

如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP,准确率只有98.19%,然后不断改进,现在是99.78%,然而我看到排名第一是100%,心碎 = =,于是又改进了一版,现在把最好的结果记录一下,如果提升了再来更新。
手写数字集相信大家应该很熟悉了,这个程序相当于学一门新语言的“Hello World”,或者mapreduce的“WordCount”:)这里就不多做介绍了,简单给大家看一下:
1 # Author:Charlotte 2 # Plot mnist dataset 3 from keras.datasets import mnist 4 import matplotlib.pyplot as plt 5 # load the MNIST dataset 6 (X_train, y_train), (X_test, y_test) = mnist.load_data() 7 # plot 4 images as gray scale 8 plt.subplot(221) 9 plt.imshow(X_train[0], cmap=plt.get_cmap('PuBuGn_r')) 10 plt.subplot(222) 11 plt.imshow(X_train[1], cmap=plt.get_cmap('PuBuGn_r')) 12 plt.subplot(223) 13 plt.imshow(X_train[2], cmap=plt.get_cmap('PuBuGn_r')) 14 plt.subplot(224) 15 plt.imshow(X_train[3], cmap=plt.get_cmap('PuBuGn_r')) 16 # show the plot 17 plt.show()
图:

1.BaseLine版本
一开始我没有想过用CNN做,因为比较耗时,所以想看看直接用比较简单的算法看能不能得到很好的效果。之前用过机器学习算法跑过一遍,最好的效果是SVM,96.8%(默认参数,未调优),所以这次准备用神经网络做。BaseLine版本用的是MultiLayer Percepton(多层感知机)。这个网络结构比较简单,输入--->隐含--->输出。隐含层采用的rectifier linear unit,输出直接选取的softmax进行多分类。
网络结构:

代码:
1 # coding:utf-8 2 # Baseline MLP for MNIST dataset 3 import numpy 4 from keras.datasets import mnist 5 from keras.models import Sequential 6 from keras.layers import Dense 7 from keras.layers import Dropout 8 from keras.utils import np_utils 9 10 seed = 7 11 numpy.random.seed(seed) 12 #加载数据 13 (X_train, y_train), (X_test, y_test) = mnist.load_data() 14 15 num_pixels = X_train.shape[1] * X_train.shape[2] 16 X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32') 17 X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32') 18 19 X_train = X_train / 255 20 X_test = X_test / 255 21 22 # 对输出进行one hot编码 23 y_train = np_utils.to_categorical(y_train) 24 y_test = np_utils.to_categorical(y_test) 25 num_classes = y_test.shape[1] 26 27 # MLP模型 28 def baseline_model(): 29 model = Sequential() 30 model.add(Dense(num_pixels, input_dim=num_pixels, init='normal', activation='relu')) 31 model.add(Dense(num_classes, init='normal', activation='softmax')) 32 model.summary() 33 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 34 return model 35 36 # 建立模型 37 model = baseline_model() 38 39 # Fit 40 model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=200, verbose=2) 41 42 #Evaluation 43 scores = model.evaluate(X_test, y_test, verbose=0) 44 print("Baseline Error: %.2f%%" % (100-scores[1]*100))#输出错误率
结果:
1 Layer (type) Output Shape Param # Connected to 2 ==================================================================================================== 3 dense_1 (Dense) (None, 784) 615440 dense_input_1[0][0] 4 ____________________________________________________________________________________________________ 5 dense_2 (Dense) (None, 10) 7850 dense_1[0][0] 6 ==================================================================================================== 