Nodejs事件引擎libuv源码剖析之:高效队列(queue)的实现
声明:本文为原创博文,转载请注明出处。
在libuv中,有一个只使用简单的宏封装成的高效队列(queue),现在我们就来看一下它是怎么实现的。
首先,看一下queue中最基本的几个宏:
1 typedef void *QUEUE[2]; 2 3 /* Private macros. */ 4 #define QUEUE_NEXT(q) (*(QUEUE **) &((*(q))[0])) 5 #define QUEUE_PREV(q) (*(QUEUE **) &((*(q))[1])) 6 #define QUEUE_PREV_NEXT(q) (QUEUE_NEXT(QUEUE_PREV(q))) 7 #define QUEUE_NEXT_PREV(q) (QUEUE_PREV(QUEUE_NEXT(q)))
首先,QUEUE被声明成一个"具有两个char*元素的指针数组",如下图:
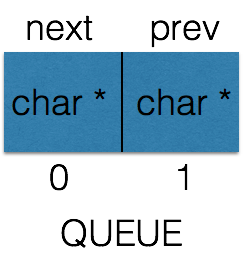
接下来看第一个宏: QUEUE_NEXT(q) ,其中q代表一个指向QUEUE数组的指针,其返回值是下一个节点QUEUE的指针,其用法大致如下:
1 static QUEUE queue; 2 QUEUE_NEXT(&queue);
可以看到,非常简单的操作便可以取得queue的下一个节点地址,那么它是如何做到的呢,来看一下QUEUE_NEXT的实现:
(*(QUEUE **) &((*(q))[0]))
这个表达式看似复杂,其实它就相当于"(*q)[0]",也就是代表QUEUE数组的第一个元素,那么它为什么要写这么复杂呢,主要有两个原因:类型保持、成为左值。
QUEUE_NEXT(&queue) 扩展之后相当于:(*(QUEUE **)&((*(&queue))[0])),我们将其拆开来看(如下图所示),共分为四个部分:
