


由于刚刚进入研究生阶段,通过几个月对大数据的学习,从java到hadoop,再到scala到spark。在这我写一下我在ubuntu系统下intelliJ IDEA的安装和配置。首先我的ubuntu系统是14.04的,hadoop-2.6.0,java-1.7.0,scala-2.10.5
在配置intelliJ IDEA前需要把java以及spark、scala需要安装配置好
第一步下载IDEA压缩包(我下的是ideaIC-15.0.2.tar),然后将压缩包拷入ubuntu下home目录下,然后解压到opt目录下
#sudo tar zxvf ideaIC-15.0.2.tar
#sudo mv idea-IC-143.1184.17 /opt
第二步下载插件
首先启动intelliJ IDEA:在命令行终端中,进入$IDEA_HOME/bin目录,输入./idea.sh进行启动,进入如下界面,然后选择右下角“plugins”

然后进入以下界面,点击Plugins,由于Scala插件没有安装,需要点击”Install JetBrains plugins"进行安装,如下图所示:
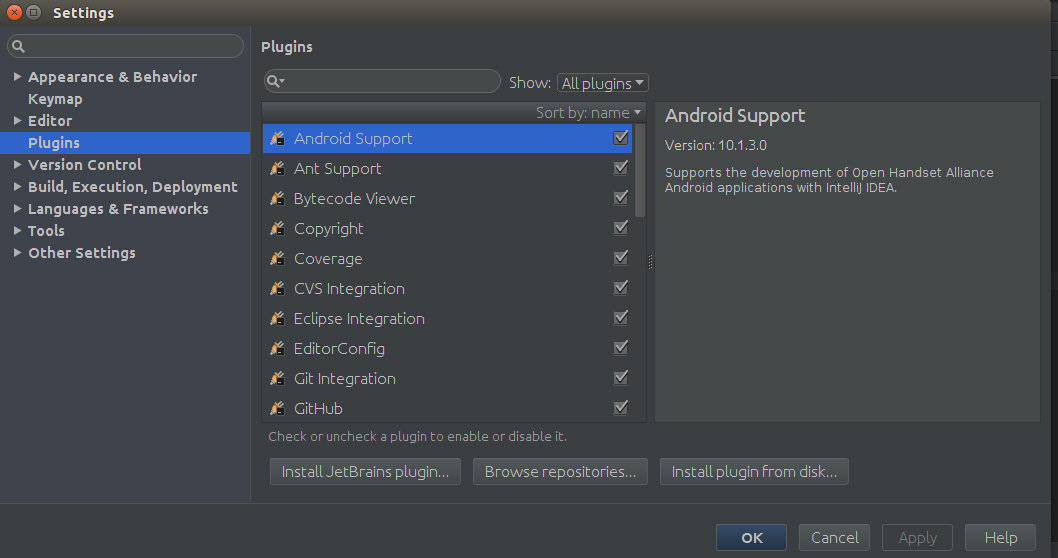
然后进入以下界面,点击下载,等下载安装好后,点击close就ok了
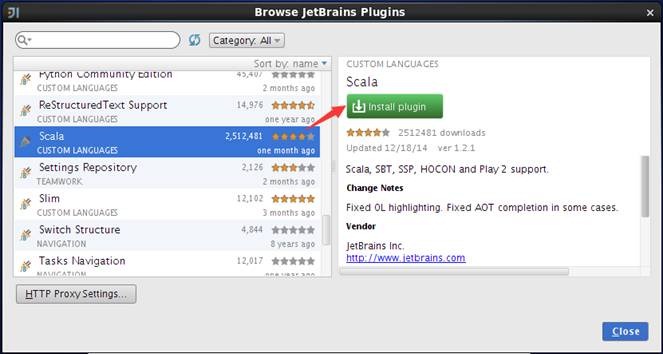
安装插件后,在启动界面中选择创建新项目,弹出的界面中将会出现"Scala"类型项目,如下图,选择scala-》scala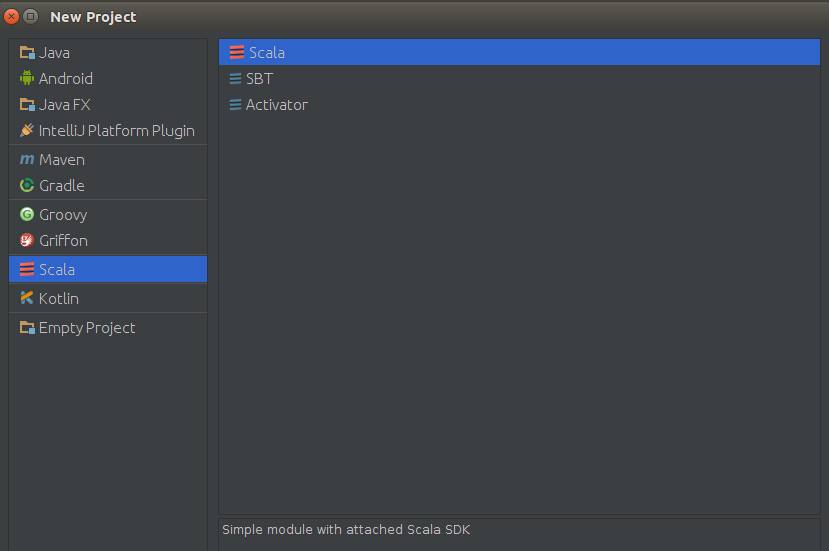
点击next,就如以下界面,project name自己随便起的名字,把自己安装的scala和jdk选中,注意,在选择scala版本是一定不要选择2.11.X版本,那样后续会出大错!完成后,点击Finish