7 Total params: 623290 8 ____________________________________________________________________________________________________ 9 Train on 60000 samples, validate on 10000 samples 10 Epoch 1/10 11 3s - loss: 0.2791 - acc: 0.9203 - val_loss: 0.1420 - val_acc: 0.9579 12 Epoch 2/10 13 3s - loss: 0.1122 - acc: 0.9679 - val_loss: 0.0992 - val_acc: 0.9699 14 Epoch 3/10 15 3s - loss: 0.0724 - acc: 0.9790 - val_loss: 0.0784 - val_acc: 0.9745 16 Epoch 4/10 17 3s - loss: 0.0509 - acc: 0.9853 - val_loss: 0.0774 - val_acc: 0.9773 18 Epoch 5/10 19 3s - loss: 0.0366 - acc: 0.9898 - val_loss: 0.0626 - val_acc: 0.9794 20 Epoch 6/10 21 3s - loss: 0.0265 - acc: 0.9930 - val_loss: 0.0639 - val_acc: 0.9797 22 Epoch 7/10 23 3s - loss: 0.0185 - acc: 0.9956 - val_loss: 0.0611 - val_acc: 0.9811 24 Epoch 8/10 25 3s - loss: 0.0150 - acc: 0.9967 - val_loss: 0.0616 - val_acc: 0.9816 26 Epoch 9/10 27 4s - loss: 0.0107 - acc: 0.9980 - val_loss: 0.0604 - val_acc: 0.9821 28 Epoch 10/10 29 4s - loss: 0.0073 - acc: 0.9988 - val_loss: 0.0611 - val_acc: 0.9819 30 Baseline Error: 1.81%
可以看到结果还是不错的,正确率98.19%,错误率只有1.81%,而且只迭代十次效果也不错。这个时候我还是没想到去用CNN,而是想如果迭代100次,会不会效果好一点?于是我迭代了100次,结果如下:
Epoch 100/100
8s - loss: 4.6181e-07 - acc: 1.0000 - val_loss: 0.0982 - val_acc: 0.9854
Baseline Error: 1.46%
从结果中可以看出,迭代100次也只提高了0.35%,没有突破99%,所以就考虑用CNN来做。
2.简单的CNN网络
keras的CNN模块还是很全的,由于这里着重讲CNN的结果,对于CNN的基本知识就不展开讲了。
网络结构:
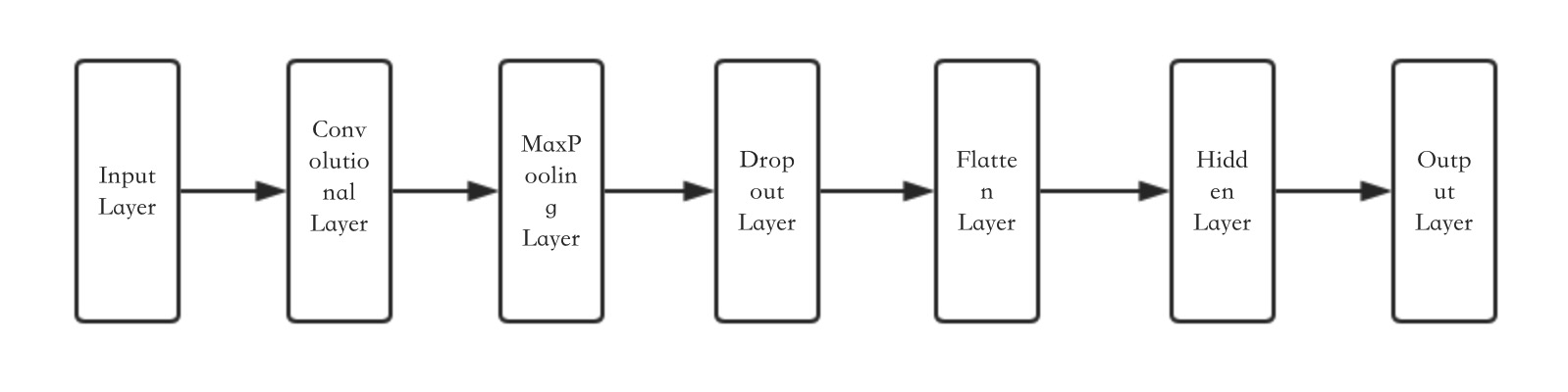
代码:
1 #coding: utf-8 2 #Simple CNN 3 import numpy 4 from keras.datasets import mnist 5 from keras.models import Sequential 6 from keras.layers import Dense 7 from keras.layers import Dropout 8 from keras.layers import Flatten 9 from keras.layers.convolutional import Convolution2D 10 from keras.layers.convolutional import MaxPooling2D 11 from keras.utils import np_utils 12 13 seed = 7 14 numpy.random.seed(seed) 15 16 #加载数据 17 (X_train, y_train), (X_test, y_test) = mnist.load_data() 18 # reshape to be [samples][channels][width][height] 19 X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32') 20 X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32') 21 22 # normalize inputs from 0-255 to 0-1 23 X_train = X_train / 255 24 X_test = X_test / 255 25 26 # one hot encode outputs 27 y_train = np_utils.to_categorical(y_train) 28 y_test = np_utils.to_categorical(y_test) 29 num_classes = y_test.shape[1] 30 31 # define a simple CNN model 32 def baseline_model(): 33 # create model 34 model = Sequential() 35 model.add(Convolution2D(32, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu')) 36 model.add(MaxPooling2D(pool_size=(2, 2))) 37 model.add(Dropout(0.2)) 38 model.add(Flatten()) 39 model.add(Dense(128, activation='relu')) 40 model.add(Dense(num_classes, activation='softmax')) 41 # Compile model 42 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 43 return model 44 45 # build the model 46 model = baseline_model() 47 48 # Fit the model 49 model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=128, verbose=2) 50 51 # Final evaluation of the model 52 scores = model.evaluate(X_test, y_test, verbose=0) 53 print("CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
