
SQL Server 索引和表体系结构(聚集索引)
聚集索引
概述
关于索引和表体系结构的概念一直都是讨论比较多的话题,其中表的各种存储形式是讨论的重点,在各个网站上面也有很多关于这方面写的不错的文章,我写这篇文章的目的也是为了将所有的知识点尽可能的组织起来结合自己对这方面的了解些一篇关于的详细文章出来,同时也会列出一些我自己有疑惑的地方拿出来探讨,介于表达能力有限,有些地方可能无法表达的很明了,还望大家包涵;对于文章中有不对的地方也希望大家能提出,写文章的目的就是为了共享资源;对于这个系列会写5篇文章,在接下来的几天里逐一发布,分别是“聚集索引体系结构”,“非聚集索引体系结构”,“堆体系结构”,“具有包含列的索引”,“表组织和索引组织”。
正文
- 定义
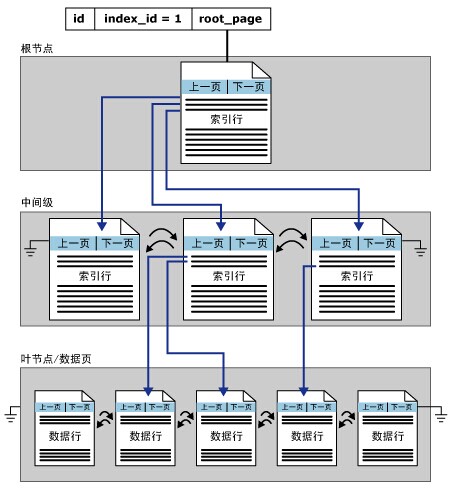
在 SQL Server 中,索引是按 B 树结构进行组织的。索引 B 树中的每一页称为一个索引节点。B 树的顶端节点称为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中。
- 聚集索引单个分区中的结构
- 存储
在SQL Server中,存储数据的最小单位是页,数据页的大小是8K,,8个页组成一个区64K,每一页所能容纳的数据为8060字节,聚集索引的叶节点存储的是实际数据行,而且每页数据行是顺序存储,数据行基于聚集索引键按顺序存储,所以一个数据表只能建一个聚集索引。
非叶子节点(跟节点和中间级)存储的是索引记录,一条索引记录包含:键值(键值也就是聚集索引列的字段值)+指针(指向索引页或者数据页)
由于数据存储在数据页中,索引建存储在索引页中,所以检索单个索引列的数据要快于检索数据记录,因为不需要读取数据页,只需要在索引页中检索数据。

- 聚集索引列选择
窄列(字段长度短的列):由于索引页存储的是索引记录,索引记录存储的是索引建值和指针,为了让索引列存储更多的索引记录,所以我们选择窄列。
不频繁更新的列:由于索引记录的指针指向数据页,如果数据频繁更新会造成索引页更新,同时由于非聚集索引的数据页的行指针指向聚集索引的数据行,更新聚集索引同时也会造非聚集索引页的更改造成IO消耗。
不重复的列:由于聚集索引的数据页中的数据记录是按聚集建的顺序存储,当向聚集列中插入重复的记录,当数据页超过8060K就会造成分页,分页会将原页中的一半记录插入到新页中,而产生索引碎片。
可以使用自增列作为聚集索引列(这里只是给个建议,需要根据实际的业务来)
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号