

直到现在为止,一致性哈希也没有一个非常明确的定义,多数文献还是从其应用场景之上对一致性哈希进行描述。“哈希”想必大家都已经了解,问题是何为“一致性”?
- 一致性
在讨论一致性哈希之前,先认识下“非一致性哈希”,显然HashMap属于此列。
当使用HashMap时,key被均匀地映射到数组之上,映射方法就是利用key的hash与数组长度取模(通过&运算)。
当put的数据超过负载因子loadFactor×2Len时,HashMap会按照2被的容量扩容。新put进来的数据会通过与新数组的长度取模的方式进行映射。那之前已经映射的数据该怎么办?通过查看HashMap代码的resize方法会发现,每次扩容都会把之前的key重新映射。
所以对HashMap而言要想获得较好的性能必须要提前估计所放数据集合的大小,以设计合适的初始化容量和负载因子。
2. 定义
但不是每个场景都像HashMap这么简单,比如在大型的P2P网络中存在上百万台Server,资源与Server的关系是以Key的形式映射而成,也就是说是一个大的HashMap,维护着每个Key在哪个Server之上,如果有新的节点加入或退出P2P网络,跟HashMap一样,也会导致映射关系的变化,显然不可能把所有的Key与Server的映射关系都调整一遍。这就需要一种方法,在哈希项发生变化是,不需要调整所有的节点,而达到继续维护哈希映射的关系。因此一致性哈希定义为:
"Consistent hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots".(http://en.wikipedia.org/wiki/Consistent_hashing)
就是说,”一致性哈希,就是提供一个hashtable,它能在节点加入离开时不会导致映射关系的重大变化“。
3.实现
一致性哈希的定义除了描述一个定义或者一种想法并没有给出任何实现方面的描述,所有细化的问题都留给开发者去思考。但一般的实现思路如下:
- 假定哈希的均匀Key分布在一个环上,比如所有节点都通过SHA-1或MD5进行哈希映射
- 所有的节点也都分布在同一环上(比如Server的IP地址经过SHA-1)
- 每个节点只负责一部分Key,当节点加入、退出时只影响加入退出的节点和其邻居节点或者其他节点只有少量的Key受影响
假如有n个节点,m个key,当节点增加时大约有O(m/n)的节点需要移动。但一般一致性哈希需要满足下面几个条件才对实际系统有意义:
- 平衡性(Balance):就是指哈希算法要均匀分布,不能有明显的映射规律,这对一般的哈希实现也是必须的
- 单调性(Monotonicity):就是指有新节点加入时,已经存在的映射关系不能发生变化
- 分散性(Spread):就是避免不同的内容映射到相同的位置和相同的内容映射到不同的位置
其实一致性哈希(哈希)有个明显的优点就是负载均衡,只要哈希函数设计得当,每个点就是对等的可以均匀地分布系统负载。
4.Memcached
看了上面的定义和实现可能还是比较迷茫,那就举个实际例子。
Memcached对大家应该不陌生,通过把Key映射到Memcached Server上,实现快速读取。我们可以动态对其节点增加,并未影响之前已经映射到内存的Key与memcached Server之间的关系,这就是因为使用了一致性哈希。
因为Memcached的哈希策略是在其客户端实现的,因此不同的客户端实现也有区别,以Spymemcache、Xmemcache为例,都是使用了KETAMA作为其实现。
KETAMA实现方式如下:
- 把Server的IP地址和端口进行MD5哈希,MD5的结果为一个160bit的数字,取其前32位作为一个Integer
- 把缓存对象的Key做MD5哈希,同样得到一个整数
- 可以设想,Server的整数会根据大小形成一个数字环,而Key的哈希则分布在这些数字上或中间
- 如果Server的哈希等于Key的哈希,则把Key存放在该Server上;否则,寻找第一个大于Key哈希的Server,用于存放Key
- 但有Server增加、删除时,只要变动周边的Server映射关系即可,不用全部重新哈希。之所以有这样优良的特性是因为,Server和Key采用了同样的值域
但是这样做的效果并不理想,原因是哈希虽然是随机的,但往往随机的不如人意,尤其是在Server节点数量上的情况下,Server不会均匀分布在哈希环上,这会导致哈希不均匀,某些Server会承担很多的Key,而另一些会很少,如图:
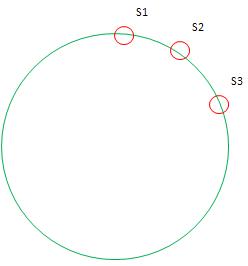
绝大多数Key会映射到Server1,因此KETAMA引入了虚节点的概念,就是假象每个Server映射到N个节点(根据测试N在100~200时较优化),但Key的哈希映射到这N个节点时实际都有该Server来托管。这样做的意义在于,使因为实际节点少而导致大片未被映射的区别有虚节点去填充,从而使实节点有了处理本不属于自己区间的Key。有虚节点后的环如下:
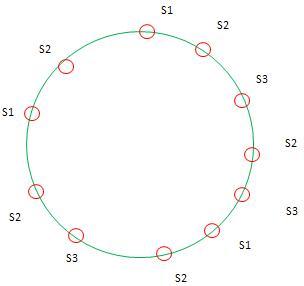
新增的同名节点即为虚节点。
还有最后一个问题,虚节点是如何产生的呢?也非常简单,就是在每个Server加个后缀,在做MD5哈希,取其32位。
具体请参考KETAMA的源码:http://www.chris.de/archives/288-libketama-a-consistent-hashing-algo-for-memcache-clients.html

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步