
SQL Server 重新组织生成索引
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引/统计信息
概述
无论何时对基础数据执行插入、更新或删除操作,SQL Server 数据库引擎都会自动维护索引。随着时间的推移,这些修改可能会导致索引中的信息分散在数据库中(含有碎片)。当索引包含的页中的逻辑排序(基于键值)与数据文件中的物理排序不匹配时,就存在碎片。碎片非常多的索引可能会降低查询性能,导致应用程序响应缓慢,所以在日常的维护工作当中就需要对索引进行检查对那些填充度很低碎片量大的索引进行重新生成或重新组织,但是在这个过程也需要注意一些小的细节,否则会产生错误。
一、语法
语法内容载自SQL Server联机丛书,标记出了需要注意的内容,最后分享自己平时用的维护索引的语句供参考。
ALTER INDEX { index_name | ALL } ON <object> { REBUILD [ [PARTITION = ALL] [ WITH ( <rebuild_index_option> [ ,...n ] ) ] | [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> [ ,...n ] ) ] ] ] | DISABLE | REORGANIZE [ PARTITION = partition_number ] [ WITH ( LOB_COMPACTION = { ON | OFF } ) ] | SET ( <set_index_option> [ ,...n ] ) } [ ; ] <object> ::= { [ database_name. [ schema_name ] . | schema_name. ] table_or_view_name } <rebuild_index_option > ::= { PAD_INDEX = { ON | OFF } | FILLFACTOR = fillfactor | SORT_IN_TEMPDB = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } | ONLINE = { ON | OFF } | ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE } [ ON PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ] } <range> ::= <partition_number_expression> TO <partition_number_expression> } <single_partition_rebuild_index_option> ::= { SORT_IN_TEMPDB = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE } } } <set_index_option>::= { ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } }
- index_name
-
索引的名称。索引名称在表或视图中必须唯一,但在数据库中不必唯一。索引名称必须符合标识符的规则。
- ALL
-
指定与表或视图相关联的所有索引,而不考虑是什么索引类型。如果有一个或多个索引脱机或不允许对一个或多个索引类型执行只读文件组操作或指定操作,则指定 ALL 将导致语句失败。下表列出了索引操作和不允许使用的索引类型。
已分区表和已分区索引。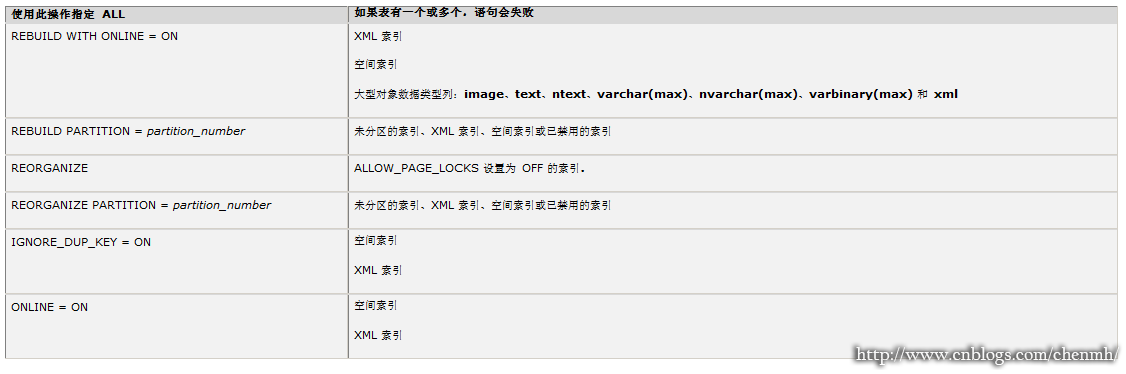
- database_name
-
数据库的名称。
- schema_name
-
表或视图所属架构的名称。
- table_or_view_name
-
与该索引关联的表或视图的名称。若要显示对象的索引报表,请使用 sys.indexes 目录视图。
- REBUILD [ WITH (<rebuild_index_option> [ ,...n]) ]
-
指定将使用相同的列、索引类型、唯一性属性和排序顺序重新生成索引。此子句等同于 DBCC DBREINDEX。REBUILD 启用已禁用的索引。重新生成聚集索引并不重新生成关联的非聚集索引,除非指定了关键字 ALL。如果未指定索引选项,则应用存储在 sys.indexes 中的现有索引选项值。对于未在 sys.indexes 中存储值的任何索引选项,应用该选项的参数定义中指示的默认值。