1 ____________________________________________________________________________________________________ 2 Layer (type) Output Shape Param # Connected to 3 ==================================================================================================== 4 convolution2d_1 (Convolution2D) (None, 32, 24, 24) 832 convolution2d_input_1[0][0] 5 ____________________________________________________________________________________________________ 6 maxpooling2d_1 (MaxPooling2D) (None, 32, 12, 12) 0 convolution2d_1[0][0] 7 ____________________________________________________________________________________________________ 8 dropout_1 (Dropout) (None, 32, 12, 12) 0 maxpooling2d_1[0][0] 9 ____________________________________________________________________________________________________ 10 flatten_1 (Flatten) (None, 4608) 0 dropout_1[0][0] 11 ____________________________________________________________________________________________________ 12 dense_1 (Dense) (None, 128) 589952 flatten_1[0][0] 13 ____________________________________________________________________________________________________ 14 dense_2 (Dense) (None, 10) 1290 dense_1[0][0] 15 ==================================================================================================== 16 Total params: 592074 17 ____________________________________________________________________________________________________ 18 Train on 60000 samples, validate on 10000 samples 19 Epoch 1/10 20 32s - loss: 0.2412 - acc: 0.9318 - val_loss: 0.0754 - val_acc: 0.9766 21 Epoch 2/10 22 32s - loss: 0.0726 - acc: 0.9781 - val_loss: 0.0534 - val_acc: 0.9829 23 Epoch 3/10 24 32s - loss: 0.0497 - acc: 0.9852 - val_loss: 0.0391 - val_acc: 0.9858 25 Epoch 4/10 26 32s - loss: 0.0413 - acc: 0.9870 - val_loss: 0.0432 - val_acc: 0.9854 27 Epoch 5/10 28 34s - loss: 0.0323 - acc: 0.9897 - val_loss: 0.0375 - val_acc: 0.9869 29 Epoch 6/10 30 36s - loss: 0.0281 - acc: 0.9909 - val_loss: 0.0424 - val_acc: 0.9864 31 Epoch 7/10 32 36s - loss: 0.0223 - acc: 0.9930 - val_loss: 0.0328 - val_acc: 0.9893 33 Epoch 8/10 34 36s - loss: 0.0198 - acc: 0.9939 - val_loss: 0.0381 - val_acc: 0.9880 35 Epoch 9/10 36 36s - loss: 0.0156 - acc: 0.9954 - val_loss: 0.0347 - val_acc: 0.9884 37 Epoch 10/10 38 36s - loss: 0.0141 - acc: 0.9955 - val_loss: 0.0318 - val_acc: 0.9893 39 CNN Error: 1.07%
迭代的结果中,loss和acc为训练集的结果,val_loss和val_acc为验证机的结果。从结果上来看,效果不错,比100次迭代的MLP(1.46%)提升了0.39%,CNN的误差率为1.07%。这里的CNN的网络结构还是比较简单的,如果把CNN的结果再加几层,边复杂一代,结果是否还能提升?
