
Scala基础知识笔记1
上一篇文章介绍了如何下载scala, 因为在官网上点击下载按钮无法下载,
下面介绍scala的基础语法:
1 scala和java的关系
Scala是基于jvm的一门编程语言,Scala的代码最终会经过编译成字节码,交给java虚拟机来运行
Scala和java可以无缝互操作,Scala可以任意调用java代码、
2 Scala的解释器 repl
scala的解释器会快速编译scala代码为字节码然后交给jvm来执行。
repl : read 取值 ---> evaluation 求值 ----> print 打印 ----> loop 循环
3 声明变量和常量和指定类型
声明变量使用 var 这个和 js类似
声明常量使用 val 声明常量赋值后 这个常量将不能再被改变值
定义中建议使用常量声明,类似于spark的大型复杂系统中,需要大量网络传输数据,如果使用var 可能会担心值被错误的更改,这个类似于java中使用final关键字来
提高系统健壮性一样。
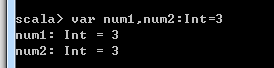
eg: var name:String = "zm"
var name1, name2:String = "zm"
4 数据类型和操作符
基本数据类型: Byte、Char、Short、Int、Long、Float、Double、Boolean。 和java的包装类型一致,没有基本数据类型
操作符: 和java的操作符一致, 唯一区别是 ++ --没有, 比如 a++ 必须写成 a += 1
5 函数调用
调用函数如果不需要传递参数 那么 scala 允许省略掉括号。
6 块表达式:
指的就是{}中的值, 最后一个语句的值就是块表达式的返回值。
eg:
var a = 1;
var b = 2;
var c = 3;
var d = if(a < 10) { b = b + 1; c + 1 }
println(d)
结果是4 也就是将 c+1的结果返回给了d
7 条件和循环案例:
/* if 案例 val age = 34; if(age < 10) { println("you are child") }else{ println("you are adult") }*/ // 块表达式 /* var a = 1; var b = 2; var c = 3; var d = if(a < 10) { b = b + 1; c + 1 } println(d)*/ // while 和java使用规则一样 /* var n = 10 while(n>0) { println(n) n -= 1 }*/ // for循环 scala只有如下这种形式的for写法 // 1 简易版的for // var n=10; for(i<- 1 to n) println(i) //for(c<-"hello world") println(c) // 跳出循环 scala没有类似java的break语句 但可使用 boolean变量 return或Breaks的break函数 /* import scala.util.control.Breaks._ breakable{ var n=10; for(i<-1 to 10){ if(i==3) { break; } println(i); } }*/ // 多重for /* for(i<-1 to 9; j<-1 to 9){ println(i*j +" " ) }*/
8 定义函数:
定义函数的函数名、参数、函数体,返回值类型, 其中形参和返回值类型都使用 :类型 方式 , 如果函数有返回值 那么需要在形参定义完成后 在使用 = {函数体}
如果定义的函数名和函数体之间没有用 = 关联 那么默认返回值类型是Unit,并且定义的是一个过程而不是一个函数 过程通常用于不需要返回值的函数。
使用 def关键词定义, 注意 参数和函数体之间使用 = 来连接, 如果给默认参数赋初始值 需要在定义形参中里使用 = 赋值
// 代码块中最后一行的返回值就是整个函数的返回值。与Java中不同,不是使用return返回值的。 不过使用 return 我试验了也没发现报错 /*def sayHello(name:String):String ={ "hello " + name } var name = sayHello("zm") println(name)*/ /*def fab(n:Int):Int={ if(n <=1) return 1 else return 3 } var result = fab(5) println(result)*/ // 给默认参数赋初始值 /* def sayHello(name:String, age:Int=32) = { println(name + "| " + age) } sayHello("zm",34) sayHello("zm")*/
9 函数可变参数 + 序列传递 + 递归函数写法
函数定义中 变长参数使用 形参定义后需要增加一个*表示可变参数
object ScalaExample { def main(args: Array[String]): Unit = { // println(sum(1,2,3)) // 将已有序列直接调用变长参数函数, 需要使用特殊语法让scala解释器识别 ---》 :_* //var result = sum(1 to 5:_*) //println(result) println(sum2(1 to 5:_*)) // 1 to 5表示序列 序列传递给可变参数的函数 } // 定义可变参数函数 def sum(nums:Int*)= { var res = 0; for(num<-nums) { res += num } res } // 定义递归函数 def sum2(nums:Int*) :Int={ if(nums.length==0) 0 else nums.head + sum2(nums.tail:_*) } }
