python模块与包的导入
模块:
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀(模块名不能定义成中文)
为何要使用模块:
因为退出python解释器然后在进入python解释器,那么你之前定义的函数或者变量都将丢失,因此我们通常都将程序写到文件中便永久保存下来,需要时就通过python *.py方式去运行,此时的*.py被称为脚本script。
站在开发效率来讲,随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这是我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他模块中,实现了功能的重复利用
那么如何使用模块呢?
import


#test.py print('from the test.py') money=1000 def read1(): print('spam->read1->money',1000) def read2(): print('spam->read2 calling read') read1() def change(): global money money=0
import test #导入模块,导入就是在执行导入的文件 #导入模块后,就是通过import定义一个模块名,并且这个模块下的所以名字都因此在test名字的后面 print(test.money) #这样才能取到test模块下面的各种变量
请看下图
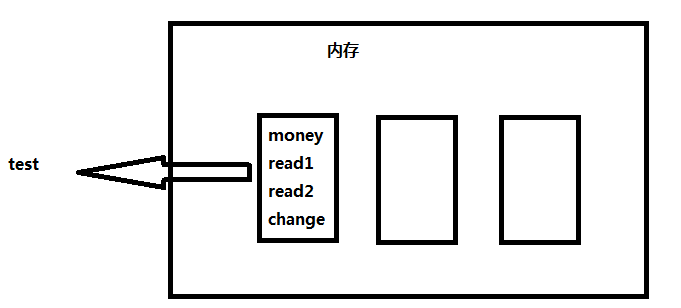
要想取出test下的money变量的值,需要通过test这个'门牌号'来取 就是print(test.money)
如果在当前文件中又定义了一个新的money变量。再次执行print(test.money)的结果还是原来的值。因为即使当前目录下定义了相同的变量,但是它们的内存地址并不一样。不管怎么写,只要是通过模块名去调用模块下面的代码,那么执行的结果一定是原来的东西
导入模块最倡导的方式就是'模块名.调用名'
import test #import只会在第一次导入时才会执行,后面的导入都是在引用之前创建好的名字。不会再把文件内容执行 import test import test import test #即使导入多次也是执行一次效果 #import过程就是要执行文件里面的代码,是文件就要有路径,所以import是一个找文件的过程。为什么能在当前目录下导入直接导入模块,因为调用与被调用模块都在同一个目录下,所以直接就能找到,调用。并且impor导入多次t不能每次都找,那样速度会慢。
我们可以使用sys.module找到当前已经加载的模块,sys.module是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入
import test as te print(te.money) #为模块起别名 ,适用于那种模块名很长,或者以冲突的模块名 #起别名还有一个好处就是扩展性强 #比如说两个模块都可以处理相同的问题 那么可以把这两个定义成一个别名,在调用的时候会很方便 if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date('filename')
import os,sys,time,test #一行导入多个模块
from ... import ...
相对于import test来说,它会将源文件的名称空间'test'带入到当前名称空间中,使用时必须是test.名字的方式,而from语句相当于import,也会创建新的名称空间,但是将test中的名字直接导入到当前名称空间中,在当前名称空间中,使用名字可以直接调用
from test import read1,read2 #注意 调用名字标红并不是报错,只是系统不识别自己定义的模块 read1() read2()
PS:但是如果当前导入的模块里有跟当前名称空间相冲突的名字,那么下面的名字就会覆盖上面
这种方法就是不需要进行test.最为前缀去调用,但是它的执行仍然跟test.执行一样,仍然要回到之前的名称空间中去运行
强烈不建议用from ... import 方法
也可以支持起别名
也支持多行导入
from test import * #导入所有,不推荐 #但是在某些情况下还得使用,各自体会吧
如果我在模块中,将一个名字以下划线(_)开头,那么import将无法导入
#但是可以通过用下面方法还是可以执行的 from test import _money
__all__
__all__=['money','read1'] #如果使用了__all__参数那么后面要跟一个列表,然后里面以字符串的方式写入,代表着如果里面写入了一些名字,那么谁在通过import test from *调用,只会调用__all__里面的名字,read2将不会调用
将模块当做脚运行
在模块中,最下方输入print(__name__),然后倒入模块后,会执行模块的内容,并且输入模块名,这个模块名就是print(__name__)执行的