第(1)个部分,先对数组取地址(&)再对其解引用(*),最后再作[0]运算,就相当于queue[0],这里补充一下知识:假设有一个数组int a[10],当访问数组时,a[1]相当于*(a+1),而数组名相当于数组首元素首地址,而&a在数值上虽然与a的值相同,但是&a从含义上讲是代表整个数组的首地址(类型为整个数组),因此&a + 1操作将跨域整个数组的长度,因此(&a)[1]并不是访问a[1],(*(&a))[1]才是访问a[1],具体原理可以看我的另一篇博文:图解多级指针与多维数组。
第(2)个部分,对数组首元素queue[0]取地址。
第(3)个部分,对第二部分取得的地址进行强制类型转换,将其强转为QUEUE **,因为QUEUE的元素类型本身为void *,而实际中每一个元素都需要指向QUEUE地址,因此对于&queue[0](二级指针),就需要将其强转为QUEUE **。
第(4)个部分,对上文强转后的地址进行“解引用”操作,也就是对&queue[0]解引用之后相当于queue[0],为什么要这么做呢?这是为了使其成为左值,左值的简单定义是:占用实际的内存、可以对其进行取地址操作的变量都是左值,而c语言中(其实其他语言也是一样),对于一个变量(或者表达式)进行强制类型转换时,其实并不是改变该变量本身的类型,而是产生一个变量的副本,而这个副本并不是左值(因为并不能对其取地址),它是一个右值,举个例子:int a = 1; (char) a = 2;这样会报错。而如果改成这样:int a = 1; (*(char *)(&a)) = 2;就正确了。
至此,这个稍微有点复杂的表达式算是分析清楚了,对于QUEUE_PREV原理类似,在此不再赘述。
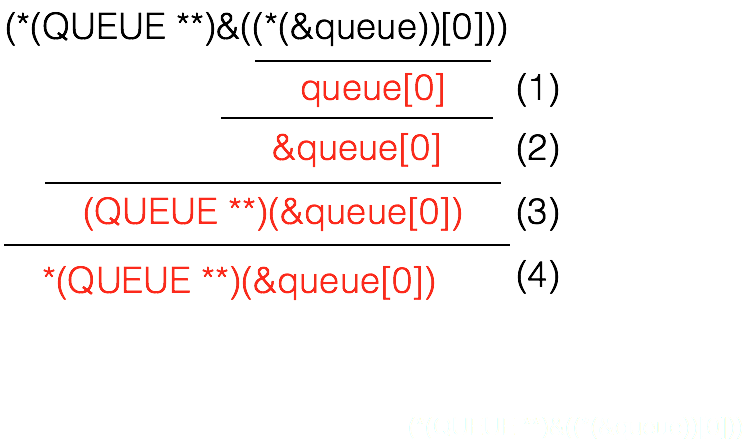
接下来看看对队列的其他操作,这些操作都是建立在前面四个基础宏定义基础上的(注:以下所有宏的参数类型都为:QUEUE *):
1)队列初始化
1 #define QUEUE_INIT(q) \ 2 do { \ 3 QUEUE_NEXT(q) = (q); \ 4 QUEUE_PREV(q) = (q); \ 5 } \ 6 while (0)
初始化队列q就是将其next和prev的指针指向自己。
2)队列为空判断
1 #define QUEUE_EMPTY(q) \ 2 ((const QUEUE *) (q) == (const QUEUE *) QUEUE_NEXT(q))