3.Larger CNN
这一次我加了几层卷积层,代码:
1 # Larger CNN 2 import numpy 3 from keras.datasets import mnist 4 from keras.models import Sequential 5 from keras.layers import Dense 6 from keras.layers import Dropout 7 from keras.layers import Flatten 8 from keras.layers.convolutional import Convolution2D 9 from keras.layers.convolutional import MaxPooling2D 10 from keras.utils import np_utils 11 12 seed = 7 13 numpy.random.seed(seed) 14 # load data 15 (X_train, y_train), (X_test, y_test) = mnist.load_data() 16 # reshape to be [samples][pixels][width][height] 17 X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32') 18 X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32') 19 # normalize inputs from 0-255 to 0-1 20 X_train = X_train / 255 21 X_test = X_test / 255 22 # one hot encode outputs 23 y_train = np_utils.to_categorical(y_train) 24 y_test = np_utils.to_categorical(y_test) 25 num_classes = y_test.shape[1] 26 # define the larger model 27 def larger_model(): 28 # create model 29 model = Sequential() 30 model.add(Convolution2D(30, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu')) 31 model.add(MaxPooling2D(pool_size=(2, 2))) 32 model.add(Convolution2D(15, 3, 3, activation='relu')) 33 model.add(MaxPooling2D(pool_size=(2, 2))) 34 model.add(Dropout(0.2)) 35 model.add(Flatten()) 36 model.add(Dense(128, activation='relu')) 37 model.add(Dense(50, activation='relu')) 38 model.add(Dense(num_classes, activation='softmax')) 39 # Compile model 40 model.summary() 41 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 42 return model 43 # build the model 44 model = larger_model() 45 # Fit the model 46 model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=69, batch_size=200, verbose=2) 47 # Final evaluation of the model 48 scores = model.evaluate(X_test, y_test, verbose=0) 49 print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
___________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ==================================================================================================== convolution2d_1 (Convolution2D) (None, 30, 24, 24) 780 convolution2d_input_1[0][0] ____________________________________________________________________________________________________ maxpooling2d_1 (MaxPooling2D) (None, 30, 12, 12) 0 convolution2d_1[0][0] ____________________________________________________________________________________________________ convolution2d_2 (Convolution2D) (None, 15, 10, 10) 4065 maxpooling2d_1[0][0] ____________________________________________________________________________________________________ maxpooling2d_2 (MaxPooling2D) (None, 15, 5, 5) 0 convolution2d_2[0][0] ____________________________________________________________________________________________________ dropout_1 (Dropout) (None, 15, 5, 5) 0 maxpooling2d_2[0][0] ____________________________________________________________________________________________________ flatten_1 (Flatten) (None, 375) 0 dropout_1[0][0] ____________________________________________________________________________________________________ dense_1 (Dense) (None, 128) 48128 flatten_1[0][0] ____________________________________________________________________________________________________ dense_2 (Dense) (None, 50) 6450 dense_1[0][0] ____________________________________________________________________________________________________ dense_3 (Dense) (None, 10) 510 dense_2[0][0] ==================================================================================================== Total params: 59933 ____________________________________________________________________________________________________ Train on 60000 samples, validate on 10000 samples Epoch 1/10 34s - loss: 0.3789 - acc: 0.8796 - val_loss: 0.0811 - val_acc: 0.9742 Epoch 2/10 34s - loss: 0.0929 - acc: 0.9710 - val_loss: 0.0462 - val_acc: 0.9854 Epoch 3/10 35s - loss: 0.0684 - acc: 0.9786 - val_loss: 0.0376 - val_acc: 0.9869 Epoch 4/10 35s - loss: 0.0546 - acc: 0.9826 - val_loss: 0.0332 - val_acc: 0.9890 Epoch 5/10 35s - loss: 0.0467 - acc: 0.9856 - val_loss: 0.0289 - val_acc: 0.9897 Epoch 6/10 35s - loss: 0.0402 - acc: 0.9873 - val_loss: 0.0291 - val_acc: 0.9902 Epoch 7/10 34s - loss: 0.0369 - acc: 0.9880 - val_loss: 0.0233 - val_acc: 0.9924 Epoch 8/10 36s - loss: 0.0336 - acc: 0.9894 - val_loss: 0.0258 - val_acc: 0.9913 Epoch 9/10 39s - loss: 0.0317 - acc: 0.9899 - val_loss: 0.0219 - val_acc: 0.9926 Epoch 10/10 40s - loss: 0.0268 - acc: 0.9916 - val_loss: 0.0220 - val_acc: 0.9919 Large CNN Error: 0.81%
效果不错,现在的准确率是99.19%
4.最终版本
网络结构没变,只是在每一层后面加了dropout,结果居然有显著提升。一开始迭代500次,跑死我了,结果过拟合了,然后观察到69次的时候结果就已经很好了,就选择了迭代69次。