但是模块只能被导入么?答案是否定的,模块也能单独当一个脚本执行。如果单独执行那么print(__name__)的输出就是__main__

所以通过__name__可以标识一种状态,文件此刻被已一种什么样的方式去使用。如果是__main__那么就当做脚本去执行,如果是文件名本身那么就是被调用。
通过 if __name__ =='__main__' 来控制文件在不同的场景下有不同执行效果。
模块搜索路径
导入模块:首先会从内存中找內建模块;如果不存在,然后会去系统的环境变量里找;如果不在当前目录,那么需要将要导入模块的路径添加到sys.path中,使用sys.path.append('路径');
在Python中导入代码会在Python中__pycache__目录下产生一个文件如(test.cpython-33.pyc)这个里面的test就是被导入的模块,而这个文件就是为了提高模块的导入速度。
导入包
包:就是一个目录,在Python中,一个文件夹中有__init__.py的文件
无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
包A与包B下有相同的模块也不会冲突,如A.a与B.a这是来自两个命名空间
包结构
glance/ #Top-level package ├── __init__.py #Initialize the glance package ├── api #Subpackage for api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd #Subpackage for cmd │ ├── __init__.py │ └── manage.py └── db #Subpackage for db ├── __init__.py └── models.py
文件中代码
#文件内容 #policy.py def get(): print('from policy.py') #versions.py def create_resource(conf): print('from version.py: ',conf) #manage.py def main(): print('from manage.py') #models.py def register_models(engine): print('from models.py: ',engine)
注意事项
1.关于包相关的导入语句也分为import和from...import...两种,但是无论哪种,无论什么位置,在导入时都必须遵循一个原则:凡事在导入时带点的,点的左边必须是一个包,否则非法。可以带有一连串的点,如item.subitem,subsubitem.但是都必须遵循这个原则
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数类(他们都可以用点的方式调用自己的属性)
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name,那么必须使用后者
import sys
import glance.api.policy as g1 print(sys.path) g1.get()
from...import...
需要注意的是from...import导入的模块,import后面必须是导一个具体的目标,错误语法(from a import b.c)正确语法(from a.b.c import d)
import后面不需要写点,后面不需要再进行找包的过程,找包的过程都是在from a.b.c 来完成的
from glance.api.policy import get get()
#或者
from glance.api import policy
policy.get()
导入包时做了什么事?
导入文件的时候,会执行文件,那么导入包呢? 在每个包中都会有一个__init__文件,那么在导入的时候会首先执行init文件,然后会在当前位置产生一个名字,这个名字来引用一个名称空间。
#如果直接导入glance包并且调用glance.api.policy下面的get方法需要怎么做? import glance glance.get()
如果如上述方法肯定会报错。因为你已经知道导入包就是执行包下面的__init__文件,那么可以用glacne下__init__文件来导入glance下的包,在通过其他文件来导入glance这个大包。
#在__init__中导入这个policy包, from glance.api.policy import get #然后再导入文件中导入glance包。 import glance glance.get() #那么只要一调用glance包就会执行__init__,而__init__就会执行from glance.api.policy import get 得到get功能。那么就可以直接用glance.get调用了
注意,在__init__中导入的包不是随便写的,导包就是一个找包的过程,还记得之前说的找包首先按照内存找,然后在sys.path中找,最后如果找不到需要将路径添加到sys.path中,所有在__init__中导入包要有一个参照物,那么这个参照物就sys.path中的路径。