只要q的next指针还是指向自己,就说明队列为空(只有链表头结点)。
3)队列遍历
1 #define QUEUE_FOREACH(q, h) \ 2 for ((q) = QUEUE_NEXT(h); (q) != (h); (q) = QUEUE_NEXT(q))
遍历队列q,直到遍历到h为止。注意:在遍历时,不要同时对队列q进行插入、删除操作,否则会出现未知错误。
4)获取队列头
1 #define QUEUE_HEAD(q) \ 2 (QUEUE_NEXT(q))
链表头节点的next返回的就是队列的head节点(具体原理可以看下文的图解)。
5)队列相加
1 #define QUEUE_ADD(h, n) \ 2 do { \ 3 QUEUE_PREV_NEXT(h) = QUEUE_NEXT(n); \ 4 QUEUE_NEXT_PREV(n) = QUEUE_PREV(h); \ 5 QUEUE_PREV(h) = QUEUE_PREV(n); \ 6 QUEUE_PREV_NEXT(h) = (h); \ 7 } \ 8 while (0)
将队列n加入到队列h的尾部,假设两个对象的初始状态为:
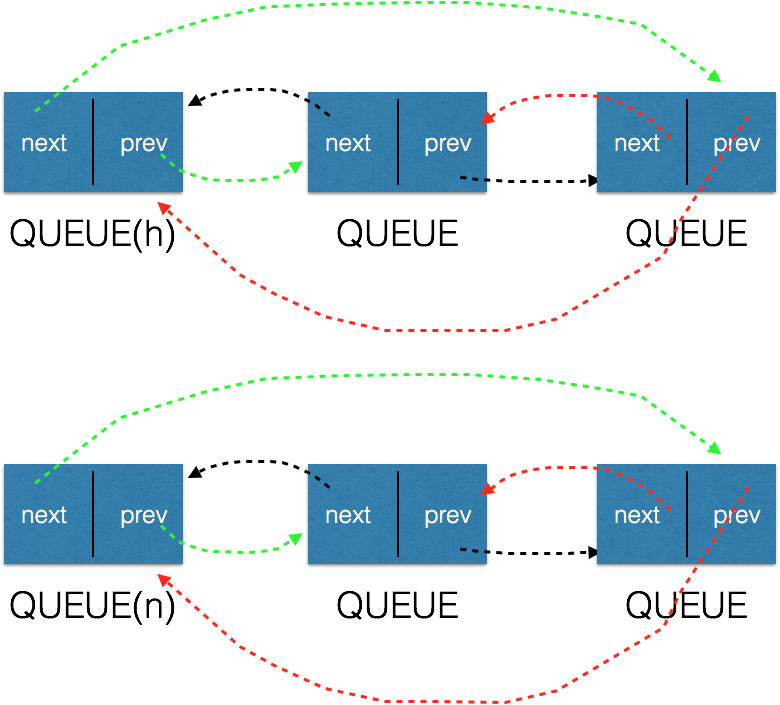
经过以上的ADD步骤后,状态为:
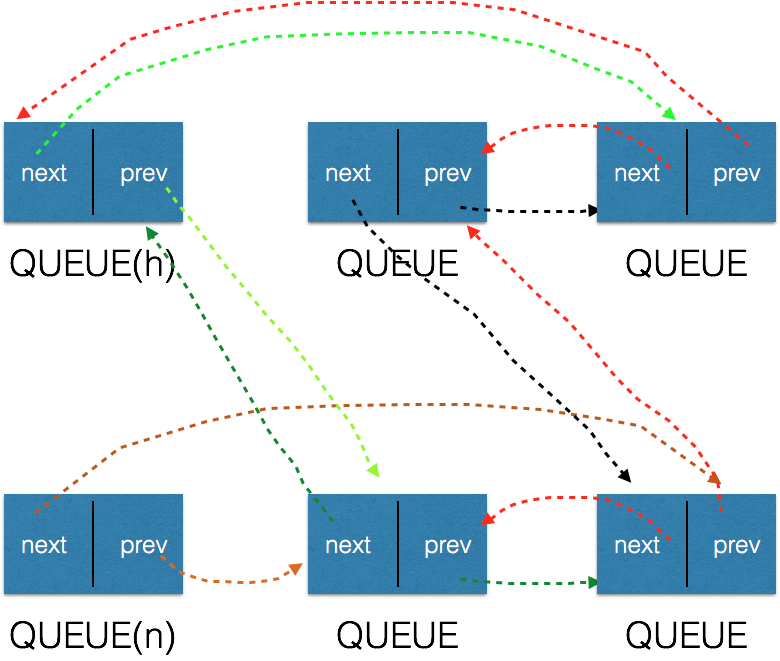
6)队列分割
1 #define QUEUE_SPLIT(h, q, n) \ 2 do { \ 3 QUEUE_PREV(n) = QUEUE_PREV(h); \ 4 QUEUE_PREV_NEXT(n) = (n); \ 5 QUEUE_NEXT(n) = (q); \ 6 QUEUE_PREV(h) = QUEUE_PREV(q); \ 7 QUEUE_PREV_NEXT(h) = (h); \ 8 QUEUE_PREV(q) = (n); \ 9 } \ 10 while (0)
队列分割就是上述ADD的逆过程,将队列h以q为分割点进行分割,分割出来的新队列为n(n为分出来的双向循环链表的头结点)。此处不再单独提供图示。
7)队列移动
