
SQL SERVER的锁机制(四)——概述(各种事务隔离级别发生的影响)
SQL SERVER的锁机制(一)——概述(锁的种类与范围)
SQL SERVER的锁机制(二)——概述(锁的兼容性与可以锁定的资源)
本文上接SQL SERVER的锁机制(三)——概述(锁与事务隔离级别)
六、各种事务隔离级别发生的影响
修改数据的用户会影响同时读取或修改相同数据的其他用户。即这些用户可以并发访问数据。如果数据存储系统没有并发控制,则用户可能会看到以下负面影响:
· 未提交的依赖关系(脏读)
· 不一致的分析(不可重复读)
· 幻读
(一)脏读:
例:张某正在执行某项业务,如下:
begin tran insert tbUnRead select 3,'张三' union select 4,'李四' ---延迟秒,模拟真实交易情形,用于处理业务逻辑 waitfor delay '00:00:05' rollback tran ---此时李某对表中数据进行查询,执行了以下语句: set Transaction isolation level read uncommitted --查询数据 select * from tbUnRead where name like '张%'
则李某可以看到张某所执行的插入语句,把数据添加到了数据库,如下图。
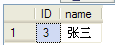
但是张某最终是没有提交事务,而是回滚了事务,所以这条记录并没有真正插入到数据库中。从而发生李某将脏读的数据当成真实的查询结果。
要解决此问题,就是要把数据库的事务隔离级别由未提交读修改成已提交读。只有当查询结果的正确性不是非常重要,或者是隔一段时间查询一次情况下,即使这一次查询结果是错,而下次查询结果是对的,并不会有太大影响,这才适合使用未提交读。
(二)不可重复读
例:张某正在查询数据,如下
set Transaction isolation level read committed begin tran select * from tbUnRead where ID=2 ---延迟秒,模拟真实交易情形,用于处理业务逻辑 waitfor delay '00:00:05' select * from tbUnRead where ID=2 commit tran ---此时李对表中数据进行了更新,如下语句: update tbUnRead set name='Jack_upd' where ID=2
上面的执行语句造成张某在同一个事务内,两次相同的查询条件,查询到不相同的结果(如下图)。
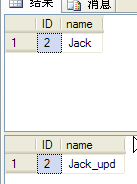
这是由于“已提交读”隔离级别对共享锁保留的时间是:一旦查询完毕就立即释放,而非事务完成才释放。所在张某虽然还在使用事务,事务过程中的所有独占锁都会一直保留,让事务中所更改的数据别人不可进行查询与更改,直到事务完成。但是,被查询的数据在事务过程中是查询完毕就立即释放共享锁,所以别人仍然可以进行修改,造成一笔事务中,两次相同的查询条件,可以得到不相同的结果。最佳的解决方案是将隔离级别设置为“可重复读”。
“可重复读”事务隔离级别,让事务过程中所曾经建立的共享锁都一直保留到事务完成,虽然可以避免“不可重复读”的问题,但是也会导致数据锁定太久,而别人无法读取数据,影响并发率,甚至提高了“死锁”的发生率。
(三)幻读
例:张某正在查询数据,如下
set Transaction isolation level REPEATABLE READ begin tran select * from tbUnRead where ID=3 ---延迟秒,模拟真实交易情形,用于处理业务逻辑 waitfor delay '00:00:05' select * from tbUnRead where ID=3 commit tran --此时李某新增了一条记录,如下语句: INSERT TBUNread select 3,'幻读'
