


本人翻译 http://sourceforge.net/apps/trac/aperture/wiki/RDFUsage
Aperture框架大量使用RDF graphs在组件之间交流信息,例如,Extractors作为RDF模型返回它抽取的文本和元数据,而Crawlers对通过采集获取的原文内容和元数据做同样的处理
使用RDF的理由是,我们想要一种易于表达的并且灵活的方式来让这些组件交流它们的结果。相较java Map等而言,RDF模型允许更富于表现力的信息模型,使未来的API实现采用一种不带任何假设的高级别的粒度来导出元数据
Aperture组件交流它们抽取的元数据使用来自于Nepomuk Information Element Ontology Framework的词汇,它力求统一各种元数据标准(OpenDocument, DublinCore, XMP, Freedesktop XESAM etc.)到一个单一的框架。它旨在简化在aperture上的应用程序的开发。为了获益于在未来出现的Aperture组件他们将只需要“理解”NIE,并且不支持超出的更多的元数据标准。
RDFContainer
RDF的功能强也是其主要的弱点:RDF模型可以是复杂的处理,相较于Java的Map。他们在大型的java社区也是一个相对较新的标准,这可能是对那些考虑扩展和改进Aperture新的开发人员是一种负担。没有统一的API处理RDF模型,就像对XML文档(DOM,SAX)。相反的,一些竞争的事实上的标准的存在,各有其利弊。这些系统也往往把重点放在具体的使用情况下,如本体工程,存储和查询,从而导致一种复杂和专门的API。例如,Sesame的仓库API处理如交易,上下文等概念。(RDF2Go试图解决这些问题,但他们不会在立刻消失。)对于一个简单的用例如Extractor实现,你不希望你的实现甚至不必考虑这些问题。这些应该是应用程序级别的事项,而不是框架层面事宜。
因此,我们开发了一个简单的称为RDFContainer的API RDF模型。它包含了一组易于理解的模仿map API的方法,同时仍然允许以简单的方式添加任意的RDF陈述。我们尝试使我们的系统避免过于复杂,在我们所想象的 与我们所需要的 找到一个平衡。RDFContainer实例是通过,如Extractor和DataAccessor实现 把所有的元数据中存入。
RDFContainer建立于支持Java核心类型,如整数,布尔和日期。这减轻了开发人员在整个系统的这些数据类型转换中,弄清楚如何以统一的方式将这些数据类型转换为RDF 部分 的负担。
简单添加方法
通常情况下,我们并不需要存储复杂的图形来表达必要的信息。在许多情况下,我们真正需要的是一个简单的哈希映射的功能,这将使我们能够存储描述了一个中央资源的简单的名 - 值对。这正是RDFContainer是所有相关的。从概念上讲,它是一个星型般的数据结构。它有一个中心点 - 通用资源标识符(URI),即确定我们想要形容什么。围绕这一中心点,还有其他的点,代表属性值。它们都用链接连接到中央的uri,被标记为与相应的属性名。一个典型的可视化,简单的RDFContainer可能会这个样子。
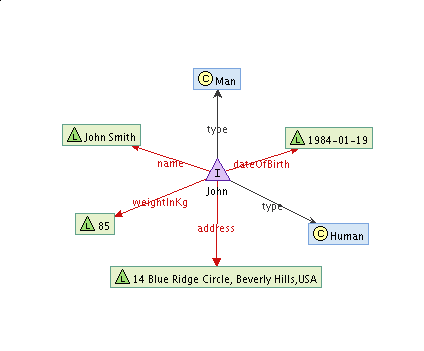
在这里,我们有一个叫John的信息。我们知道,他是一个人,更具体的一个人。我们知道他的全名是John Smith。我们也知道,他住在美国,在14 Blue Ridge Circle,Beverly Hills,美国。更重要的是,他出生于1984年1月19日,
下面代码部分将创建一个RDFContainer对象,,这将使我们能够在RDF store存储这些信息,可能如下所示。
Model model = RDF2Go.getModelFactory().createModel(); RDFContainer container = new RDFContainerImpl(model,MY_NS + "John"); container.add(RDF.TYPE,new URIImpl(MY_NS + "human")); container.add(RDF.TYPE,new URIImpl(MY_NS + "man")); container.add(new URIImpl(MY_NS + "name"), "John Smith"); Calendar dateOfBirth = new GregorianCalendar(); dateOfBirth.add(Calendar.YEAR, 1984); dateOfBirth.add(Calendar.MONTH, 1); dateOfBirth.add(Calendar.DAY_OF_MONTH, 19); container.add(new URIImpl(MY_NS + "dateOfBirth"), dateOfBirth); container.add(new URIImpl(MY_NS + "weightInKg"), 85); container.add(new URIImpl(MY_NS + "address"), "14 Blue Ridge Circle, Beverly Hills, USA");
每个add方法变体有两个参数。第一个是该属性的URI。第二个是值。一般情况下,属性的URI采取一些预定义的词汇类(如在这个例子RDF.TYPE),但并不妨碍我们自己的设计。在这个例子中,我们使得URI属于我们自己的命名空间(MY_NS常数)。第二个参数可以是多种类型之一。容器的实现会顾及任何转换。你不需要关心XSD数据类型,日期格式等,转换和上下文处理在幕后被处理。如果你是新接触RDF和这些概念几乎完全不懂 - 不要担心。在你的应用程序中使用aperture你不需要知道他们。
这些信息在RDFContainer中通过get ... 方法访问。出现许多风格。通过add... .,支持每一种数据类型 。一个例子,提取关于John的信息如下所示:
System.out.println(container.getString(new URIImpl(MY_NS + "name"))); System.out.println(container.getString(new URIImpl(MY_NS + "dateOfBirth"))); System.out.println(container.getString(new URIImpl(MY_NS + "weightInKg"))); System.out.println(container.getString(new URIImpl(MY_NS + "address")))
注意我们是如何用单一的getString方法。即使我们插入了许多不同的数据类型都会运行。转换是自动完成的。(如果他们是可能的,如果不是的话,你将需要处理异常)。即使在aperture不会知道如何转换'true'转换成 date。
读取资源全文
做过的第一件事是从RDFContainer读取资源全文