10 过程 lazy值 异常
1 定义函数时,如果函数体直接包裹在了花括号里面,而没有使用=连接,则函数的返回值类型就是Unit。这样的函数就被称之为过程。过程通常用于不需要返回值的函数。
// 过程是函数的一个子集 不需要使用 = 和函数体关联 表示没有返回值的函数 /*def sayHello(name:String){ println("hello: " + name) } var result = sayHello("zm") println(result) // 结果是()*/ // 如果将一个变量生命为lazy //即使文件不存在,也不会报错,只有在第一个使用该变量时如果文件不存在才会报错,证明了表达式计算的lazy特性。 // 这种特性对于特别耗时的计算操作特别有用,比如打开文件进行IO,进行网络IO等 import scala.io.Source._ lazy val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString // 异常的写法和Java很类似 例子如下 注意 catch 里面的写法 _: XXException => dosomething try { throw new IllegalArgumentException("x should not be negative") } catch { case _: IllegalArgumentException => println("Illegal Argument!") } finally { print("release resources!") }
11 数组 和 遍历的集中方式
scala数组底层实际上是Java数组,比如scala的字符串数组在底层就是Java的String[] , 整数数组底层就是Java的Int[]
for遍历几个方式: 增强for循环 正常方式遍历 跳跃遍历 翻转遍历 , 定长变长数组定义和互换和变长数组增减元素写法
// 定长数组 定义定长数组方式1 var a = new Array[Int](3) a(0) = 2 // 定义定长数组方式2 var b = Array(1,2,3) // 定义变长数组 import scala.collection.mutable.ArrayBuffer val b1 = new ArrayBuffer[Int]() // 使用+=操作符,可以添加一个元素,或者多个元素 b1 += 1 b1 += (2,3,4,5) // 使用++=操作符,可以添加其他集合中的所有元素 b1 ++= Array(6,7,8,9,10) // for(c<-b1) println(c) // 删除尾部的几个元素 b1.trimEnd(5) // for(c<-b1) println(c) // 添加元素 // 在index为5的位置上插入数字6 b1.insert(5,6) // 在index为5的位置上插入数字6 b1.insert(6,7, 8, 9, 10)// 在index为6的位置上插入数字 7,8,9,10 //for(c<-b1) println(c) // 增强for的遍历 //删除元素SW b1.remove(1) // 移除掉index为1上的元素 //for(c<-b1) println(c) // 1 3 4 5 6 7 8 9 10 b1.remove(1,3) //移除掉index为1上包含index为1开始向后一致移除三个 1 6 7 8 9 10 // for(c<-b1) println(c) //var d = b1.toArray // 变长数组转换为定长数组 //var c = b.toBuffer // 定长数组转换为变长数组 // 数组普通遍历 // for(i<- 0 until b1.length) println(b1(i)) // for(i<- 0 until (b1.length,2)) println(b1(i)) // 跳跃遍历 间隔两个 取第三个 //for(i<- (0 until b1.length).reverse) println(b1(i)) // 翻转遍历 间隔两个 取第三个
val a = Array(1,2,4,3,5)
val sum = a.sum // 求和
val max = a.max // 获取最大值
// 排序
scala.util.Sorting.quickSort(a)
print(a.mkString(",")) // 获取数组中所有元素内容指定间隔符间隔 1,2,3,4,5
// yield 根据条件选择构建数组
/*
对于for循环的每次迭代,yield都会生成一个将被记住的值。就像有一个你看不见的缓冲区,for循环的每一次迭代都会将另一个新的值添加到该缓冲区
当for循环结束运行时,它将返回所有已赋值的集合。返回的集合的类型与迭代产生的类型相同,因此Map会生成Map,List将生成List,等等。
另外请注意,最初的集合没有改变。for / yield构造根据您指定的算法创建一个新的集合。
* */
// var a = Array(1,2,3,4,5,6)
//var b = for(c<-a) yield c*2
// var b = for(c<-a if c%2==0) yield c*c // yield + for + if 组合筛选构建新数组
//var b = a.filter(_%2==0) // 2-4-6
// var b = a.filter(_%2==0).map(_*2) // 4-8-12 通过数组函数来 筛选和构建新数组
// println(b.mkString("-"))
var a = ArrayBuffer(1,2,3,4,5,-8,-3,11,-5,-9)
/* var foundFirstNegative = false
val keepIndexes = for (i <- 0 until a.length if !foundFirstNegative || a(i) >= 0) yield {
