
SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引
概述
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成。
既可以使用聚集索引来为表或视图定义非聚集索引,也可以根据堆来定义非聚集索引。非聚集索引中的每个索引行都包含非聚集键值和行定位符。此定位符指向聚集索引或堆中包含该键值的数据行。
非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述:
- 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。该指针由文件标识符 (ID)、页码和页上的行数生成。整个指针称为行 ID
(RID)。
- 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
对于索引使用的每个分区,非聚集索引在 index_id >0 的 sys.partitions 中都有对应的一行。默认情况下,一个非聚集索引有单个分区。如果一个非聚集索引有多个分区,则每个分区都有一个包含该特定分区的索引行的 B 树结构。例如,如果一个非聚集索引有四个分区,那么就有四个 B 树结构,每个分区中一个。
根据非聚集索引中数据类型的不同,每个非聚集索引结构会有一个或多个分配单元,在其中存储和管理特定分区的数据。每个非聚集索引至少有一个针对每个分区的 IN_ROW_DATA 分配单元(存储索引 B 树页)。如果非聚集索引包含大型对象 (LOB) 列,则还有一个针对每个分区的 LOB_DATA 分配单元。此外,如果非聚集索引包含的可变长度列超过 8,060 字节行大小限制,则还有一个针对每个分区的 ROW_OVERFLOW_DATA 分配单元。有关分配单元的详细信息,请参阅表组织和索引组织。B 树的页集合由 sys.system_internals_allocation_units 系统视图中的 root_page 指针定位。
要很好的理解这篇文章的内容之前需要先阅读我前面写的上中部分的两篇文章:
正文
非聚集索引结构

生成测试数据
CREATE TABLE Torder (ID INT IDENTITY(1,1) NOT NULL, NAME CHAR(100) NOT NULL, pro VARCHAR(8000) NULL, Statu INT NOT NULL, IDATE DATETIME DEFAULT(GETDATE()) ) GO ---插入1000条测试数据 DECLARE @ID INT=1 WHILE(@ID<=1000) BEGIN INSERT INTO Torder(NAME,pro,Statu)VALUES('商品'+CONVERT(CHAR(20),@ID),REPLICATE(1,8000),LEFT(@ID,1)) SET @ID=@ID+1 END GO ---创建非聚集索引 CREATE INDEX IX_Torder ON Torder (NAME,Statu ) INCLUDE(IDATE) SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page FROM sys.objects so INNER JOIN sys.partitions sp ON so.object_id = sp.object_id INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id WHERE so.object_id = object_id('Torder')

由于创建的表只有非聚集索引,所以整个表的页存储中有三部分数据:堆页面、溢出页面、索引页面;
堆中共有20个数据页和一个IAM页;
溢出单元有1001个页面包括一个IAM页;
索引中共有20个页其中18个数据页一个ROOT页和一个IAM页.
一个堆页对应多个溢出页,因为Pro有8000个字节所以一行占一页,而表的其它字段只有116个字节一个堆页可以存50条记录,所以并不是一个溢出页就唯一对应一个堆页
分析页的存储信息
---开启跟踪标志 DBCC TRACEON(3604,2588) --DBCC TRACEOFF(3604,2588) ---获取对象的数据页,结构:数据库、对象、显示 DBCC IND(Ixdata,Torder,-1)
上一章中已经讲过了堆页面和溢出页面,所以现在就讲非聚集索引页
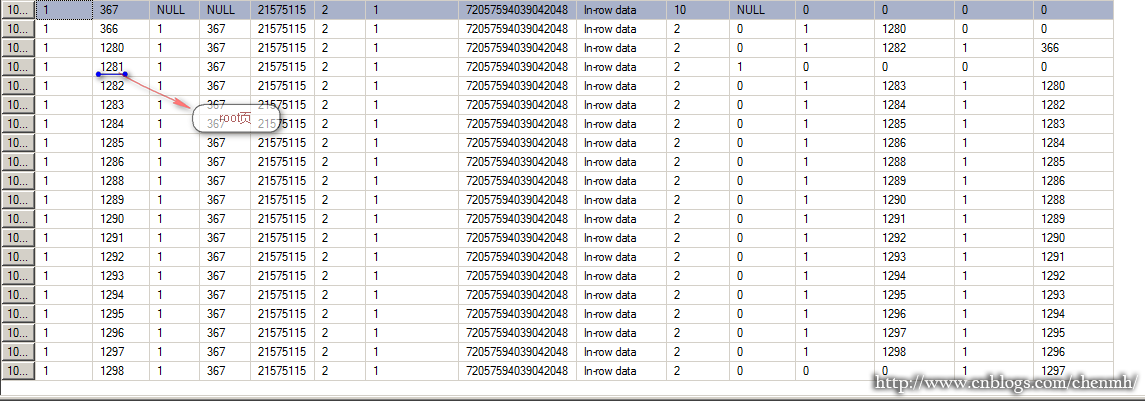
看过前面的文章应该一眼就能看出1281页是ROOT页,现在就分析1281页
分析非聚集索引根页
DBCC page(Ixdata,1,1281,3)