import org.semanticdesktop.aperture.vocabulary.NIE; ... Model model = RDF2Go.getModelFactory().createModel(); RDFContainer container = new RDFContainerImpl(model,"file://example"); ... extract some RDF into the file ... assuming that buffer and mimeType are set.... extractor.extract(container.getDescribedUri(), buffer, null, mimeType, container); ... String fulltext = container.getString(NIE.plainTextContent); ...
阅读嵌套值
要读取嵌套值(如联络人的全名),你可以使用RDFContainers或RDF2Go的模型方法。采用RDFContainer,它可能更容易:
// assuming the container is a crawled MP3 file URI composer = container.getURI(NID3.composer); RDFContainer composerContainer = new RDFContainerImpl(container.getModel(), composer); String fullname = composerContainer.getString(NCO.fullname);
Hash map functionality with put methods
的RDFContainer包含方法的名字开始把第二组... 他们从添加不同... 方法在一个重要方面。他们执行哈希映射语义,这是每一个属性可以有至多一个值。存储放第二个值将取代现有的。
另一方面,有多个值中的一个问题。如果我们指定属性应该有更多的值(像前面的例子RDF.TYPE),并想方设法把一个的RDFContainer将决定哪一个返回。Aperture的设计师决定,它是给用户知道,这种情况可能会发生,并指出,得到方法将抛出一个MultipleValuesException的在这种情况下的。如果您需要使用具有多个值的属性,你需要使用的getAll()方法。它的工作原理如下:
The RDFContainer contains a second set of methods whose names start with put... They differ from the add... methods in one important respect. They enforce the hash-map semantics, that is every property can have at most one value. Storing a second value with put will replace the existing one.
On the other hand, there is a problem with multiple values. If we specify that a property should have more values (like RDF.TYPE in the previous example) and try to get one, the RDFContainer would have to decide which one to return. The designers of aperture decided that it is up to the user to know that such a situation could occur, and stated, that get methods will throw a MultipleValuesException in such case. If you need to work with properties that have multiple values, you need to use the getAll() method. It works as follows:
Collection types = container.getAll(RDF.TYPE);
for (Iterator iterator = types.iterator(); iterator.hasNext(); ) {
Node node = (Node)iterator.next();
System.out.println(node);
}
This collection contains Node objects. Node is a superinterface, that encompasses all datatypes that can occur in an RDF store - URIS, Literals and Blank Nodes. Unfortunately you will have to dig a bit deeper into the RDF documentation and the javadocs for org.ontoware.rdf2go.model package to get to know how to work with them. The container won't aid you in this aspect.
During development of some Extractors and Crawlers we experienced that the use of the put and get methods, which enforce and ensure that a property maximally occurs once for a given subject, may not always be desirable. In general, it makes a lot of sense to use them in configuration-like contexts, e.g. the definition of a DataSource. Here it can be vital that a property has a single value or else the definition becomes ambiguous or unprocessable. However, in the context of Crawlers and Extractors we found that taking such a closed world assumption on the RDF graph is less ideal: you never know who else is working on the same RDF graph and whether it makes logically sense to allow a property to have multiple values or not. It is up to you to decide which approach to use in your particular application.
