
MySQL5.6 GTID新特性实践
本文将简单介绍基于5.6 GTID的主从复制原理的搭建。并通过几个实验介绍相关故障的处理方式
本博客已经迁移至:
为了更好的体验,请通过此链接阅读:
http://cenalulu.github.io/mysql/mysql-5-6-gtid-basic/
GTID简介
什么是GTID
GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。
GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。下面是一个GTID的具体形式
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
更详细的介绍可以参见:官方文档
GTID的作用
那么GTID功能的目的是什么呢?具体归纳主要有以下两点:
- 根据GTID可以知道事务最初是在哪个实例上提交的
- GTID的存在方便了Replication的Failover
这里详细解释下第二点。我们可以看下在MySQL 5.6的GTID出现以前replication failover的操作过程。假设我们有一个如下图的环境
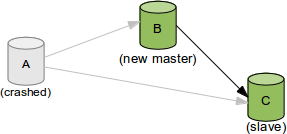
此时,Server A的服务器宕机,需要将业务切换到Server B上。同时,我们又需要将Server C的复制源改成Server B。复制源修改的命令语法很简单即CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn。而难点在于,由于同一个事务在每台机器上所在的binlog名字和位置都不一样,那么怎么找到Server C当前同步停止点,对应Server B的master_log_file和master_log_pos是什么的时候就成为了难题。这也就是为什么M-S复制集群需要使用MMM,MHA这样的额外管理工具的一个重要原因。
这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server C当前停止点的GTID就能唯一定位到Server B上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。 So easy不是么?
基于GTID的主从复制简介
搭建
搭建使用了mysql_sandbox脚本为基础,先创建了一个一主三从的基于位置复制的环境。然后通过配置修改,将整个架构专为基于GTID的复制。
根据MySQL官方文档给出的GTID搭建建议。需要一次对主从节点做配置修改,并重启服务。这样的操作,显然在production环境进行升级时是不可接受的。Facebook,Booking.com,Percona都对此通过patch做了优化,做到了更优雅的升级。具体的操作方式会在以后的博文当中介绍到。这里我们就按照官方文档,进行一次实验性的升级。
主要的升级步骤会有以下几步:
- 确保主从同步
- 在master上配置read_only,保证没有新数据写入
- 修改master上的
my.cnf,并重启服务 - 修改slave上的
my.cnf,并重启服务 - 在slave上执行
change master to并带上master_auto_position=1启用基于GTID的复制
由于是实验环境,read_only和服务重启并无大碍。只要按照官方的GTID搭建建议做就能顺利完成升级,这里就不赘述详细过程了。下面列举了一些在升级过程中容易遇到的错误。
常见错误
gtid_mode=ON,log_slave_updates,enforce_gtid_consistency这三个参数一定要同时在my.cnf中配置。否则在mysql.err中会出现如下的报错
2015-02-26 17:11:08 32147 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 or UPGRADE_STEP_2 requires --log-bin and --log-slave-updates
2015-02-26 17:13:53 32570 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 requires --enforce-gtid-consistency
change master to 后的warnings
在按照文档的操作change master to后,会发现有两个warnings。其实是两个安全性警告,不影响正常的同步(有兴趣的读者可以看下关于该warning的[具体介绍]({{ site.url }}/mysql/myall-abount-mysql-password/)。warning的具体内容如下:
slave1 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.03 sec)
slave1 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave1 [localhost] {msandbox} ((none)) > show warnings;
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1759 | Sending passwords in plain text without SSL/TLS is extremely insecure. |
| Note | 1760 | Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information. |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
实验一:如果slave所需要事务对应的GTID在master上已经被purge了
根据show global variables like '%gtid%'的命令结果我们可以看到,和GTID相关的变量中有一个gtid_purged。从字面意思以及 官方文档可以知道该变量中记录的是本机上已经执行过,但是已经被purge binary logs to命令清理的gtid_set。
本节中我们就要试验下,如果master上把某些slave还没有fetch到的gtid event purge后会有什么样的结果。
以下指令在master上执行
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+----------------------------------------+
| Variable_name | Value |
+---------------------------------+----------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+----------------------------------------+
7 rows in set (0.01 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test2 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.02 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test3 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000005 | 359 | | | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
+------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > purge binary logs to 'mysql-bin.000004';
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave2上重新做一次主从,以下命令在slave2上执行
slave2 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
......
Slave_IO_Running: No
Slave_SQL_Running: Yes
......
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 0
Relay_Log_Space: 151
......
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
......
Auto_Position: 1
1 row in set (0.00 sec)
实验二:忽略purged的部分,强行同步
那么实际生产应用当中,偶尔会遇到这样的情况:某个slave从备份恢复后(或者load data infile)后,DBA可以人为保证该slave数据和master一致;或者即使不一致,这些差异也不会导致今后的主从异常(例如:所有master上只有insert没有update)。这样的前提下,我们又想使slave通过replication从master进行数据复制。此时我们就需要跳过master已经被purge的部分,那么实际该如何操作呢?
我们还是以实验一的情况为例:
先确认master上已经purge的部分。从下面的命令结果可以知道master上已经缺失24024e52-bd95-11e4-9c6d-926853670d0b:1这一条事务的相关日志
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave上通过set global gtid_purged='xxxx'的方式,跳过已经purge的部分
slave2 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > set global gtid_purged = '24024e52-bd95-11e4-9c6d-926853670d0b:1';
Query OK, 0 rows affected (0.05 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
......
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 359
Relay_Log_File: mysql_sandbox21290-relay-bin.000004
Relay_Log_Pos: 569
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Exec_Master_Log_Pos: 359
Relay_Log_Space: 873
......
Master_Server_Id: 1
Master_UUID: 24024e52-bd95-11e4-9c6d-926853670d0b
Master_Info_File: /data/mysql/rsandbox_mysql-5_6_23/node2/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
......
Retrieved_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:2-3
Executed_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:1-3
Auto_Position: 1
1 row in set (0.00 sec)
可以看到此时slave已经可以正常同步,并补齐了24024e52-bd95-11e4-9c6d-926853670d0b:2-3范围的binlog日志。

