(三)索引分区知识详解
一、与表分区对齐
在了解索引分区之前,需先了解下分区索引与表对齐的概念,若分区与表使用相同的分区架构和相同分区依据列,则说明分区与表的分区方式相同,我们称为对齐,反之则不对齐。
对于已分区的与表对齐的分区索引,在排序的时候,将一次性在内存或者tempdb中生成排序表;若是不与分区表对齐,将在每个分区同时生成排序表,因此所需内存空间会更多。每个排序表占用最小40KB空间,对齐索引分区将只是占用40kb,非对齐若有100个分区将占用40*100kB空间。因此是否对齐将直接影响排序性能。
同时对于不对齐的索引,将无法完成分区切换的动作,无法实现分区的子集快速管理。
新建PartionTest01以下分区表进行索引测试:

--新建测试表 CREATE TABLE PartionTest01(logid int identity(1,1),orderid int,salesDate datetime) ON pc_PartionTest01([salesDate])--指定分区方案 --查询分区情况 SELECT Object_name(p.object_id) AS [object_name], id.name AS index_name, ps.name partition_scheme, ds.name filegroup, pf.name partition_function, pf.type_desc+':'+case when pf.boundary_value_on_right=0 then 'Left' else 'Rigth' end function_type, p.partition_number, Isnull(prv.VALUE,'') AS boundy_value, p.rows FROM sys.indexes id JOIN sys.partition_schemes ps ON ps.data_space_id = id.data_space_id JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id JOIN sys.data_spaces ds ON ds.data_space_id = dds.data_space_id JOIN sys.partitions p ON p.object_id = id.object_id AND p.index_id = id.index_id AND dds.destination_id = p.partition_number JOIN sys.partition_functions pf ON ps.function_id = pf.function_id LEFT JOIN sys.partition_range_values prv ON prv.function_id = pf.function_id AND prv.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE Object_name(id.object_id) = 'PartionTest01'
查询结果如下:

二、聚集索引分区
测试一:对于非唯一聚集索引分区时,若未在聚集键明确指定分区列,默认将在聚集索引键列表中添加分区依据列

测试二:对于唯一聚集索引分区时,必须添加分区依据列,如下报错。添加分区依据列之后新建成功,只有添加了分区依据列才能在单个分区保证唯一。

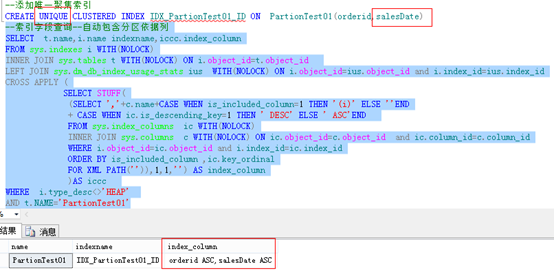
三、非聚集索引分区
测试一:非唯一非聚集索引,自动包含分区依据列为键列。
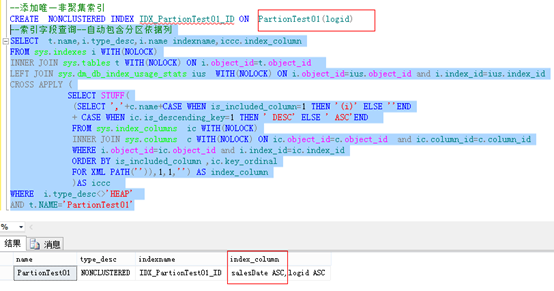
测试二:唯一非聚集,仍然需要指定分区依据列。

测试三:指定包含分区依据列,可成功

结论
- 新建唯一索引都需要明确指定分区依据列,以确保表中不存在重复的键值。
- 新建非唯一索引若未明确指定分区依据列,则会自动将分区依据列指定为索引键列
- 新建包含非唯一非聚集索引,将不会再添加分区依据列为索引键列。
分类:
SQL Server 分区设计


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构