因为上面的glance包与导入包文件都是在同级目录,如果在不同级目录的话,比如(a/glance)那么在导入就会报错,因为在内存中和sys.path中并没有这个路径,所以需要将a这个路径添加到sys.path中
import sys sys.path.append(r'C:\Users\Administrator\PycharmProjects\untitled\模块\a') import glance
这样在导入就可以了
绝对导入与相对导入
在开发一个包的时候不需要考虑别人如何调用
绝对导入:
特别需要注意的是:可以用import导入内置或者第三方模块,但是要绝对避免使用import来导入自定义包的子模块,应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
导入系统模块
hashlib模块
hashlib提供了常见的摘要算法如,MD5,SHA1等
这里先阐述一个加密与摘要的区别:
首先MD5并不是一个加密算法,而是一个摘要算法。加密算法是双向的,能加密,必然能通过加密后的值进行逆推。而摘要算法属于单向的,通过算法得出的值无法进行逆推。摘要算法又称为哈希算法,散列算法。它通过一个函数,把任意长度的数据转换成定长的数据串
摘要算法的作用在于防篡改。
例如,网上有一篇博客,内如是(hello world,jack),并且它的摘要算法值是"291250459873666ed73be15305ac5c17" 如果在下载的时候有人将博客的内容篡改了,那么再次校验的值是与之前的值是不同的
hashlib提供的函数还是比较简单的
导入hashlib模块
import hashlib
obj=hashlib.md5()
#创建一个对象
#对字符进行加密操作
obj.update('hello'.encode('utf-8'))
#执行后没有任何输出
#查看摘要值,这个结果是一个32位的二进制值
print(obj.hexdigest())
#16进制值
print(obj.digest())
如果一个字符串很长的话 可以进行拆分加密 加密后的结果与之前是一样的
import hashlib
obj=hashlib.md5()
# obj.update("hello".encode("utf-8"))
# obj.update("world".encode("utf-8"))
# fc5e038d38a57032085441e7fe7010b0
# b'\xfc^\x03\x8d8\xa5p2\x08TA\xe7\xfep\x10\xb0'
obj.update("helloworld".encode("utf-8"))
print(obj.hexdigest())
print(obj.digest())
除了md5还有其他的算法如,SHA算法
SHA算法里面包含了很多算法,常见的如SHA1,SHA256,SHA512
像md5,SHA1,SHA256,SHA512它们之间算法的加密等级是不一样的,越复杂的算法效率等级越慢。这个主要还是看需求来定。目前用的比较多的是SHA256
注意用法与md5一样
import hashlib
sha1= hashlib.sha1() #hashlib.sha256() hashlib.sha512()
sha1.update('hello'.encode('utf-8'))
print(sha1.hexdigest())
摘要算法的应用:
主要用于登录注册是进行加密。数据库中像这样的表,肯定是不可能明文进行存储。都是进行加密后的。
比如这样的
username | password
---------+---------------------------------
jack | e10adc3949ba59abbe56e057f20f883e
lily | 878ef96e86145580c38c87f0410ad153
tom | 99b1c2188db85afee403b1536010c2c9
但是会有这么一种人,他在注册的时候设置的密码过于简单比如’123456‘,’admin‘等等。这样就容易让他人撞库。那么如何预防这种事情发生呢?
我们可以在服务器端进行'加盐'操作
import hashlib
obj=hashlib.md5("salt".encode('utf-8'))
obj.update("hello".encode("utf-8"))
obj.update("world".encode("utf-8"))
# fc5e038d38a57032085441e7fe7010b0
# b'\xfc^\x03\x8d8\xa5p2\x08TA\xe7\xfep\x10\xb0'
print(obj.hexdigest())
print(obj.digest())
#这样在输出的结果就与之前的结果不同了
logging模块
在没有使用这个模块之前,我们想要将日志按照不同等级输入到文件中,通过文件操作with open 也可以,但是这样一来会很麻烦。来回的打开关闭文件。接下来学的这个模块就会大大的方便我们对日志的操作
首先导入这个名叫logging的模块
import logging