1 #define QUEUE_MOVE(h, n) \ 2 do { \ 3 if (QUEUE_EMPTY(h)) \ 4 QUEUE_INIT(n); \ 5 else { \ 6 QUEUE* q = QUEUE_HEAD(h); \ 7 QUEUE_SPLIT(h, q, n); \ 8 } \ 9 } \ 10 while (0)
将队列h移动到n队里中,首先如果h队列为空,那么就把n初始化为空;如果h不为空,那么就先取出h队列的head节点,然后调用前面论述过的队列分割宏,从head节点开始分割,等价于把h队列的所有内容(输了h自身,因为它是链表头节点)全部转移到n队里里面。
8)向队列头插入节点
1 #define QUEUE_INSERT_HEAD(h, q) \ 2 do { \ 3 QUEUE_NEXT(q) = QUEUE_NEXT(h); \ 4 QUEUE_PREV(q) = (h); \ 5 QUEUE_NEXT_PREV(q) = (q); \ 6 QUEUE_NEXT(h) = (q); \ 7 } \ 8 while (0)
假设h队列起始状态为空,则两个节点起始状态为:

则执行插入后的状态为:

现在假设再插入一个节点n,则初始状态为:
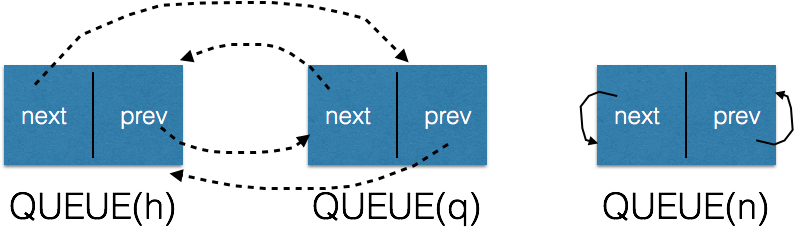
插入之后的状态为:
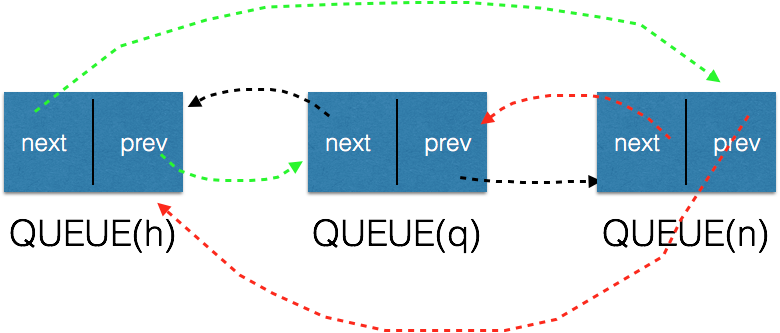
9)向队列尾部插入节点
1 #define QUEUE_INSERT_TAIL(h, q) \ 2 do { \ 3 QUEUE_NEXT(q) = (h); \ 4 QUEUE_PREV(q) = QUEUE_PREV(h); \ 5 QUEUE_PREV_NEXT(q) = (q); \ 6 QUEUE_PREV(h) = (q); \ 7 } \ 8 while (0)
将q节点插入h队列的尾部,假设h队列目前为空,则初始状态为:
执行插入之后的状态为:
现在假设再插入一个n,则初始状态为:
执行插入之后的状态为:
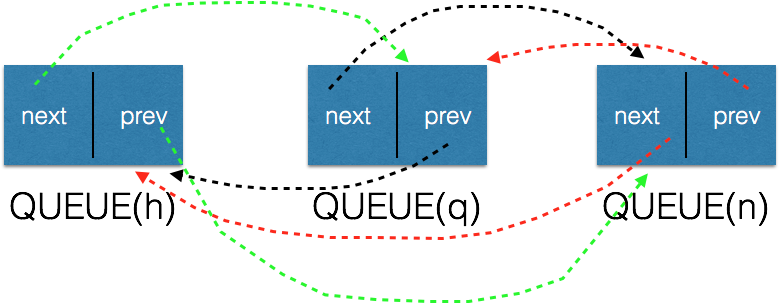
不容易看吗?稍微调整一下,就是这样(循环双向链表):
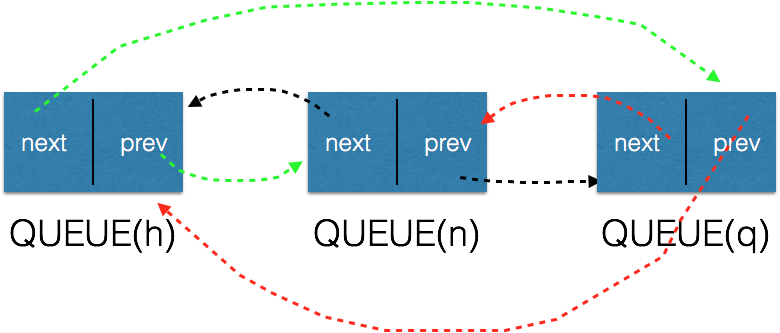