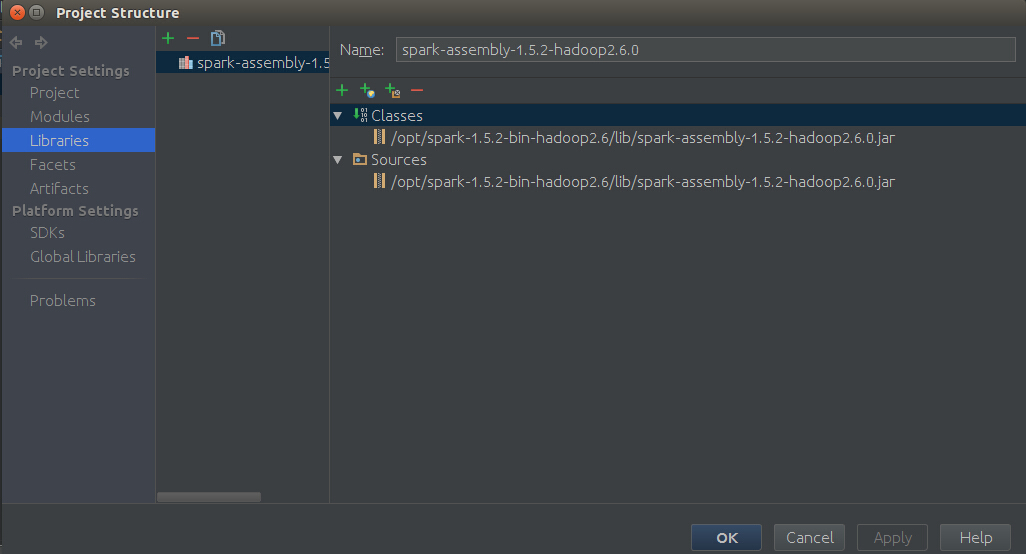
然后再File下选择project Structure,然后进入如下界面,进入后点击Libraries,在右边框后没任何信息,然后点击“+”号,进入你安装spark时候解压的spark-XXX-bin-hadoopXX下,在lib目录下,选择spark-assembly-XXX-hadoopXX.jar,结果如下图所示,然后点击Apply,最后点击ok
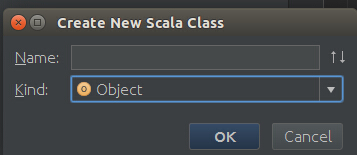
现在我们就可以在src下创建一个包,然后创建一个Object,如下图,然后就可以用scala来编写代码了。
二,编写代码
我编写了一个小代码,单词计数,代码如下

在textFile("")中的内容为数据路径,然后点击Run就可以看到结果了。
过于包的导出以及在集群上运行下一篇介绍