大家都知道日志中有不同的等级,比如debug info error等。所以在这个模块中也有不同的6种等级
logging.debug("debug")
logging.info("debug")
logging.warning("debug")
logging.error("debug")
logging.caitical("debug")
#执行,查看结果
ERROR:root:debug
CRITICAL:root:debug
WARNING:root:debug
只输出了三行,在logging模块中,默认的输出等级是warning,只有等于或高于warning才会输出。他们之间的等级关系是CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
有的人可能会说,这样的输出格式看着不太习惯或者明显,可否自己定义格式。没问题,可以通过一个函数来设定,"basicConfig"
logging.basicConfig(level=logging.DEBUG,
format="%(asctime)s %(lineno)d %(message)s",
datefmt='%a, %d %b %Y %H:%M:%S',
filename='test.log',
filemode='w')
logging.debug("debug")
logging.info("debug")
logging.error("debug")
logging.critical("debug")
logging.warning("debug")
首先咱们来看,level是设定输出等级,默认是warning,我们修改为debug。
format参数就是修改打印样式,后面的格式都是固定的,通过的是%()s或者%()d来设定。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
前面的asctime输出的时间精确到毫秒,看着很麻烦,所以我们可以通过datefmt关键字来进行时间格式化操作
filename是文件存放路径。
filemode对文件的操作。默认是是追加的形式,因为日志么,都是通过append的格式写入进文件,如果不想写入也可以通过filemode=w 关键字进行覆盖更改
上面的输出可以满足了我们一般的需求了,但是我要想一边在屏幕输出,一边保存到文件中,怎么做呢。基于上面的basicConfig只能二选一。所以出现了下面这个函数
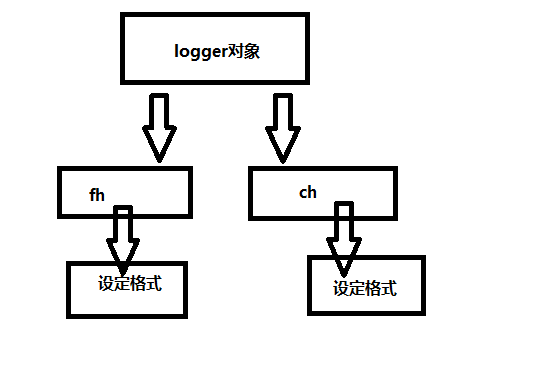
logger对象
import logging
首先定义一个logger对象
logger = logging.getLogger()
定义两个输出终端
fh = logging.FileHandler('test.log')
# 创建一个handler,用于写入日志文件,给一个路径
ch = logging.StreamHandler()
# 再创建一个handler,用于输出到控制台,不需要路径
#叫什么都无所谓
#流文件,是要输出到终端,还是要输出到文件中,只要将上面的ch或者fh添加到括号里就可以
logger.addHandler(ch)
logger.addHandler(fh)
两种模式全部输出。这样就可以输出,但是并没有样式。
logger.debug("debug")
logger.warning("debug")
logger.info("debug")
logger.error("debug")
logger.critical("debug")
格式化输出,设定日志等级
import logging
logger = logging.getLogger()
fh = logging.FileHandler('test.log')
ch = logging.StreamHandler()
设置formatter对象
formatter=logging.Formatter("%(asctiem)s---%(lineno)d---%(message)s")
formatter2=logging.Formatter("%(asctiem)s---%(message)s")
将设置后的样式添加进去
fh.setFormatter(formtter)
ch.setFormatter(formtter2)
logger.addHandler(ch)
logger.addHandler(fh)
现在的输出就是具有格式的输出。
最后设定输出等级
调整logger
logger.setLevel('DEBUG')
logger.debug("debug")
logger.warning("debug")
logger.info("debug")
logger.error("debug")
logger.critical("debug")
上面的过程用一个图来表示就是这样
re模块
re或正则表达式是一种小型的,高度专业化的编程语言
相对于正则来说,它实现的功能非常明确,就是对于在字符串的模糊匹配。首先它操作的对象一定是字符串
例: "hello world" 如何将hello world字符串中的world字符替换成jack。通过我们之前学过的字符串操作可以用replace "hello world".replace("world","jack")
