



BloomFilter学习
看大数据面试题,看到BloomFilter,找了篇文章学习一下:
http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
Bloom Filter算法如下:
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(1) 加入字符串过程
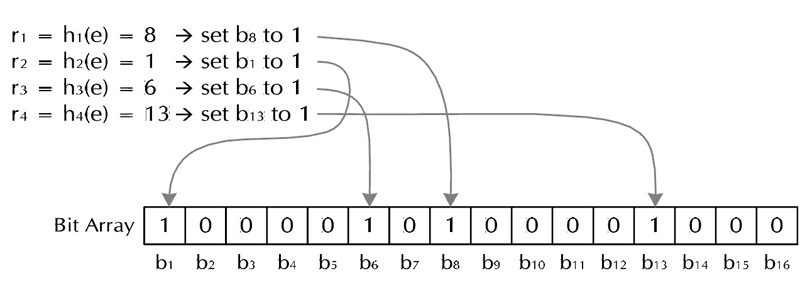
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
(3) 删除字符串过程
字符串加入了就被不能删除了,因为删除会影响到其他字符串。实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
三. Bloom Filter参数选择
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
(2)Bit数组大小选择
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献1。该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
原文中还给了个例子。使用了基本的乘法哈希。(更多哈希,参考:http://www.cnblogs.com/charlesblc/p/6130141.html)
cap和seed的用法,可以参考:
/* BitSet初始分配2^24个bit */ privatestaticfinalint DEFAULT_SIZE =1<<25; /* 不同哈希函数的种子,一般应取质数 */ privatestaticfinalint[] seeds =newint[] { 5, 7, 11, 13, 31, 37, 61 }; publicint hash(String value) { int result =0; int len = value.length(); for (int i =0; i < len; i++) { result = seed * result + value.charAt(i); } return (cap -1) & result; }