Direct access to statements
Even though the abstraction of RDFContainer is enough to perform many tasks, sometimes you simply have to resort to the full expressive power of RDF and model the knowledge with a fully-fledged graph. Let's imagine a simple case that John has a car. This car is a green Ford. Trying to express it in a simple RDFContainer with a 'star' of properties would be unnatural. It would have to look somehow like this:
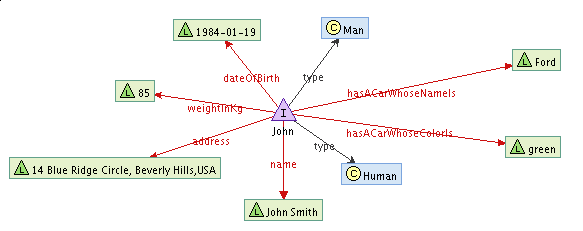
A much more natural way to express this fact would be to have a separate node that would represent a car. It could have it's own identifier and it's own properties. In such case, it would be much easier to update our knowledge base when John buys himself another car :-). Let's try to build a following structure:
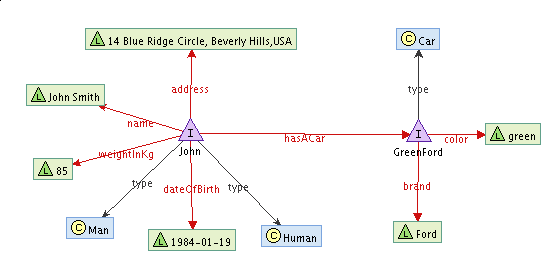
The first stage would be to describe John using 'normal' methods, as already described in previous chapters. The link that states that John has a Car, can also be inserted with 'normal' rdfContainer method. For the description of the car itself, we'll have to do everything by ourselves.
Every statement represents a single link in the knowledge graph. It consists of three parts - subject, predicate and object. RDFContainer in itself does nothing more than setting the subject to the central URI. It would be possible not to use the add/put methods at all. Everything could be expressed with Statements, albeit in a less readable and more complicated way. Nevertheless, if we want to describe an URI that is not the central one - we have no other option. We can use the ValueFactory interface to get help.
Here's an example how it can be accomplished.
ValueFactory factory = container.getValueFactory();
URI carURI = factory.createURI(MY_NS + "GreenFord");
container.add(new URIImpl(MY_NS + "hasACar"),carURI);
Statement statement1 = factory.createStatement(
carURI,
RDF.TYPE,
factory.createURI(MY_NS + "Car"));
Statement statement2 = factory.createStatement(
carURI,
factory.createURI(MY_NS + "brand"),
factory.createLiteral("Ford"));
Statement statement3 = factory.createStatement(
carURI,
factory.createURI(MY_NS + "color"),
factory.createLiteral("green"));
container.add(statement1);
container.add(statement2);
container.add(statement3)
Inference on RDFContainers
RDF data may sometime behave unexpected - querying for a "subject" of an email may not return a subject, even when the "messageSubject" property was added as a statement. In RDF, properties form a hierarchy, there are super- and sub-properties. RDF-Schema defines a rule which requires that statements expressed using a property are automatically also available as statements with any super-propeties of the property.
# This statement is in the RDF container <myresource> nmo:messageSubject "Hello World". # This statement should be added by inference <myresource> nie:subject "Hello World".
Inference is a time- and spaceconsuming task, therefore aperture does not infer these triples automatically and does not require Extractors to add all the inferred statements. Its up to the user to decide if inference is needed or not.
A simple way to get inferred statements is by using the InferenceUtil.
InferenceUtil is used to read the ontologies (that is the RDF files
which define which property is a sub-property of another and the same
for subclasses) and then applies the rules on a passed RDFContainer. It
adds the inferenced triples to the RDFContainer's model.
Example:
class MyCrawlerHandler extends CrawlerHandlerBase {
InferenceUtil inferenceUtil;
/**
* initialize the inference util once, this is a costly operation
*/
public MyCrawlerHandler() {
// intialize Inference Util
inferenceUtil = InferenceUtil.createForCoreOntologies();
}
public void objectNew(Crawler crawler, DataObject object) {
// first we try to extract the information from the binary file
processBinary(object);
// here the INFERENCE magic
inferenceUtil.extendContent(object.getMetadata());
// then we add this information to our persistent model
modelSet.addModel(object.getMetadata().getModel());
// don't forget to dispose of the DataObject
object.dispose();
}
}
The InferenceUtil is also used in the example FileInspector.
Note that using inference will affect performance and that the
implementation of the InferenceUtil is not "perfect" but at least simple
enough that you can improve performance if required.
RDFContainer Implementation
A single RDFContainer implementation is currently available - RDFContainetImpl. It works with an RDF2Go model. All matters regarding context and transactions are solved in/behind this implementation.
---------------------------------------------------------------------------
本系列WEB数据挖掘系本人原创
作者 博客园 刺猬的温驯
本文链接 http://www.cnblogs.com/chenying99/archive/2013/06/14/3134942.html
本文版权归作者所有,未经作者同意,严禁转载及用作商业传播,否则将追究法律责任。
