述给出一份完整的Dijkstra算法伪代码如下:
- Function_Dijkstra(图Graph,起点S,终点E)
- 初始化distance数组为MAX。
- 初始化previus数组为-1。
- 初始化flagsmap_close数组为false。
- 初始化集合Q。
- 初始化distance[S]=0。
- 将S加入Q。
- While(Q不为空)
- P=Q.ExtractMin(),即找到Q中Distance值最小的点P。
- flagsmap_close[p]=true,即设置P为A类节点。
- 若P==E
- 找到终点,算法结束。
- 对P的所有邻接点n
- 若n为A类节点,即有flagsmap_close[n]==true
- continue继续循环。
- 否则
- 计算从S通过P到n的路径长度:distancePassP=distance[P]+Weight(P,n)。
- 若n为B类节点,即有distance[n]!=MAX
- 若distancePassP<distance[n]
- 将distance[n]更新为distancePassP。
- 将previous[n]更新为P。
- 若容器为堆则找到n在堆中的位置并调整之。
- 若distancePassP<distance[n]
- 否则n为C类节点,即distance[n]==MAX
- 将distance[n]更新为distancePassP。
- 将previous[n]更新为P。
- 将n加入Q。
- 若n为A类节点,即有flagsmap_close[n]==true
- 算法结束,若进行到此步则说明未找到终点E
用C++实现算法,首先定义算法执行类GeodeticCalculator_Dijk。其中参数Graph,S,E分别作为构造函数参数传入类中成为数据成员。同时根据上文的介绍,还需要distance数组和previous数组作为数据成员。FlagsMap_Close与DijkstraSet分别是存放A类节点与B类节点的容器,以及其他用作辅助的数据成员,算法主体逻辑主要体现在Execute函数与 UpdateNeighborMinDistance函数中,GetPath为基于previous数组重建路径的函数。
#ifndef GEODETICCALCULATOR_DIJKSTRA_H #define GEODETICCALCULATOR_DIJKSTRA_H #include <vector> #include <math.h> #include "Mesh.h" #include "DijkstraSet.h" class GeodeticCalculator_Dijk { private: AbstractGraph& graph; int startIndex; int endIndex; std::vector<int> previous;//previous vertex on each vertex's s-path std::vector<float> distance;//current s-distances for each node std::vector<bool> flagMap_Close;//indicates if the s-path is found, return true if is closed node DijkstraSet* set_Open;//current involved open vertices, every vertex in set has a path to start point with distance<MAX_DIS but may not be s-distance. std::vector<bool> visited;//record visited vertices; not necessary std::vector<int> resultPath;//result path from start to end public: GeodeticCalculator_Dijk(AbstractGraph& g,int vstIndex,int vedIndex):graph(g),startIndex(vstIndex),endIndex(vedIndex) { set_Open=0; } ~GeodeticCalculator_Dijk() { if(set_Open!=0) delete set_Open; } //core functions bool Execute()//main function execute Dijkstra, return true if the end point is reached,false if path to end not exist { this->distance.resize(graph.GetNodeCount(),MAX_DIS); this->previous.resize(graph.GetNodeCount(),-1); this->flagMap_Close.resize(graph.GetNodeCount(),false); this->visited.resize(graph.GetNodeCount(),false); this->set_Open=new DijkstraSet_Heap(graph.GetNodeCount(),&distance); set_Open->Add(startIndex); distance[startIndex]=0; while(!set_Open->IsEmpty()) { int pindex=set_Open->ExtractMin();// vertex with index "pindex" found its s-path flagMap_Close[pindex]=true;//mark it as closed if(pindex==endIndex)//if found end point return true; UpdateNeighborMinDistance(pindex);// update its neighbor's s-distance } return false; } private: //core functions void UpdateNeighborMinDistance(int pindex)// for neighbors of pindex ,execute relaxation operation { std::vector<int>& nlist=graph.GetNeighbourList(pindex); for(size_t i=0;i<nlist.size();i++ ) { int neighborindex=nlist[i]; visited[neighborindex]=true;//just