现在来分析行定位指针是怎样的:0x6801000001002F00
除去开头的16进制标示,剩下总共8个字节,从右往左其中行号2个字节,文件标示ID2个字节,剩下的4个字节就是页号了,所以
行号(002f)=47
文件页(0001)=1
页号(00000168)=360页
现在查看360页的信息
DBCC page(Ixdata,1,360,3)

47行的记录正好是“商品150”
分析非聚集索引索引页
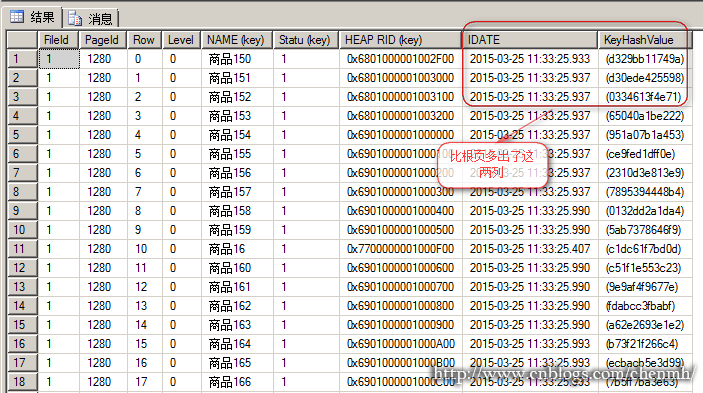
通过对比会发现索引页比根页多出了索引包含列值和键的哈希值,这个里面的keyhashvalue应该是NAME和statu字段的值通过某种方法算出来的,这里只是猜测通过平时的查询你会产生这样的猜测。
测试简单的查询
这里的'商品150'和'商品153'都是1280页中的记录,1280页是索引页,其中'商品150'是该页的第一条记录
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品153' --COMMIT 另开一个窗口 SELECT [request_session_id], c.[program_name], DB_NAME(c.[dbid]) AS dbname, [resource_type], [request_status], [request_mode], [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, p.[index_id] FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p ON a.[resource_associated_entity_id]=p.[hobt_id] LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查询申请锁的数据库 ORDER BY [request_session_id],[resource_type]



从上面的查询过程可以知道页面总共读取了三次(索引叶一次堆页一次溢出页一次)。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ GO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品150'



通过对比查询'商品150'和'商品153'可以看到如果查找的页面的第一条记录,它需要再读取该索引页的前一个页面,如果该索引页是第一页就无需再读除本身的其他索引页了,文章写到后面反过来思考才知道为什么非聚集索引还需要多查找一个页面了。因为非聚集索引是允许存在重复值所以才需要再往前查找,如果前面一个页查找不到则结束,如果前面一个页还没查完会再往前一个页进行查,当然查询商品153的时候就已经判断了前一条记录的键值是不一样的否则也是要再查询前一个页,这也是非聚集索引的一个特殊情况吧!
索引扫描
update Torder set statu=100 where id=1 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ GO BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE [Statu]=100
该查询总共扫描了18个索引页+1个堆页+1个溢出页.
创建聚集索引
ALTER TABLE dbo.Torder ADD CONSTRAINT PK_Torder PRIMARY KEY CLUSTERED ( ID ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page FROM sys.objects so INNER JOIN sys.partitions sp ON so.object_id = sp.object_id INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id WHERE so.object_id = object_id('Torder')