张某已经把隔离级别设置为“可重复读”,虽然是曾经读取的数据,不管是共享锁还是互斥锁都 保留到了事务结束,但是无法阻止其他人运行新增操作,导致第一次查询时没有数据,第二次查询时却有了数据。被称为“幻读”。如下图。
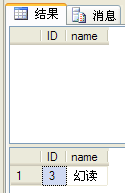
为了避免此类问题,可以将隔离级别设置为“可序列化”,设置之后,则其他人则无法新增数据。
七、各隔离级别所能防止的访问错误
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
|
未提交读 |
是 |
是 |
是 |
|
已提交读 |
否 |
是 |
是 |
|
可重复读 |
否 |
否 |
是 |
|
快照 |
否 |
否 |
否 |
|
可序列化 |
否 |
否 |
否 |
八、常用锁与事务隔离级别间的交互影响
|
已提交读 |
可重复读 |
快照 |
可序列化 |
|
|
共享 |
读完数据后就释放 |
事务结束才释放 |
不加锁,以版本来控制 |
事务结束才释放 |
|
更新 |
读完数据后就释放或是升级成独占锁 |
读完数据后就释放或是升级成独占锁 |
不加锁,以版本来控制 |
读完数据后就释放或升级成独占锁 |
|
独占 |
事务结束才释放 |
事务结束才释放 |
不加锁,以版本来控制 |
事务结束才释放 |
九、动态锁定管理
数据库引擎使用动态锁定管理策略来控制锁定和系统的最佳成本效益。数据库引擎可以动态调整数据粒度与锁定类型,当使用最低一级的行锁而非更大范围的页锁时,可以降低两个事务要求相同范围的数据锁定的可能性,增强并行访问的能力,可同时服务更多的用户,减小死锁的机率。相反低级锁转为高级锁可以减小系统的资源负担,但会增加并行争用的可能性。
此机制由锁管理器进行管理,每一个锁都需要内存去记录,并且要与锁管理器进行合作,才能完成数据访问操作,你可以想像当表中有100万条记录时,你执行一条没有where语句的update指令时,在默认情况下数据库引擎会采用行锁,但这要记录100万条行锁记录,以及相关的意向共享锁,必定会消耗掉大量的系统资源,当系统资源不足时,数据库引擎会自动提升锁的级别,也就是由行锁提升为页锁,如果资源还是不足,则会再次提升,提升为表锁。
就以上例子来说,如果每个页可以放200条记录,则100万表记录的行锁转为5000个页锁,还省掉了大量的意向共享锁。如果资源还是一足,则可以再次提升锁级别,提升到表锁,这样就只需要一个锁就可以了。
愈大范围的锁花费在管理锁之上的资源就愈少。但相对来说,同时上线并发访问该资源的人数就越少。例如:或采用行锁,则你访问你的记录,我访问我的记录,互相不影响,但如果升级到页锁,则如果你先抢到该分页,而我要访问的记录又恰恰在这一分页上,则我必须要等你释放该分页之后才能访问。如果升级到表锁,则同一时间,该表中的记录只能一个人才能访问,其他人不能访问。如下图。
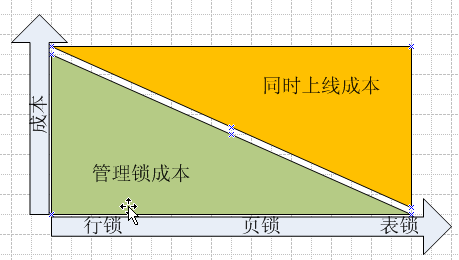
一般情况下,是不需要手工去设置锁定范围的,可以由Microsoft SQL Server 数据库引擎视情况而定,使用动态锁定策略确定最经济的锁。 执行查询时,数据库引擎会根据架构和查询的特点自动决定最合适的锁。 例如,为了缩减锁定的开销,优化器可能在执行索引扫描时在索引中选择页级锁。
动态锁定具有下列优点:
· 简化数据库管理。 数据库管理员不必调整锁升级阈值。
· 提高性能。 数据库引擎通过使用适合任务的锁使系统开销减至最小。
· 应用程序开发人员可以集中精力进行开发。 数据库引擎将自动调整锁定。
在 SQL Server 2008 中,锁升级的行为已发生改变,其中引入了 LOCK_ESCALATION选项

 浙公网安备 33010602011771号
浙公网安备 33010602011771号