但是可以发现我们替换的都是已知的字符串。如果我想替换以w开头以d结尾的字符呢?这种模糊替换怎么办。就需要用到我们的re模块了
re模块里面的方法不是特别多,非常简单
re.findall("","") #第一个引号里面写规则(匹配规则),第二个引号里面写要匹配的内容
#模糊匹配 >>> import re >>> re.findall("world","hello world") ['world'] >>> re.findall("w.*d","hello world") ['world'] >>>
元字符:. ^ $ * + ? { } [ ] | ( ) \
'.':匹配任意一个值(换行符无法匹配\n)
'^':匹配以什么开头
'$':匹配以什么结尾
'*':匹配任意多个字符(0到无穷)
>>> re.findall("a\d*b","hello ab")
['ab']
>>> re.findall("a\d*b","hello a123456b")
['a123456b']
'+':匹配任意多个字符(1到无穷)
>>> re.findall("a\d+b","hello ab")
[]
>>> re.findall("a\d+b","hello a123456b")
['a123456b']
'?':匹配0到1个字符
>>> re.findall("a\d?b","hello a1b")
['a1b']
>>> re.findall("a\d?b","hello ab")
['ab']
'{}':
>>> re.findall("\d{4}","hello ab1234")
['1234']
>>> re.findall("\d{4,}","hello ab1234")
['1234']
>>> re.findall("\d{4,}","hello ab1231231232313")
['1231231232313']
>>> re.findall("\d{1,4}","hel3lo a12.5b1231231232313")
['3', '12', '5', '1231', '2312', '3231', '3']
>>> re.findall("\d{1,}","hel3lo a12.5b1231231232313")
['3', '12', '5', '1231231232313']
'[]':字符集,在中括号中的任何元字符都失去其意义(^,\,-除外)
>>> re.findall("a[bc]d","abdsdjfjacd")
['abd', 'acd']
>>> re.findall("a[b*]","abba*")
['ab', 'a*']
>>> re.findall("[0-9]","abba1234567")
['1', '2', '3', '4', '5', '6', '7']
>>> re.findall("[0-9]*","abba1234567")
['', '', '', '', '1234567', '']
>>> re.findall("[0-9]+","abba1234567")
['1234567']
>>> re.findall("[^0-9]+","abba1234567")
['abba']
>>> re.findall("[\d]+","ab123ba1234567")
['123', '1234567']
'|': 或者意思
>>> re.findall("www.(?:baidu|google).com","www.baidu.com")
['www.baidu.com']
'()':分组
>>> re.findall(r"(?:a\d)+","fsda1a2a3a6")
['a1a2a3a6']
#这个分组的包含了一个优先级的问题。findall会先找分组里面的字符串然后进行匹配。匹配成功了。则返回分组里面的匹配值。所以要想输出匹配的字符串要加上'?:'来取消优先级
转移反斜杠
'\':将有意义的特殊字符转义成无意义。将无意义字符转换成有意义
>>> re.findall("[\w]+","ab123ba1234567")
['ab123ba1234567']
>>> re.findall("[\d]+","ab123ba1234567")
['123', '1234567']
>>> re.findall(".","ab123ba1234567")
['a', 'b', '1', '2', '3', 'b', 'a', '1', '2', '3', '4', '5', '6', '7']
>>> re.findall("I\b","I am FINE")
[]
>>> re.findall(r"I\b","I am FINE")
['I']
为什么加上r就可以了呢?请看下面的例子
>>> re.findall("c\d","abc\d")
[]
>>> re.findall("c\\d","abc\d")
[]
>>> re.findall("c\\\\d","abc\d")
['c\\d']
>>> re.findall(r"c\\d","abc\d")
['c\\d']