重新生成 XML 索引或空间索引时,选项 ONLINE = ON 和 IGNORE_DUP_KEY = ON 无效。
如果指定 ALL 且基础表为堆,则重新生成操作对表没有任何影响。重新生成与表相关联的所有非聚集索引。
如果数据库恢复模式设置为大容量日志记录或简单,则可以对重新生成操作进行最小日志记录。

- PARTITION
-
指定只重新生成或重新组织索引的一个分区。如果 index_name 不是已分区索引,则不能指定 PARTITION。
PARTITION = ALL 重新生成所有分区。当指定PARTITION = ALL时不能使用ONLINE = ON
- partition_number
-
要重新生成或重新组织已分区索引的分区数。partition_number 是可以引用变量的常量表达式。其中包括用户定义类型变量或函数以及用户定义函数,但不能引用 Transact-SQL 语句。partition_number 必须存在,否则,该语句将失败。
- WITH (<single_partition_rebuild_index_option>)
-
SORT_IN_TEMPDB、MAXDOP 和 DATA_COMPRESSION 是在重新生成单个分区 (PARTITION = n) 时可以指定的选项。不能在单个分区重新生成操作中指定 XML 索引。
不能联机重新生成分区索引。在此操作过程中将锁定整个表。
- DISABLE
-
将索引标记为已禁用,从而不能由 数据库引擎使用。任何索引均可被禁用。已禁用的索引的索引定义保留在没有基础索引数据的系统目录中。禁用聚集索引将阻止用户访问基础表数据。若要启用索引,请使用 ALTER INDEX REBUILD 或 CREATE INDEX WITH DROP_EXISTING。
- REORGANIZE
-
指定将重新组织的索引叶级。此子句等同于 DBCC INDEXDEFRAG。ALTER INDEX REORGANIZE 语句始终联机执行。这意味着不保留长期阻塞的表锁,且对基础表的查询或更新可以在 ALTER INDEX REORGANIZE 事务处理期间继续。不能为已禁用的索引或 ALLOW_PAGE_LOCKS 设置为 OFF 的索引指定 REORGANIZE。
- WITH ( LOB_COMPACTION = { ON | OFF } )
-
指定压缩所有包含大型对象 (LOB) 数据的页。LOB 数据类型包括 image、text、ntext、varchar(max)、nvarchar(max)、varbinary(max) 和 xml。压缩此数据可以改善磁盘空间使用情况。默认值为 ON。
- ON
-
压缩所有包含大型对象数据的页。
重新组织指定的聚集索引将压缩聚集索引中包含的所有 LOB 列。重新组织非聚集索引将压缩作为索引中非键(已包括)列的所有 LOB 列。有关详细信息,请参阅创建带有包含列的索引。
指定 ALL 时,将重新组织与指定表或视图相关联的所有索引,并且压缩与聚集索引、基础表或具有包含列的非聚集索引相关联的所有 LOB 列。
- OFF
-
不压缩包含大型对象数据的页。
OFF 对堆没有影响。
如果 LOB 列不存在,则忽略 LOB_COMPACTION 子句。
- SET ( <set_index option> [ ,...n] )
-
指定不重新生成或重新组织索引的索引选项。不能为已禁用的索引指定 SET。
- PAD_INDEX = { ON | OFF }
-
指定索引填充。默认值为 OFF。
- ON
-
FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。如果在 PAD_INDEX 设置为 ON 的同时不指定 FILLFACTOR,则使用 sys.indexes 中存储的填充因子值。
- OFF 或不指定 fillfactor
-
中间级页已填充到接近容量限制。这样将至少为索引可以基于中间页中的键集拥有的最大大小的一行留出足够的空间。
- FILLFACTOR = fillfactor
-
指定一个百分比,指示在创建或更改索引期间,数据库引擎对各索引页的叶级填充的程度。fillfactor 必须为介于 1 至 100 之间的整数值。默认值为 0。
填充因子的值 0 和 100 在所有方面都是相同的。
显式的 FILLFACTOR 设置只是在索引首次创建或重新生成时应用。数据库引擎并不会在页中动态保持指定的可用空间百分比。有关详细信息,请参阅 CREATE INDEX (Transact-SQL)。
若要查看填充因子设置,请使用 sys.indexes。
