模式识别课程笔记(一)
一、模式识别(pattern recognition)
人类在识别和分辨事物时,往往是在先验知识和以往对此类事物的多个具体实例观察基础上产生的整体性质和特征的认识。
其实,每一种外界事物都可以看作是一种模式,人们对外界事物的识别,很大部分是把事物进行分类来完成的。
中文中:模式==类
简单来说就是一种规律,识别主是对事物对象进行分门别类,模式识别可以看作对模式的区分和认识,是事物样本到类别的映射;
英文中:pattern则表示两层意思
一层代表事物的模板或原形,第二层则是表征事物特点的特征或性状组合。
在模式识别学科中,模式可以看做是对象的组成成分或影响因素间存在的规律性关系,或者是因素间存在的确定性或随机性规律的对象、过程或事件的集合。
因此,也有人把模式成为模式类,模式识别也被称作为模式分类(Pattern Classification)。
专业术语:
- 样本(sample),一个个体对象,注意与统计学中的不同,类似于统计学中的实例(instance);
- 样本集(sample set):若干样本的集合,统计学中的样本就是指样本集;
- 类或类别(class):具有相同模式的样本集,该样本集是全体样本的子集;
习惯性地,我们用w1,w2等来表示类别,两类问题中也会用{0,1}或{-1,1}; - 特征(feature):也称为属性,通常指样本的某些可以用数值去量化的特征,如果有多个特征,则可以组合成特征向量(feature vector)。样本的特征构成了样本特征空间,空间的维数就是特征的个数,每一个样本就是特征空间中的一个点。
- 已知样本(known sample):已经事先知道类别的样本;
- 未知样本(unknown sample):类别标签未知但特征已知的样本;
二、模式识别类型
1.监督模式识别
特点:要划分的类别是已知的,并且能够获得一定数量的类别已知的训练样本。
这种情况下的机器学习的过程称为监督学习(有导师学习)。
2.非监督模式识别
特点:事先并不知道要划分的类别有哪些,甚至可能连要划分类别的数目也不知道,并且没有任何已知样本可以用来训练。
这种情况下要根据提取到的样本特征将样本聚成几个类,属于同一类的样本从某个角度上看具有一定的相似性,而不同类之间的样本差异则较大。这种机器学习的过程称为非监督学习(无导师学习),也成为聚类。
需要注意的是,在很多非监督模式识别中,聚类的结果不是唯一的,因为“相似”是从某个角度看上去的相似,这里的角度就是前面提到的特征。根据样本特征向量中的不同特征去聚类,会得到不同的结果。
举个例子:假设提取到的4个样本y1,y2,y3,y4的特征向量分别为
x1=(red,rounded,hollow)
x2=(red,rectangular,hollow)
x3=(blue,rounded,solid)
x4=(blue,rectangular,hollow)
若按特征向量的第一个特征(颜色)去聚类时,y1,y2聚为一类,y3,y4聚为一类;若按第二个特征(形状)去聚类时,y1,y3聚为一类,y2,y4聚为一类;若按第三个特征(空心/实心)去聚类时,y1,y2,y4聚为一类,y3自成一类。
这很好的解释了聚类结果的非唯一性,这也是非监督模式识别与监督模式识别的一个重要差别。
| 监督学习 | 非监督学习 |
| 有导师 | 无导师 |
| 要划分的类别已知 | 事先不知要划分类别 |
| 训练中可知模型决策结果 | 不知是否有错 |
| 神经网络、决策树 | k-均值聚类法 |
3. 加强学习
不提供设计种类,基于导师提供试验反馈(如决策是否正确)
三、模式识别系统
一个模式识别系统的典型构成包括:预处理,特征选择与提取,分类或聚类,后处理四个主要部分。
例子:
假设有两种鱼:鲈鱼、鲑鱼
问题:在传送带上分类
步骤:
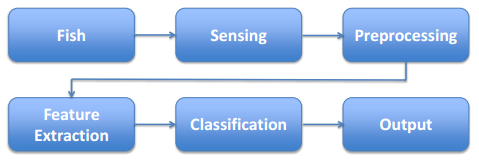
感知(sensing)
格式化能被机器感知的对象
可能导致的问题:
光线条件,鱼的位置,相机噪音等等
预处理(preprocessing)
改善数据
特征提取(feature extraction)
什么样的特征可以区分不同种类
分类(classification)
支持向量机、决策树等
模式识别系统
- 数据获取&感知
测量物理变量
基于样本质量,只有典型样本有用,时间和成本是限制条件 - 预处理
移除噪音、隔离背景 - 特征提取
- 模式学习/估计
学习特征与模式类别的映射关系 - 分类
- 输出处理
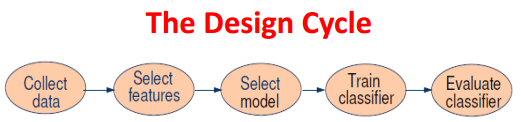
四、评价标准
训练精度
过拟合问题
测试精度
参考链接:
如果您认为本文对得起您所阅读所花的时间,欢迎点击右下角↘ 推荐。您的支持是我继续写作最大的动力,谢谢 (●'◡'●)
字节跳动职位长期内推,如有需求可发送简历至 lichaoran.cr@bytedance.com