#从上面的例子中也可看出如果要匹配带有\的字符,如果只输入一个\\转义符那么输出并没有结果。只有输出4个转义符或者在前面加一个r。
#因为加两个\\是只满足了re模块的需求。但是我们是在python解释器中执行,所以如果要在python解释器中执行,那么就要在加两个。但是为什么要再加两个转义符?因为在python中'\'也是有特殊意义的。所以也要将它进行转义。
#加r后为什么两个\\反斜杠就可以呢?因为这个r称为原生字符串。目的告诉python解释器,这两个字符串是原生的。没有任何意义

search方法
#这个方法只会匹配第一个值。而且得到的结果不会直接输入到列表中。而是得到一个对象通过group()来读出结果
>>> re.search("\d+","he123llo a123456b")
<_sre.SRE_Match object; span=(2, 5), match='123'>
>>> re.search("\d+","he123llo a123456b").group()
'123'
match方法
#跟search方法一样,都是拿到一个结果。与search不一样的是必须在字符串开头位置进行匹配
>>> re.match(r"\d","fsdf123ab456")
>>> re.match(r"\d","34fsdf123ab456")
<_sre.SRE_Match object; span=(0, 1), match='3'>
>>> re.match(r"\d+","34fsdf123ab456")
<_sre.SRE_Match object; span=(0, 2), match='34'>
#match只找第一个。找不到就返回空
常见转义符
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
其他方法:
#re.split()分割
>>> re.split("\d+","asdahd1231sdad123a")
['asdahd', 'sdad', 'a']
>>> re.split("[ab]","abcd")
['', '', 'cd']
#re.sub()替换
>>> re.sub("\d","*","l1h2c3")
'l*h*c*'
>>> re.sub("\d","*","l1h2c3",1)
'l*h2c3'
#后面的1代表替换几个。
>>> re.subn("\d","*","l1h2c3",2)
('l*h*c3', 2)
>>> re.subn("\d","*","l1h2c3")
('l*h*c*', 3)
#同理re.subn就是代表将替换的后的结果和要替换的个数组成一个元组的形式
#re.compile()编译
>>> obj=re.compile("\d+")
>>> obj.findall("asdasd1231")
['1231']
>>> obj.findall("asd234asdasd1231")
['234', '1231']
#就是将规则先定义好然后在进行调用。将一步分成两步来执行
#减少代码重复性。如果就调用一次的话,不推荐用
time模块
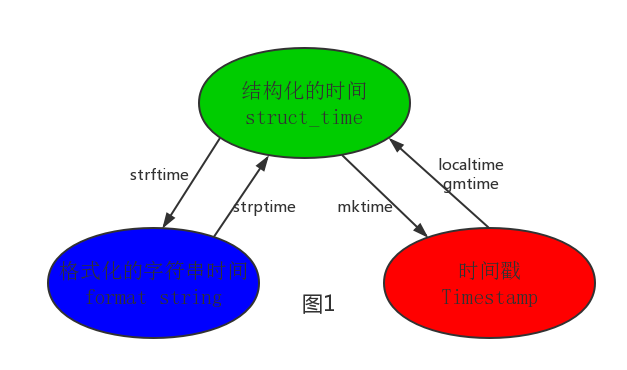
在python中,常用通用有这几种方式来表示时间:
时间戳(timestamp):通常来说,时间戳表示从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回类型是float类型
格式化的时间字符串(Format String)
结构化的时间(struct_time):struct_time元组共有九个元素(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
print (time.time())
#时间戳
print(time.strftime("%Y-%m-%d %X"))
#格式化时间
print(time.localtime())
#本地时间
print(time.gmtime())
#国际时间
x=(time.localtime())#将本地时间赋予变量x
print(x.tm_year) #通过x.的方式取出年月日
print(x.tm_mon)
print(x.tm_mday)
print(time.gmtime())#跟上面的用法一样。不一样的是小时。我们中国属于东八区
其中计算机认识的时间只能是时间戳的格式,而程序员可以处理为人类可以看懂的时间。格式化的时间字符串。结构化的时间,于是就有了下图的转换关系
图片来源:点击这里
import time
print(time.localtime(123456)) #使用time.localtime可以将时间戳转换为结构化时间
print(time.localtime(time.time()))#同上,获取当前时间戳,转换成本地结构化时间
print(time.gmtime(time.time()))#同上,转换成国际结构化时间
print(time.mktime(time.localtime()))#将本地结构化时间转换成时间戳
print(time.mktime(time.gmtime()))#将国际结构化时间转换成时间戳