if (a(i) < 0) foundFirstNegative = true
i
}
for (i <- 0 until keepIndexes.length) { a(i) = a(keepIndexes(i)) }
a.trimEnd(a.length - keepIndexes.length)
println(a.mkString("-"))
*/
// 遍历数组里所有元素,当找到第一个负数时 设置flag位 同时标注每个元素如果是大于0下的数组索引位置
/* var firstNagivate = false
var indexFlag = for(i<- 0 until a.length if(!firstNagivate || a(i) > 0)) yield {
if(a(i) < 0) firstNagivate = true
i
}*/
//println(indexFlag.mkString("-"))
/* for(i<- 0 until( indexFlag.length)) { // 将找到元素位置的数据重写到 原来数组中
a(i) = a(indexFlag(i))
}
a.trimEnd(a.length - indexFlag.length) // 将原来数组中不需要的数据截取掉
println(a.mkString("-"))*/
/* println("数组长度为: " + indexFlag.length)
var newA = new Array[Int](indexFlag.length)
for(i<- 0 until( indexFlag.length)) { // 将找到元素位置的数据重写到 新数组中
// newA(i+1) = a(indexFlag(i))
println(i+ " | "+ a(indexFlag(i)))
newA(i) = a(indexFlag(i))
}*/
12 Map 和 Tuple
//map 学习 // 不可变map () val ages = Map("zm"->32,"liangliang"->31) //ages("zm") = 31 不可以赋值修改 // 可变map val ages1 = scala.collection.mutable.Map("zm"->32,"liangliang"->31) //val ages2 = scala.collection.mutable.Map(("zm",32),("liangliang",31)) 或者这种方式定义 ages1("zm")=31 // 修改可变map的value值 // 创建空的map //val ages2 = new mutable.HashMap[String,Int] //val result = ages1.getOrElse("zm",42); // 获取map的key值 //println(result) ages1 += ("yan"->34,"mei"->30 ) // 可变map增加元素 //ages1 -= "yan" // 可变map删除元素 // println(ages1.mkString(",")) /* val ages4 = Map("zm"->32) // 不可变map 增减元素是通过 + - 方式并构建一个新的map接受 可变map增减是通过 += -=方式但必须要构建新的map val ages5 = ages4 + ("liang"->30) //println(ages5.mkString(",")) val ages6 = ages5 - "liang" println(ages6.mkString(","))*/ // map的遍历 //for((k,v)<-ages1) println(k+"," +v) // val ages6 = for((k,v)<-ages1) yield(v,k) // 使用 yield构建新的map //println(ages6.mkString(",")) //for(k<-ages1.keySet) println(k) //for(v<-ages1.values) println(v) // 对map的key进行排序 看了下 只有immutable包下有这个排序的方法 返回给一个新的map // val ages7 = scala.collection.immutable.SortedMap("liang"->31,"ping"->29,"ming"->32) // println(ages7.mkString(",")) //val ages8 = new scala.collection.mutable.LinkedHashMap[String,Int] // 按照插入顺序存放k-v 否则map的k是没有顺序的 //ages8("zm")=34 // 元组 tuple 在spark中有大量的tuple的使用,是一种很灵活的数据结构 val t = ("zm",32) //println(t._1) val names = Array("zm","ping") val age1s = Array(34,30) val nameages = names.zip(age1s) // zip操作 替代了自定义javabean方式 for ((name, age) <- nameages) println(name + ": " + age)
// tuple ,就是由()包起来,和数据库中一条记录概念类似 ,或者理解为 是一个特殊类型的数组,数组中存储的是不同类型的值,一个元组中最多能存22个元素
var firstTuple = ("str",1,0.5)
println(firstTuple._1) // 返回 str 字符串 注意使用时不要写成按照 数组方式获取值了 这不是数组
posted on 2018-12-22 15:59 ligongda2006 阅读(178) 评论(0) 编辑 收藏 举报

