
MySQL 指定各分区路径
介绍
可以针对分区表的每个分区指定各自的存储路径,对于innodb存储引擎的表只能指定数据路径,因为数据和索引是存储在一个文件当中,对于MYISAM存储引擎可以分别指定数据文件和索引文件,一般也只有RANGE、LIST分区、sub子分区才有可能需要单独指定各个分区的路径,HASH和KEY分区的所有分区的路径都是一样。RANGE分区指定路径和LIST分区是一样的,这里就拿LIST分区来做讲解。
一、MYISAM存储引擎

CREATE TABLE th (id INT, adate DATE)
engine='MyISAM'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
);
注意:MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径。
二、INNODB存储引擎
CREATE TABLE thex (id INT, adate DATE)
engine='InnoDB'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data',
PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data',
PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data',
PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data'
);
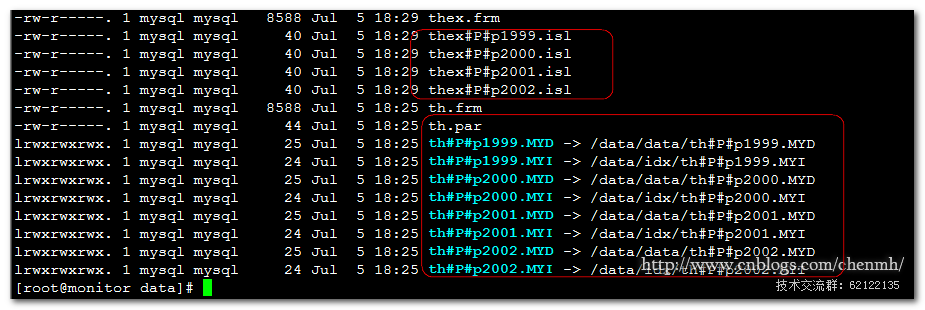
指定路径之后在原来的路径中innodb生成了4个指向数据存储的路径文件,myisam生成了一个th.par文件指明该表是分区表,同时数据文件和索引文件指向了实际的存储路径。
三、子分区
1.子分区
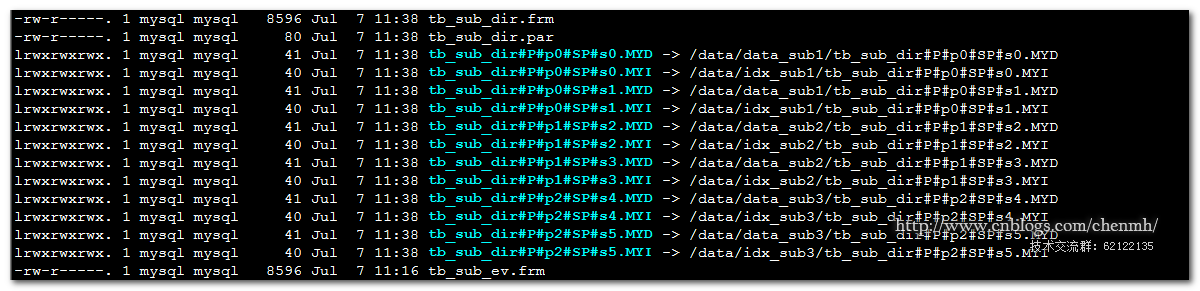
CREATE TABLE tb_sub_dir (id INT, purchased DATE) ENGINE='MYISAM' PARTITION BY RANGE( YEAR(purchased) ) SUBPARTITION BY HASH( TO_DAYS(purchased) ) ( PARTITION p0 VALUES LESS THAN (1990) ( SUBPARTITION s0 DATA DIRECTORY = '/data/data_sub1' INDEX DIRECTORY = '/data/idx_sub1', SUBPARTITION s1 DATA DIRECTORY = '/data/data_sub1' INDEX DIRECTORY = '/data/idx_sub1' ), PARTITION p1 VALUES LESS THAN (2000) ( SUBPARTITION s2 DATA DIRECTORY = '/data/data_sub2' INDEX DIRECTORY = '/data/idx_sub2', SUBPARTITION s3 DATA DIRECTORY = '/data/data_sub2' INDEX DIRECTORY = '/data/idx_sub2' ), PARTITION p2 VALUES LESS THAN MAXVALUE ( SUBPARTITION s4 DATA DIRECTORY = '/data/data_sub3' INDEX DIRECTORY = '/data/idx_sub3', SUBPARTITION s5 DATA DIRECTORY = '/data/data_sub3' INDEX DIRECTORY = '/data/idx_sub3' ) );
2.子分区再分
CREATE TABLE tb_sub_dirnew (id INT, purchased DATE) ENGINE='MYISAM' PARTITION BY RANGE( YEAR(purchased) ) SUBPARTITION BY HASH( TO_DAYS(purchased) ) ( PARTITION p0 VALUES LESS THAN (1990) DATA DIRECTORY = '/data/data' INDEX DIRECTORY = '/data/idx' ( SUBPARTITION s0 DATA DIRECTORY = '/data/data_sub1' INDEX DIRECTORY = '/data/idx_sub1', SUBPARTITION s1 DATA DIRECTORY = '/data/data_sub1' INDEX DIRECTORY = '/data/idx_sub1' ), PARTITION p1 VALUES LESS THAN (2000) DATA DIRECTORY = '/data/data' INDEX DIRECTORY = '/data/idx' ( SUBPARTITION s2 DATA DIRECTORY = '/data/data_sub2' INDEX DIRECTORY = '/data/idx_sub2', SUBPARTITION s3 DATA DIRECTORY = '/data/data_sub2' INDEX DIRECTORY = '/data/idx_sub2' ), PARTITION p2 VALUES LESS THAN MAXVALUE DATA DIRECTORY = '/data/data' INDEX DIRECTORY = '/data/idx' ( SUBPARTITION s4 DATA DIRECTORY = '/data/data_sub3' INDEX DIRECTORY = '/data/idx_sub3', SUBPARTITION s5 DATA DIRECTORY = '/data/data_sub3' INDEX DIRECTORY = '/data/idx_sub3' ) );
也可以给个分区指定路径后再给子分区指定路径,但是这样没有意义,因为数据的存在都是由子分区决定的。
注意:
1.指定的路径必须存在,否则分区无法创建成功
2.MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径
分区系列文章:
RANGE分区:http://www.cnblogs.com/chenmh/p/5627912.html
LIST分区:http://www.cnblogs.com/chenmh/p/5643174.html
COLUMN分区:http://www.cnblogs.com/chenmh/p/5630834.html
HASH分区:http://www.cnblogs.com/chenmh/p/5644496.html
KEY分区:http://www.cnblogs.com/chenmh/p/5647210.html
子分区:http://www.cnblogs.com/chenmh/p/5649447.html
分区建索引:http://www.cnblogs.com/chenmh/p/5761995.html
分区介绍总结:http://www.cnblogs.com/chenmh/p/5623474.html
总结
通过给各个分区指定各自的磁盘可以有效的提高读写性能,在条件允许的情况下是一个不错的方法。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接。 《欢迎交流讨论》 |

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步