使用 FILLFACTOR 值创建或更改聚集索引会影响数据占用的存储空间量,因为数据库引擎在创建聚集索引时会再分发数据。
- SORT_IN_TEMPDB = { ON | OFF }
-
指定是否在 tempdb 中存储排序结果。默认值为 OFF。
- ON
-
在 tempdb 中存储用于生成索引的中间排序结果。如果 tempdb 位于不同于用户数据库的磁盘集中,这样可能会缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
- OFF
-
中间排序结果与索引存储在同一数据库中。
如果不需要执行排序操作,或者可以在内存中进行排序,则忽略 SORT_IN_TEMPDB 选项。
- IGNORE_DUP_KEY = { ON | OFF }
-
指定在插入操作尝试向唯一索引插入重复键值时的错误响应。IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。默认值为 OFF。
- ON
-
向唯一索引插入重复键值时将出现警告消息。只有违反唯一性约束的行才会失败。
- OFF
-
向唯一索引插入重复键值时将出现错误消息。整个 INSERT 操作将被回滚。
对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON。
若要查看 IGNORE_DUP_KEY,请使用 sys.indexes。
在向后兼容的语法中,WITH IGNORE_DUP_KEY 等效于 WITH IGNORE_DUP_KEY = ON。
- STATISTICS_NORECOMPUTE = { ON | OFF }
-
指定是否重新计算分发统计信息。默认值为 OFF。
- ON
-
不会自动重新计算过时的统计信息。
- OFF
-
启用统计信息自动更新功能。
若要恢复统计信息自动更新,请将 STATISTICS_NORECOMPUTE 设置为 OFF,或执行 UPDATE STATISTICS 但不包含 NORECOMPUTE 子句。
如果禁用分发统计信息的自动重新计算,可能会阻止查询优化器为涉及该表的查询挑选最佳执行计划。
- ONLINE = { ON | OFF }
-
指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。默认值为 OFF。
对于 XML 索引或空间索引,仅支持 ONLINE = OFF。如果 ONLINE 设置为 ON,则会引发错误。
联机索引操作仅在 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 中可用。
- ON
-
在索引操作期间不持有长期表锁。在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。这样,即可继续对基础表和索引进行查询或更新。操作开始时,将对源对象保持极短时间的共享 (S) 锁。操作结束时,如果创建非聚集索引,将对源持有极短时间的 S 锁;当联机创建或删除聚集索引时,或者重新生成聚集或非聚集索引时,将获取 SCH-M(架构修改)锁。对本地临时表创建索引时,ONLINE 不能设置为 ON。
- OFF
-
在索引操作期间应用表锁。创建、重新生成或删除聚集索引、空间索引或 XML 索引或者重新生成或删除非聚集索引的脱机索引操作将获得对表的架构修改 (Sch-M) 锁。这样可以防止所有用户在操作期间访问基础表。创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
有关详细信息,请参阅联机索引操作的工作方式。有关锁的详细信息,请参阅锁模式。
索引(包括全局临时表中的索引)可以联机重新生成,但以下索引除外:
- 禁用的索引
- XML 索引
- 本地临时表中的索引
- 分区索引
- 聚集索引(如果基础表包含 LOB 数据类型)。
- 使用 LOB 数据类型列定义的非聚集索引
如果表包含 LOB 数据类型,但这些列中没有任何列在索引定义中用作键列或非键列,则可以联机重新生成非聚集索引。
- ALLOW_ROW_LOCKS = { ON | OFF }
-
指定是否允许行锁。默认值为 ON。
- ON
-
在访问索引时允许使用行锁。数据库引擎确定何时使用行锁。
- OFF
-
不使用行锁。
- ALLOW_PAGE_LOCKS = { ON | OFF }
-
指定是否允许使用页锁。默认值为 ON。
- ON
-
访问索引时允许使用页锁。数据库引擎确定何时使用页锁。
- OFF
-
不使用页锁。
ALLOW_PAGE_LOCKS 设置为 OFF 时,无法重新组织索引。