print(time.strftime("%Y-%m-%d %X",time.localtime()))#将本地结构化时间转换成格式化时间
print(time.strftime("%Y-%m-%d %X",time.gmtime()))#将国际结构化时间转换成格式化时间
print(time.strptime('2017-04-11 00:00:00',"%Y-%m-%d %X"))#将格式化时间转换成结构化时间
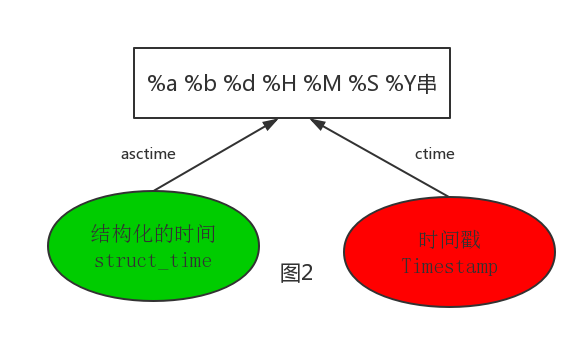
还有另外一种格式化时间请看图二
图片来源:点击这里
import time
print(time.asctime())#默认不加参数输出结果像linux系统上输出的结果,添加的参数为结构化时间time.localtime
print(time.ctime()) #同上,将时间戳的转换结果输出,添加参数必须为时间戳
time.sleep(10)
print('--->')
#sleep睡几秒
random模块
随机模块
import random
print(random.random())#大于0且小于1之间的小数,每次都是小数,不能指定范围
print(random.uniform(1, 3))#同上,可以指定范围
print(random.randint(1, 3))#[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1, 3))#[1,3)大于等于1且小于3之间的整数
print(random.choice([1, '23', [4, 5]]))#自己定义一个列表,随机取出列表里的元素1或者23或者[4,5]
print(random.sample([1, '23',3,4,5,6,[4, 5]], 3))#自定义列表,随机出去列表元素任意2个组合,逗号后面跟几就是每次随机取几个
item = [1, 3, 5, 7, 9]
random.shuffle(item) # 打乱item的顺序,相当于"洗牌"
print(item)
import random
def get_code():
res=''
for i in range(6):
num=random.randint(0,9)
num=str(num)
zimu=chr(random.randint(97,122)) #数字对应字母
res +=random.choice([num,zimu])
return res
X=get_code()
print(X)
OS模块
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
print(os.path.split('/a/b/c/d.txt'))#将路径一分为二
print(os.path.dirname(os.path.abspath(__file__)))#取出当前绝对路径
print(os.path.basename(os.path.abspath(__file__)))#取出当前文件名
dir1=(os.path.split(os.path.abspath(__file__))) #通过切割来取出路径或者文件
print(dir1[1])
import os
#在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。
print(os.path.normcase('C:/windows\\system32\\'))#在linux上没有任何效果
print(os.path.normpath('c://windows\\System32\\../Temp/'))#同上,'..'返回上一级,
路径处理
import os,sys
#方法一
BASE_DIR=(os.path.dirname(os.path.dirname((os.path.abspath(__file__)))))
方法二
BASE_DIR2= os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir,
os.pardir,
))
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
import sys,time
for i in range(50):
sys.stdout.write('%s\r ' %('#'*i))
sys.stdout.flush()
time.sleep(0.1)
shutil模块
高级的文件,文件夹,压缩包处理模块
import shutil
# shutil.copyfileobj(open('old','r'),open('new','w'))
##将文件内容拷贝到另一个文件中
# shutil.copyfile('old','old2')
##拷贝文件
# shutil.copymode('old','new')
# #拷贝权限,内容,组,用户均不变
# shutil.copystat('old','new')
## 拷贝状态信息,包括:mode bits,atime,mtime,flags
# shutil.copy('new','old2')
##拷贝文件和权限