for recording , not necessary if(flagMap_Close[neighborindex])//if Close Nodes,Type A { continue; } else { float distancePassp=distance[pindex]+graph.GetWeight(neighborindex,pindex);//calculate distance if the path passes p if(distance[neighborindex]==MAX_DIS) //if unvisited nodes ,Type C { distance[neighborindex]=distancePassp;//update distance previous[neighborindex]=pindex;// record parent set_Open->Add(neighborindex);//newly approached vertex is pushed into set } else// if is open node ,Type B { if(distancePassp<distance[neighborindex])//test if it's s-distance can be updated { distance[neighborindex]=distancePassp;//update distance previous[neighborindex]=pindex;// record parent set_Open->DecreaseKey(neighborindex);// vertex with index "neighborindex" update its s-distance //,since the distance value is a key in heap, it's position in heap should also be updated. // if the set is not implemented as a heap, this operation can be omitted } } } } } public: //extra functions std::vector<int>& GetPath() { int cur=endIndex; while(cur!=startIndex) { resultPath.push_back(cur); cur=previous[cur]; } resultPath.push_back(startIndex); std::reverse(resultPath.begin(),resultPath.end()); return resultPath; }// reconstruct path from prev[] float PathLength() { return distance[endIndex]; }//return the length of the path form result path std::vector<bool>& GetVisitedFlags() { return visited; }//return the visited flags of the nodes int VisitedNodeCount() { return (int)std::count(visited.begin(),visited.end(),true); }//return the visited nodes count }; #endif
使用这个C++算法类处理Mesh,可以得到一个最短距离,也就是我们要的近似测地线距离,下图展示了算法的运行结果:
 |
 |
| Dijkstra算法对Mesh的运行结果,染成绿色的节点是算法遍历过的节点,黑色为最短路径,蓝色为起点,红色为终点 |
与Wiki上伪代码思路的对比
网上有各种不同的Dijkstra算法的实现,例如维基百科上的伪代码,是比较权威的实现思路了。

可以发现,这里的集合S等价于我们的flagsMap_Close,用以标记A类节点。Q等价于我们的容器Q。该伪代码并没有像本文一样如此明显的突出3类节点的区别。事实他的做法是把节点分为了2类。B类和C类节点由于存在一定相似性,C类节点可以看成是到S有一条路径,只是路径为MAX的B类节点。我们其实可以统一对待B类与C类节点。d[v]>d[u]+w(u,v)涵盖了d[v]可能是MAX(C类节点)和非MAX(B类节点)的情况、即无论是C还是B,只要是更小的值就更新之。不过既然本文的写作动机是不求代码简练高效,而是有助于新接触算法的人形象理解,所以倾向于细分所有具有不同特点的节点。
还有一个值得注意的地方是容器Q的使用,假如如上文所述把B类与C类节点统一对待不加区分,那么这个容器Q在初始的时候需要将所有节点都装入,形成一个体积较大的容器。此时这个容器就不再需要add操作了,因为所有B类C类节点都已经在Q中。每次找最小,由于C类的distance都是MAX,所以Q中弹出的节点也是符合最短原则的B类节点,这样子使用Q也是一样能得出结果。不过若采用线性表来实现这个Q,那么每次顺序搜索的开销就不是Q中B类节点的个数了,而是B+C的总数,因此这样的Q设计其实不如本文的设计更高效。
其他说明
我没想到会扯这么多,本来是想把A*也在一篇文章中讲完,然后对比,后来发现太长不好,就干脆把把这篇文章改为Part1,下篇文章就是Part2。下篇文章会采用与Dijkstra类似的方式实现A*并应用之,由于A*算法涉及的一些概念有不少在这篇文章里讲了,相当于Part1为Part2铺了一个路。这样说起来也更容易。
本文代码工程下载:https://github.com/chnhideyoshi/SeededGrow2d/tree/master/MeshGeodetic
其中那有几个PLY三角网格文件可以使用MeshLab查看,也是项目main的测试输入。
爬网的太疯狂了,转载本文要注明出处啊:http://www.cnblogs.com/chnhideyoshi/p/Dijkstra.html


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 对象命名为何需要避免'-er'和'-or'后缀
· SQL Server如何跟踪自动统计信息更新?
· AI与.NET技术实操系列:使用Catalyst进行自然语言处理
· 分享一个我遇到过的“量子力学”级别的BUG。
· Linux系列:如何调试 malloc 的底层源码
· JDK 24 发布,新特性解读!
· C# 中比较实用的关键字,基础高频面试题!
· .NET 10 Preview 2 增强了 Blazor 和.NET MAUI
· SQL Server如何跟踪自动统计信息更新?
· windows下测试TCP/UDP端口连通性