1 # Larger CNN for the MNIST Dataset 2 import numpy 3 from keras.datasets import mnist 4 from keras.models import Sequential 5 from keras.layers import Dense 6 from keras.layers import Dropout 7 from keras.layers import Flatten 8 from keras.layers.convolutional import Convolution2D 9 from keras.layers.convolutional import MaxPooling2D 10 from keras.utils import np_utils 11 import matplotlib.pyplot as plt 12 from keras.constraints import maxnorm 13 from keras.optimizers import SGD 14 # fix random seed for reproducibility 15 seed = 7 16 numpy.random.seed(seed) 17 # load data 18 (X_train, y_train), (X_test, y_test) = mnist.load_data() 19 # reshape to be [samples][pixels][width][height] 20 X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32') 21 X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32') 22 # normalize inputs from 0-255 to 0-1 23 X_train = X_train / 255 24 X_test = X_test / 255 25 # one hot encode outputs 26 y_train = np_utils.to_categorical(y_train) 27 y_test = np_utils.to_categorical(y_test) 28 num_classes = y_test.shape[1] 29 ###raw 30 # define the larger model 31 def larger_model(): 32 # create model 33 model = Sequential() 34 model.add(Convolution2D(30, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu')) 35 model.add(MaxPooling2D(pool_size=(2, 2))) 36 model.add(Dropout(0.4)) 37 model.add(Convolution2D(15, 3, 3, activation='relu')) 38 model.add(MaxPooling2D(pool_size=(2, 2))) 39 model.add(Dropout(0.4)) 40 model.add(Flatten()) 41 model.add(Dense(128, activation='relu')) 42 model.add(Dropout(0.4)) 43 model.add(Dense(50, activation='relu')) 44 model.add(Dropout(0.4)) 45 model.add(Dense(num_classes, activation='softmax')) 46 # Compile model 47 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 48 return model 49 50 # build the model 51 model = larger_model() 52 # Fit the model 53 model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=200, batch_size=200, verbose=2) 54 # Final evaluation of the model 55 scores = model.evaluate(X_test, y_test, verbose=0) 56 print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
1 ____________________________________________________________________________________________________ 2 Layer (type) Output Shape Param # Connected to 3 ==================================================================================================== 4 convolution2d_1 (Convolution2D) (None, 30, 24, 24) 780 convolution2d_input_1[0][0] 5 ____________________________________________________________________________________________________ 6 maxpooling2d_1 (MaxPooling2D) (None, 30, 12, 12) 0 convolution2d_1[0][0] 7 ____________________________________________________________________________________________________ 8 convolution2d_2 (Convolution2D) (None, 15, 10, 10) 4065 maxpooling2d_1[0][0] 9 ____________________________________________________________________________________________________ 10 maxpooling2d_2 (MaxPooling2D) (None, 15, 5, 5) 0 convolution2d_2[0][0] 11 ____________________________________________________________________________________________________ 12 dropout_1 (Dropout) (None, 15, 5, 5) 0 maxpooling2d_2[0][0] 13 ____________________________________________________________________________________________________ 14 flatten_1 (Flatten) (None, 375) 0 dropout_1[0][0] 15 ____________________________________________________________________________________________________ 16 dense_1 (Dense) (None, 128) 48128 flatten_1[0][0] 17 ____________________________________________________________________________________________________ 18 dense_2 (Dense) (None, 50) 6450 dense_1[0][0] 19 ____________________________________________________________________________________________________ 20 dense_3 (Dense) (None, 10) 510 dense_2[0][0] 21 ==================================================================================================== 22 Total params: 59933 23 ____________________________________________________________________________________________________ 24 Train on 60000 samples, validate on 10000 samples 25 Epoch 1/69 26 34s - loss: 0.4248 - acc: 0.8619 - val_loss: 0.0832 - val_acc: 0.9746 27 Epoch 2/69 28 35s - loss: 0.1147 - acc: 0.9638 - val_loss: 0.0518 - val_acc: 0.9831 29 Epoch 3/69 30 35s - loss: 0.0887 - acc: 0.9719 - val_loss: 0.0452 - val_acc: 0.9855 31 、、、 32 Epoch 66/69 33 38s - loss: 0.0134 - acc: 0.9955 - val_loss: 0.0211 - val_acc: 0.9943 34 Epoch 67/69 35 38s - loss: 0.0114 - acc: 0.9960 - val_loss: 0.0171 - val_acc: 0.9950 36 Epoch 68/69 37 38s - loss: 0.0116 - acc: 0.9959 - val_loss: 0.0192 - val_acc: 0.9956 38 Epoch 69/69 39 38s - loss: 0.0132 - acc: 0.9969 - val_loss: 0.0188 - val_acc: 0.9978 40 Large CNN Error: 0.22% 41 42 real 41m47.350s 43 user 157m51.145s 44 sys 6m5.829s
这是目前的最好结果,99.78%,然而还有很多地方可以提升,下次准确率提高了再来更 。
总结:
1.CNN在图像识别上确实比传统的MLP有优势,比传统的机器学习算法也有优势(不过也有通过随机森林取的很好效果的)
2.加深网络结构,即多加几层卷积层有助于提升准确率,但是也能大大降低运行速度
3.适当加Dropout可以提高准确率
4.激活函数最好,算了,直接说就选relu吧,没有为啥,就因为relu能避免梯度消散这一点应该选它,训练速度快等其他优点下次专门总结一篇文章再说吧。
5.迭代次数不是越多越好,很可能会过拟合,自己可以做一个收敛曲线,keras里可以用history函数plot一下,看算法是否收敛,还是发散。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号