- MAXDOP = max_degree_of_parallelism
-
在索引操作期间覆盖“最大并行度”配置选项。有关详细信息,请参阅 max degree of parallelism 选项。使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。最大数量为 64 个处理器。
虽然从语法上讲所有 XML 索引都支持 MAXDOP 选项,但对于空间索引或主 XML 索引,ALTER INDEX 当前只使用一个处理器。
max_degree_of_parallelism 可以是:
- 1
-
取消生成并行计划。
- >1
-
将并行索引操作中使用的最大处理器数量限制为指定数量。
- 0(默认值)
-
根据当前系统工作负荷使用实际的处理器数量或更少数量的处理器。
并行索引操作仅在 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 中可用。
- DATA_COMPRESSION
-
为指定的索引、分区号或分区范围指定数据压缩选项。选项如下所示:
- NONE
-
不压缩索引或指定的分区。
- ROW
-
使用行压缩来压缩索引或指定的分区。
- PAGE
-
使用页压缩来压缩索引或指定的分区。
有关压缩的详细信息,请参阅创建压缩表和索引。
- ON PARTITIONS ( { <partition_number_expression> | <range> } [,...n] )
-
指定对其应用 DATA_COMPRESSION 设置的分区。如果索引未分区,则 ON PARTITIONS 参数将产生错误。如果不提供 ON PARTITIONS 子句,则 DATA_COMPRESSION 选项将应用于分区索引的所有分区。
可以按以下方式指定 <partition_number_expression>:
- 提供一个分区号,例如:ON PARTITIONS (2)。
- 提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
- 同时提供范围和单独的分区:ON PARTITIONS (2, 4, 6 TO 8)。
<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
若要为不同分区设置不同的数据压缩类型,请多次指定 DATA_COMPRESSION 选项,例如:
REBUILD WITH ( DATA_COMPRESSION = NONE ON PARTITIONS (1), DATA_COMPRESSION = ROW ON PARTITIONS (2, 4, 6 TO 8), DATA_COMPRESSION = PAGE ON PARTITIONS (3, 5) )
- 提供一个分区号,例如:ON PARTITIONS (2)。
ALTER INDEX 不能用于对索引重新分区或将索引移到其他文件组。此语句不能用于修改索引定义,如添加或删除列,或更改列的顺序。使用带有 DROP_EXISTING 子句的 CREATE INDEX 执行这些操作。
未显式指定选项时,则应用当前设置。例如,如果未在 REBUILD 子句中指定 FILLFACTOR 设置,将在重新生成过程中使用系统目录中存储的填充因子值。若要查看当前索引选项设置,请使用 sys.indexes。
系统目录中不存储 ONLINE、MAXDOP 和 SORT_IN_TEMPDB 的值。除非在索引语句中指定,否则,将使用选项的默认值。
在多处理器计算机中,就像其他查询那样,ALTER INDEX REBUILD 自动使用更多处理器来执行与修改索引相关联的扫描和排序操作。运行 ALTER INDEX REORGANIZE 时,无论是否有 LOB_COMPACTION,“max degree of parallelism”值均为单个线程化操作。有关详细信息,请参阅配置并行索引操作。
如果索引所在的文件组脱机或设置为只读,则无法重新组织或重新生成索引。如果指定了关键字 ALL,但有一个或多个索引位于脱机文件组或只读文件组中,该语句将失败。
重新生成索引
重新生成索引将会删除并重新创建索引。这将根据指定的或现有的填充因子设置压缩页来删除碎片、回收磁盘空间,然后对连续页中的索引行重新排序。如果指定 ALL,将删除表中的所有索引,然后在单个事务中重新生成。不必预先删除 FOREIGN KEY 约束。重新生成具有 128 个区或更多区的索引时,数据库引擎延迟实际的页释放及其关联的锁,直到事务提交。有关详细信息,请参阅删除并重新生成大型对象。