由此,可以清楚的看到,QUEUE(h)作为队列头,它的next就是队列的第一个head节点。
10)队列删除
1 #define QUEUE_REMOVE(q) \ 2 do { \ 3 QUEUE_PREV_NEXT(q) = QUEUE_NEXT(q); \ 4 QUEUE_NEXT_PREV(q) = QUEUE_PREV(q); \ 5 } \ 6 while (0)
队列删除的原理很简单,现将q前一个节点的next指针修改为指向q的next指针指向的下一个节点,再q的下一个节点的prev指针修改为指向q当前指向的前一个节点。
11)在队列中存取用户数据
1 #define QUEUE_DATA(ptr, type, field) \ 2 ((type *) ((char *) (ptr) - offsetof(type, field)))
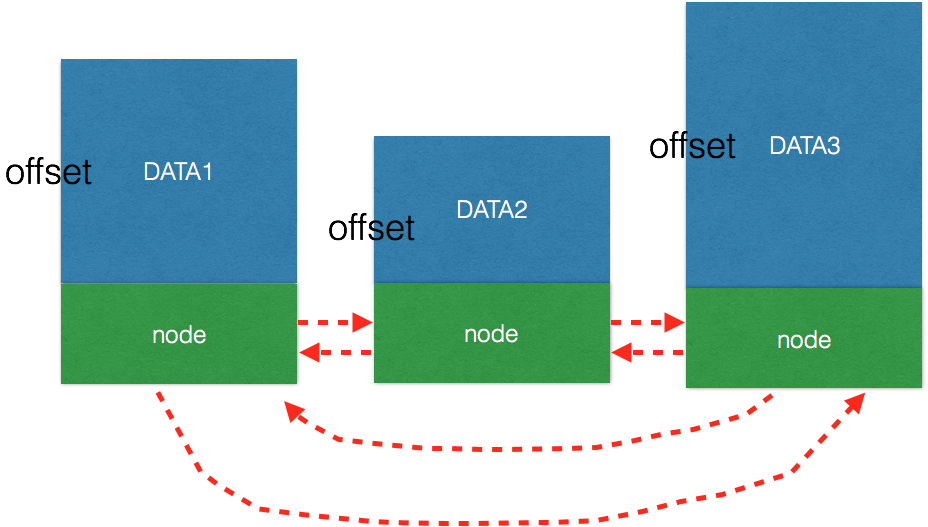
在前面的论述中我们清楚了队列节点的增删查等操作,但是我们丝毫没有看到可以存用户数据的地方,其实,如果你熟悉linux内核的话就会很容易理解,这种队列并不限制你的用户数据类型,你需要做的,只是将QUEUE节点内嵌到自己定义的数据类型中即可,然后让它们串起来。大致概念如下:
1 struct user_s1 { 2 int age; 3 char* name; 4 5 QUEUE node; 6 }; 7 8 struct user_s2 { 9 int age; 10 char* name; 11 char* address; 12 13 QUEUE node; 14 };
两种结构体虽然是不同的数据类型,但是它们都包含了QUEUE节点,可以将他们的node成员组成双向循环链表进行管理,这样就可以以队列方式来管理它们的node成员了,但是拿到node成员(其实是地址)之后,怎么拿到用户数据呢?这就用到了QUEUE_DATA宏(熟悉Linux内核编程的人都熟悉,他就是container_of),拿到node成员的地址之后,只要将该地址减去node成员在结构体中的偏移,就可以拿到整个结构体的起始地址,也就拿到了用户数据了。下面再来一张图: