
SQL Server 查询分解
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/查询步骤
概述
查询步骤是很基础也挺重要的一部分,但是我还是在周围发现有些人虽然会语法,但是对于其中的步骤不是很清楚,这里就来分解一下其中的步骤,在技术内幕系列里面都会有讲到。
目录
流程图

(1)FROM <LEFT_TABLE> <JOIN_TYPE> JOIN <RIGHT_TABLE> ON <ON_PREDICATE> |<LEFT_TABLE> <APPLY_TYPE> APPLY <RIGHT_TABLE_EXPRESSION> AS <alias> |<LEFT_TABLE> pivot(<pivot_specification>) AS <alias> |<LEFT_TABLE> UNPIVOT(<unpivot_specification>) AS <alias> (2)WHERE<where_predicate> (3)GROUP BY<group_by_specification> (4)HAVING<having_predicate> (5)SELECT <DISTINCT> <TOP> <select_list> (6)ORDER BY<order_by_list>
步骤分解
测试数据
--创建测试表 --创建顾客表 CREATE TABLE Customers (custid INT NOT NULL PRIMARY KEY, city NVARCHAR(20) NOT NULL ) go INSERT INTO Customers VALUES(1,'深圳'),(2,'广州'),(3,'武汉'),(4,'上海'),(5,'北京') --创建订单表 CREATE TABLE Orders (orderid INT NOT NULL PRIMARY KEY IDENTITY(1000,1), custid INT NOT NULL, orderdate DATETIME NOT NULL ) GO INSERT INTO Orders(custid,orderdate)values(1,'2013-10-1 00:00:00'),(1,'2013-10-2 00:00:00'),(1,'2013-10-3 00:00:00'),(1,'2013-10-4 00:00:00'),(2,'2013-10-1 00:00:00'),(2,'2013-10-3 00:00:00'),(2,'2013-10-5 00:00:00'),(3,'2013-10-3 00:00:00'),(3,'2013-10-7 00:00:00'),(4,'2013-10-1 00:00:00') --创建订单明细表 CREATE TABLE [OrderDetails]( [orderid] [int] NOT NULL, [productid] [int] NOT NULL, [unitprice] [money] NOT NULL, [qty] [smallint] NOT NULL CONSTRAINT [PK_OrderDetails] PRIMARY KEY CLUSTERED ( [orderid] ASC, [productid] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO INSERT INTO OrderDetails VALUES(1000,10,5.00,1),(1000,14,6.00,2),(1001,10,5.31,3),(1001,11,5.22,1),(1001,12,3.20,3),(1001,13,4.10,2),(1002,11,7.00,1),(1003,12,8.00,5),(1004,13,8.41,1),(1004,11,6.65,1),(1005,18,7.41,1),(1006,17,10.00,1)
--查询深圳、广州每一个顾客每笔金额大于10的订单,并按订单价格倒序排序 SELECT TA.custid,TB.orderid,SUM(tc.unitprice*tc.qty) AS price FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid LEFT JOIN OrderDetails TC ON TB.orderid=tc.orderid WHERE TA.city IN('深圳','广州') GROUP BY TA.custid,TB.orderid HAVING SUM(tc.unitprice*tc.qty)>10 ORDER BY price DESC
第一步:FROM阶段
这一步是一个T-SQL语句的开始,一般紧接着FROM的这个表被称作左表,例如a inner join b inner join c,首先a作为左表然后关联b,a和b关联的结果作为下一个运算的左表关联c。在FROM阶段涉及的表运算会有JOIN(LEFT JOIN,RIGHT JOIN,FULL JOIN),APPLY(CROSS APPLY,OUTER APPLY),PIVOT,UNPIVOT