重新生成或重新组织小索引不会减少碎片。小索引的页面存储在混合区中。混合区最多可由八个对象共享,因此在重新组织或重新生成小索引之后可能不会减少小索引中的碎片。
在早期版本的 SQL Server 中,您有时可以重新生成非聚集索引来更正由硬件故障导致的不一致。在 SQL Server 2008 中,您仍然可以通过脱机重新生成非聚集索引来纠正索引和聚集索引之间的这种不一致。但是,您不能通过联机重新生成索引来纠正非聚集索引的不一致,因为联机重新生成机制将会使用现有的非聚集索引作为重新生成的基础,因此仍存在不一致。相反,脱机重新生成索引将会强制扫描聚集索引(或堆),因此会删除不一致。与早期版本一样,建议通过从备份还原受影响的数据来从不一致状态进行恢复;但是,您可以通过脱机重新生成非聚集索引来纠正索引的不一致。
重新组织索引
使用最少系统资源重新组织索引。通过对叶级页以物理方式重新排序,使之与叶节点的从左到右的逻辑顺序相匹配,进而对表和视图中的聚集索引和非聚集索引的叶级进行碎片整理。重新组织还会压缩索引页。压缩基于现有的填充因子值。
如果指定 ALL,将重新组织表中的关系索引(包括聚集索引和非聚集索引)和 XML 索引。指定 ALL 时应用某些限制,请参阅“参数”部分的 ALL 定义。
禁用索引
禁用索引可防止用户访问该索引,对于聚集索引,还可防止用户访问基础表数据。索引定义保留在系统目录中。对视图禁用非聚集索引或聚集索引会以物理方式删除索引数据。禁用聚集索引将阻止对数据的访问,但在删除或重新生成索引之前,数据在 B 树中一直保持未维护的状态。
如果表位于事务复制发布中,则无法禁用任何与主键列关联的索引。复制需要使用这些索引。若要禁用索引,必须先从发布中删除该表。
使用 ALTER INDEX REBUILD 语句或 CREATE INDEX WITH DROP_EXISTING 语句启用索引。重新生成已禁用聚集索引不能在 ONLINE 选项设置为 ON 时执行。
设置选项
您可以为指定的索引设置选项 ALLOW_ROW_LOCKS、ALLOW_PAGE_LOCKS、IGNORE_DUP_KEY 和 STATISTICS_NORECOMPUTE,而不重新生成或重新组织该索引。修改的值立即应用于索引。
行锁和页锁选项
如果 ALLOW_ROW_LOCKS = ON 并且 ALLOW_PAGE_LOCK = ON,则当访问索引时将允许行级别、页级别和表级别的锁。数据库引擎将选择相应的锁,并且可以将锁从行锁或页锁升级到表锁。
如果 ALLOW_ROW_LOCKS = OFF 并且 ALLOW_PAGE_LOCK = OFF,则当访问索引时只允许表级锁。有关为索引配置锁定粒度的详细信息,请参阅自定义索引的锁定。
设置行锁或页锁选项时,如果指定 ALL,这些设置将应用于所有索引。基础表为堆时,通过以下方式应用这些设置:

联机索引操作
重新生成索引且 ONLINE 选项设置为 ON 时,基础对象、表和关联的索引均可用于查询和数据修改。更改过程中,排他表锁只保留非常短的时间。
重新组织索引始终联机执行。该进程不长期保留锁,因此,不阻塞正在运行的查询或更新。
只有在执行以下操作时,才能对同一个表执行并发联机索引操作:
- 创建多个非聚集索引。
- 在同一个表中重新组织不同索引。
- 在同一个表中重新生成不重叠的索引时,重新组织不同的索引。
同一时间执行的所有其他联机索引操作都将失败。例如,您不能在同一个表中同时重新生成两个索引或更多索引,也不能在同一个表中重新生成现有索引时创建新的索引。
有关详细信息,请参阅联机执行索引操作。
空间索引限制
重新生成空间索引时,基础用户表在索引操作持续期间不可用,因为空间索引持有架构锁。
对用户表的某一列定义了空间索引时,无法修改该表中的 PRIMARY KEY 约束。若要更改 PRIMARY KEY 约束,首先要删除该表的每个空间索引。修改 PRIMARY KEY 约束后,您可以重新创建每个空间索引。
在单个分区重新生成操作中,无法指定任何空间索引。但是,您可以在完整的分区重新生成过程中指定空间索引。
若要更改特定于某个空间索引的选项(例如 BOUNDING_BOX 或 GRID),您可以使用 CREATE SPATIAL INDEX 语句指定 DROP_EXISTING = ON,或删除该空间索引并创建一个新的空间索引。有关示例,请参阅 CREATE SPATIAL INDEX (Transact-SQL)。
数据压缩
若要评估更改压缩状态将对表、索引或分区有何影响,请使用 sp_estimate_data_compression_savings 存储过程。
以下限制适用于已分区索引:
- 使用 ALTER INDEX ALL ...