非聚集索引数据页比之前少了一页

由于现在的指针比之前的16进制指针要所占有的字节要少,所以只需要17个页面就可以存下。
分析索引页148
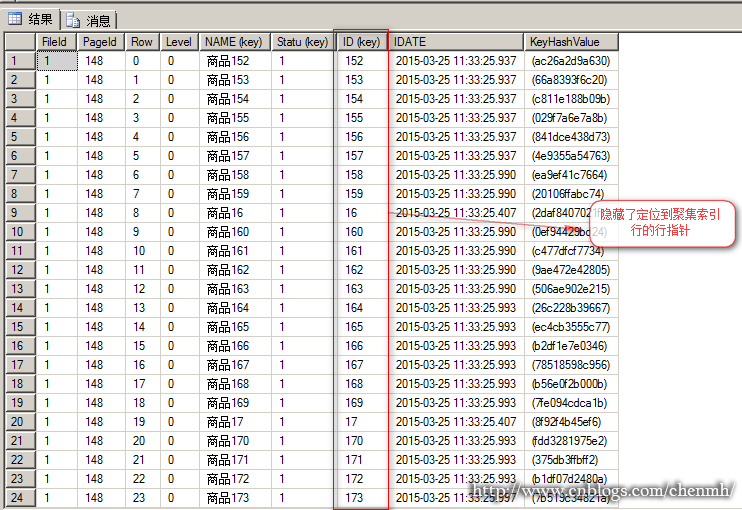
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN SELECT [ID] ,[NAME] ,[pro] ,[Statu] ,[IDATE] FROM [Ixdata].[dbo].[Torder] WHERE NAME='商品152' 在另一个窗口打开 SELECT [request_session_id], c.[program_name], DB_NAME(c.[dbid]) AS dbname, [resource_type], [request_status], [request_mode], [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, p.[index_id] FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p ON a.[resource_associated_entity_id]=p.[hobt_id] LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查询申请锁的数据库 ORDER BY [request_session_id],[resource_type]
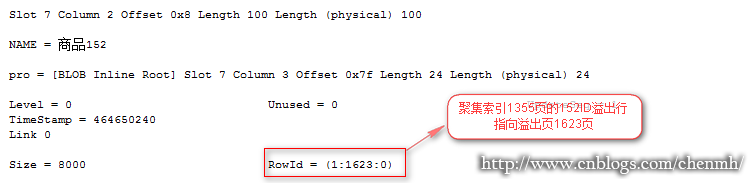


从上面的逻辑读取和查询步骤可以证实前面的猜测,应该是隐藏了一张行定位表。
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
查看索引统计信息
DBCC SHOW_STATISTICS ("dbo.Torder", IX_Torder);

前面建的包含索引有这三种组合方式,所以组合索引的第二个字段不被用来单独做查找。
总结
非聚集索引和聚集索引不一样,聚集索引索引页的键值指向数据页的具体行;而非聚集索引不存在数据页,非聚集索引的索引页中的记录行指向聚集索引或者堆的具体数据页的数据行然后来获取记录,如果堆或聚集索引还存在溢出的话,从堆或者聚集索引的数据记录还有指向溢出页面的指针。
补充一下在非聚集索引中存在聚集索引与堆的优点,看完上文你会发现非聚集索引的数据页记录的行定位指针分别指向聚集索引或堆的行,但是指向聚集索引的行定位是逻辑值而指向堆的是实际的rid值,逻辑值的好处就是在聚集索引发生分页的情况下,逻辑值不用改变也就无需更新非聚集索引的指针。
花了四天时间终于把这个系列的写完了,重新去理解一遍把以前的一些不理解的知识点给弄明白了,还是收获很多。
如果文章对大家有帮助,希望大家能给个推荐,谢谢!!!
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号