# shutil.copy2('new','old1')
#拷贝文件和状态信息
# shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
#目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除,硬链接
# shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
##同上,软连接
# shutil.rmtree('/a/b/c')
# #递归删除目录或文件
# shutil.move('/a/b/c','/d/c/b')
#递归去移动文件,类似于mv
import shutil # ret=shutil.make_archive('old','gztar',root_dir='/data') #压缩并指定目录,默认为当前目录 import zipfile # z = zipfile.ZipFile('test.zip', 'w') # z.write('old') # z.write('new') # z.close() # 压缩 # z = zipfile.ZipFile('test.zip','r') # z.extractall(path='.') # z.close() #解压
import tarfile # t=tarfile.open('test.tar','w') # t.add('new',arcname='new.bak') # t.add('old',arcname='old.bak') # t.close() # # 压缩 # t=tarfile.open('test.tar','r') # t.extractall('.') # t.close() # #解压
json与pickle模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x="[null,true,false,1]"
print(eval(x)) #报错,无法解析null类型,而json就可以
print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要有序列化
1:持久保存状态
要知道一个程序或者软件的执行,就是在处理一系列状态的变化,在编程语言中,‘状态’会以各种各样有结构的的数据类型的形式被保存在内存中
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到其他机器上,如果收发的双方约定好使用一种序列化的格式,那么便打破了平台/语言差异带来的限制,实现了跨平台数据交互
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何使用json和pickle:
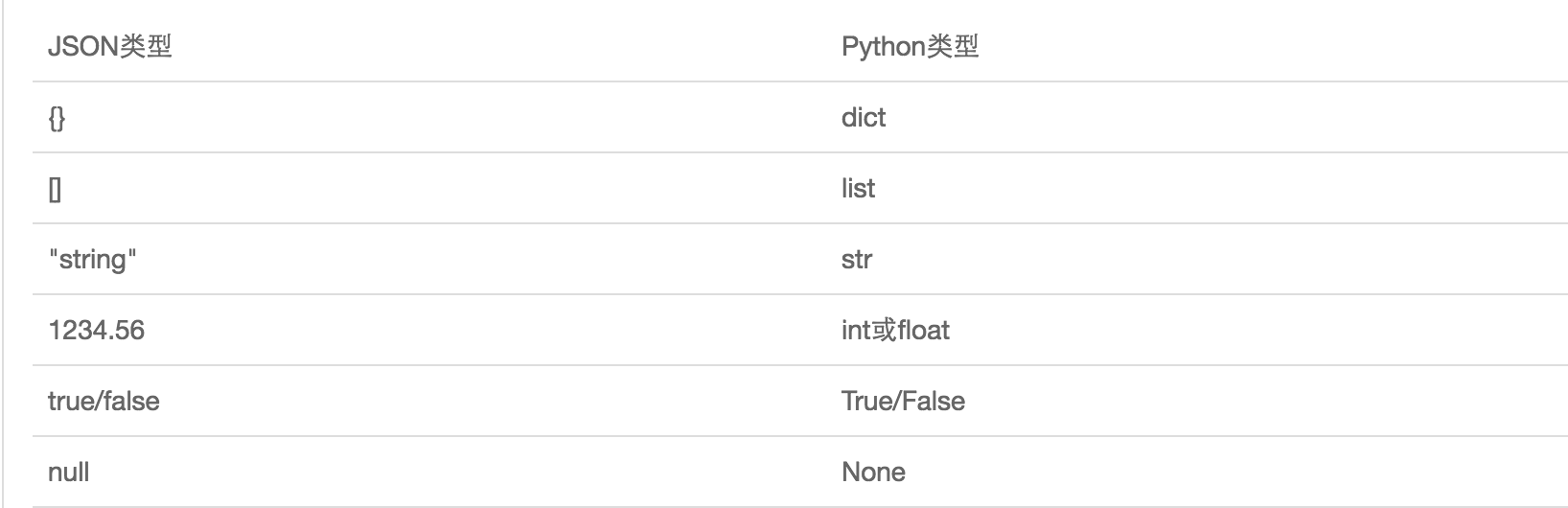

图片来源:点击这里
import json
dic={'name':'jack','age':'18','sex':'man'}
# print(type(dic)) #没序列化之前是字典格式
#
# j=json.dumps(dic)
# print(type(j)) #序列化后就是字符串格式
# f=open('dict.txt','w')
# f.write(j)
# f.close() #将序列化文件存放到文件中
# f=open('dict.txt','r')
# date=json.loads(f.read())
# print(type(date)) #反序列化
json.dump(dic,open('db.json','w')) #第二种方法
date=json.load(open('db.json','r'))
print(date['hoppy'][0])
pickle方法

图片来源:点击这里
import pickle
dic={'name':'jack','age':'18','sex':'man','hoppy':['eat','drink','play']}
j=pickle.dumps(dic)
print(type(j)) #序列化后为bytes类型
with open('db.pickle','wb') as f:
f.write(j) #写入文件的时候也要用wb方式。
with open('db.pickle','rb') as F:
date_pk=F.read()
date=pickle.loads(date_pk)
print(date) #pickle反序列化
#第二种方法
import pickle
dic={'name':'jack','age':'18','sex':'man','hoppy':['eat','drink','play']}
pickle.dump(dic,open('db.pk','wb'))
#序列化
date=pickle.load(open('db.pk','rb'))
print(date)
#反序列化
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系
后续的一些其它重要模块会慢慢补上。