时,如果相应表具有非对齐索引,则无法更改单个分区的压缩设置。
- ALTER INDEX <index> ...REBUILD PARTITION ... 语法可重新生成索引的指定分区。
- ALTER INDEX <index> ...REBUILD WITH ... 语法可重新生成索引的所有分区。
大型对象数据类型压缩
重新组织索引时,除了重新组织一个或多个索引外,默认情况下还将压缩聚集索引或基础表中包含的大型对象数据类型 (LOB)。数据类型 image、text、ntext、varchar(max)、nvarchar(max)、varbinary(max) 和 xml 都是大型对象数据类型。压缩此数据可以改善磁盘空间使用情况:
- 重新组织指定的聚集索引将压缩该聚集索引的叶级别(数据行)包含的所有 LOB 列。
- 重新组织非聚集索引将压缩该索引中属于非键(包含性)列的所有 LOB 列。
- 如果指定 ALL,将重新组织与指定的表或视图相关联的所有索引,并压缩与聚集索引、基础表或带有包含列的非聚集索引相关联的所有 LOB 列。
- 如果 LOB 列不存在,则忽略 LOB_COMPACTION 子句。
二、语句
SET NOCOUNT ON DECLARE @Objectid INT, @Indexid INT,@schemaname VARCHAR(100),@tablename VARCHAR(300),@ixname VARCHAR(500),@avg_fip float,@command VARCHAR(4000) DECLARE IX_Cursor CURSOR FOR SELECT A.object_id,A.index_id,QUOTENAME(SS.NAME) AS schemaname,QUOTENAME(OBJECT_NAME(B.object_id,B.database_id))as tablename ,QUOTENAME(A.name) AS ixname,B.avg_fragmentation_in_percent AS avg_fip FROM sys.indexes A inner join sys.dm_db_index_physical_stats(DB_ID(),NULL,NULL,NULL,'LIMITED') AS B ON A.object_id=B.object_id and A.index_id=B.index_id INNER JOIN SYS.OBJECTS OS ON A.object_id=OS.object_id INNER JOIN sys.schemas SS ON OS.schema_id=SS.schema_id WHERE B.avg_fragmentation_in_percent>10 and B.page_count>20 AND A.index_id>0 AND A.IS_DISABLED<>1
--AND OS.name='book' ORDER BY tablename,ixname OPEN IX_Cursor FETCH NEXT FROM IX_Cursor INTO @Objectid,@Indexid,@schemaname,@tablename,@ixname,@avg_fip WHILE @@FETCH_STATUS=0 BEGIN IF @avg_fip<30.0 SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REORGANIZE '; IF @avg_fip>=30.0 AND @Indexid=1 BEGIN IF EXISTS (SELECT * FROM SYS.columns WHERE OBJECT_ID=@Objectid AND max_length in(-1,16)) SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '; ELSE SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '+N' WITH (ONLINE = ON)'; END IF @avg_fip>=30.0 AND @Indexid>1 BEGIN IF EXISTS (SELECT * FROM SYS.index_columns IC INNER JOIN SYS.columns CS ON CS.OBJECT_ID=IC.OBJECT_ID AND CS.column_id=IC.column_id
WHERE IC.OBJECT_ID=@Objectid AND IC.index_id=@Indexid AND CS.max_length in(-1,16) ) SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '; ELSE SET @command=N'ALTER INDEX '+@ixname+N' ON '+@schemaname+N'.'+ @tablename+N' REBUILD '+N' WITH (ONLINE = ON)'; END --PRINT @command EXEC(@command) FETCH NEXT FROM IX_Cursor INTO @Objectid,@Indexid,@schemaname,@tablename,@ixname,@avg_fip END CLOSE IX_Cursor DEALLOCATE IX_Cursor
注意:该语句不适合所有人,大家根据自己的需求进行修改。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号