对于上面的查询例子:FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid的左连接的分解是这样的
第一步交叉连接、SELECT * FROM Customers TA CROSS JOIN Orders TB---首先进行交叉连接得到的行数是5*10=50行
第二步ON筛选、将TA.custid=TB.custid以外的结果排除,可以等价于SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid
第三步、将主表(左边的表)不在第二步的行加上,可以等价于 SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid union all SELECT * FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid WHERE TB.custid IS NULL
所以其它几个表运算只要大家知道怎么使用就可以了,大家只要明白它在T-SQL语句中的位置就行。
这里要注意一点:大家理解了JEFT JOIN的原理之后就明白"on"筛选对查询的删除不是最终的,在上面的第三步会把主表的一些行又添加上来,所以我们有时候写LEFT JOIN的时候有的人不太明白为什么ON 后面加AND和把AND放在WHERE里面的得到的结果不一样,就是这个原理了,WHERE操作对查询的删除才是最终的。
第二步:WHERE阶段
当然后面的有些阶段都是可选的也就是有的查询不一定会用到,但是这里为了讲述整个过程,所以就一步一步的来讲,在FROM 阶段结束之后会生成一张虚拟表,进入第二阶段也就是WHERE阶段,在WHERE阶段是对前一阶段(FROM阶段)结果返回行进行筛选,例如上面的查询筛选城市是‘深圳’,‘广州’的顾客
所以为什么把select步骤里面生成的列写在where里面无法识别就是因为where在select操作之前。
第三步:GROUP BY阶段
GROUP BY 操作是分组操作,确保进行分组的属性集每一个组都是唯一的,GROUP BY 操作的数据是WHERE阶段筛选之后的数据,例如上面的查询例子是将custid,orderid作为一行来进行分组,上面的例子是每一个顾客每一笔订单的消费金额。
第四步:HAVING阶段
HAVING阶段是在GOUP BY 阶段返回TURE之后才会有这步操作,HAVING是对上一步的分组之后的数据进行筛选的步骤,例如筛选消费订单金额大于10的顾客订单
第五步:SELECT阶段
select阶段是返回上一步操作得到的虚拟表的数据列,所以也就是为什么存在group by的分组查询,select里面的列跟group by 的分组列需要一致的原因了,聚会函数生成的列除外,因为select查询的基础列就是来源于前面的步骤,select阶段会涉及到去重复distinct当然如果前面存在分组也就不存在重复了,TOP操作,还有一些字段之间的算法运算,子查询等等。
第六步:ORDER BY阶段
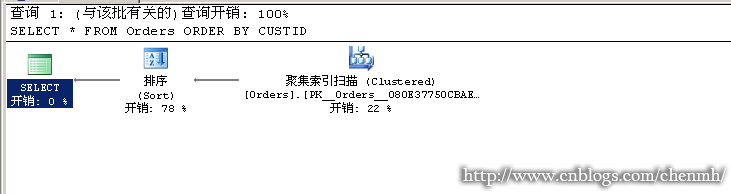
这一步是整个过程的最后一步操作,因为它在SELECT阶段之后,所以对于SELECT里面生成的字段别名在ORDER BY 中可以使用别名,对于一张表,表代表的是集合,集合是没有顺序的,当一个查询带有ORDER BY时我们可以把它理解成游标,游标是有特定的排序,所以为什么一个查询加上ORDER BY 操作之后会变的很慢了,因为它需要进行排序操作。
---当查询没有排序时 SELECT * FROM Orders
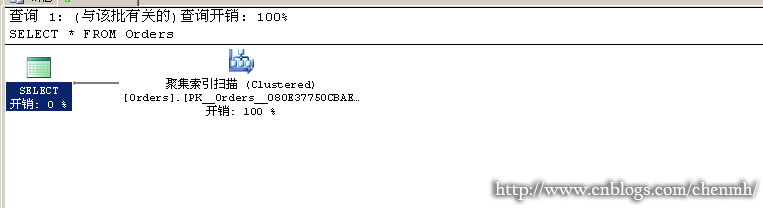
---当查询有排序时 SELECT * FROM Orders ORDER BY CUSTID
TOP于ORDER BY的关系
order by 是保证结果排序顺序,top是一个逻辑运算操作
对于一个没有外部查询的语句,order by 操作既能保证结果根据制定条件的排序,又能满足TOP的逻辑运算(查询最小的三个orderid) SELECT TOP (3) * FROM Orders ORDER BY ORDERID
对于存在外部查询时,order by在作用仅仅是保证top的逻辑结果的正确输出,而不能保证查询结果的排序,虽然我们可能查询出的结果是按照这个方式排序。 ---当不指定TOP时报错 SELECT * FROM(SELECT custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A ---当指定 SELECT * FROM(SELECT TOP (3) custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A
总结
理解完了整个查询的过程,也就能能理解为什么SQLServer这么耗内存了,每一步的操作都是生成一张虚拟表进入下一步操作,理解了整个查询过程 之后对我们理解T-SQL语法很有帮助,同时也有利于分析语句。
如果文章对大家有帮助,希望大家能给个赞,谢谢!!!
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步