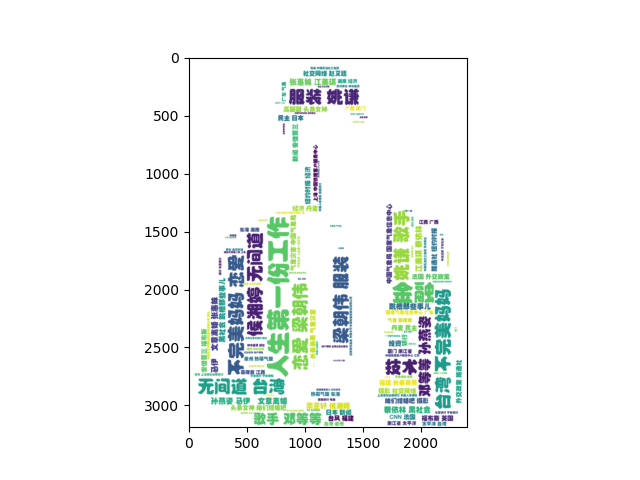
爬虫之使用requests爬取某条标签并生成词云
一、爬虫前准备
1.工具:pychram(python3.7)
2.库:random,requests,fake-useragent,json,re,bs4,matplotlib,worldcloud,numpy,PIL,jieba
random:生成随机数
requests:发送请求获取网页信息
fake-useragent:生成代理服务器
json:数据转换
re:用于正则匹配
bs4:数据过滤
matpotlib:图像处理
worldcloud:生成词云
numpy:图像处理
PIL:图像处理
jieba:对中文进行分词(本次未用到)
3.爬虫流程
使用代码模拟浏览器发送请求-->浏览器返回信息(html/json)-->提取有用的信息-->进行储存
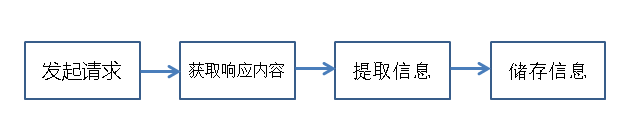
1)发起请求
使用代码向目标站点发送请求,即发送一个Request
请求应包含:请求头、请求体等
2)获取响应内容
发送请求成功后,会获得站点返回的信息(Response)
3)提取信息
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery,xpath等
解析json数据:json模块
4)储存信息
以文件存储
存入数据库
二、开始爬虫
1.防止ip被封
为了防止多次访问某站点导致IP被封,对IP进行伪装。
找一些提供免费IP的网站爬取IP数据存储到本地文件中,将爬虫进行到底。


1 # __Author__ :"Chen Yang" 2 # __Time__: 2019/8/22 20:56 3 4 import requests 5 from fake_useragent import UserAgent 6 import re 7 8 9 def create_pool(ur): 10 url = ur 11 12 ua = UserAgent() 13 # fake_useragent 提供的随机生成代理服务器 14 headers = {"User-Agent": ua.random} 15 16 r = requests.get(url, headers=headers) 17 # 正则匹配所有IP 18 comment = re.findall('<td data-title="IP">(.*)</td>', r.text) 19 # 正则匹配所有端口 20 port = re.findall('<td data-title="PORT">(.*)</td>', r.text) 21 22 print(r.text) 23 print(comment) 24 print(port) 25 # 将IP和端口对应 存入文件 26 with open('ip-port.text', 'a', encoding='utf-8') as f: 27 for i in range(len(comment) - 1): 28 f.write(comment[i] + ":" + port[i]) 29 f.write('\n') 30 31 32 if __name__ == "__main__": 33 # 爬取该网页前7页IP 34 for i in range(6): 35 ur = 'http://www.qydaili.com/free/?action=china&page=' + str(i) 36 create_pool(ur)
2.IP爬取成功后正式开始爬取某条
xhr:XMLHttpRequest 对象提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。
某条文章是动态随机推荐的,每次进入头条页面的文章都不同。
在多次分析后找到realtime_news/的xhr




访问open_url,爬取标签
至此,基本可以确定realtime_news的xhr就是要爬的文件。
思路:爬取realtime_news的xhr的文件-->获取其中open_url-->爬取标签-->生成词云
1 import random 2 import requests 3 from fake_useragent import UserAgent 4 import json 5 import re 6 from bs4 import BeautifulSoup 7 import matplotlib.pyplot as plt # 用于图像处理 8 from wordcloud import WordCloud# 用于生成词云 9 import numpy as np 10 from PIL import Image 11 12 # 词云形状文件 需要替换成你本地的图片 13 backgroud_Image = np.array(Image.open("man.jpg")) 14 # 词云字体 需要替换成你本地的字体 15 WC_FONT_PATH = '黄引齐招牌体.ttf' 16 17 18 def get_ip(): 19 f = open("ip-port.text", 'r') # 从IP-port中读取IP 20 ip_all = [] 21 for k in f: 22 line = f.readline() 23 ip_all.append(line[:-1]) # 去除/n 24 f.close() 25 # print(ip_all) 26 i = random.randint(0, len(ip_all)-1) 27 pr = ip_all[i] 28 print("ip地址为:{}".format(pr)) 29 return pr 30 31 32 def get_info(): 33 ''' 34 使用爬取的ip来进行ip代理 35 使用fake_useragent进行服务器代理,防止IP被封 36 ''' 37 url = 'https://www.toutiao.com/api/pc/realtime_news/' 38 39 ua = UserAgent() 40 agent = ua.random 41 print("代理为:{}".format(agent)) 42 header = {"User-Agent": agent} 43 44 ip = get_ip() 45 proxies = {'url': ip} 46 47 try: 48 # 获取首页信息 49 r = requests.get(url, headers=header, proxies=proxies) 50 global_json = json.loads(r.text) 51 print(global_json) 52 except: 53 print("请求头条主页失败") 54 55 # 获取首页信息动态推荐文章的地址 56 article = [] 57 for i in range(len(global_json['data'])): 58 article.append(global_json['data'][i]['open_url']) 59 # 头条得子文章页标号 会随机发生变化 60 #print(article) 61 62 # 取8篇文章得label 63 for i in range(7): 64 # 访问动态推荐文章地址 65 content = "http://toutiao.com" + article[i] 66 try: 67 respon = requests.get(content, headers=header, proxies=proxies) 68 # 输入返回对象的文本值 69 # print(respon.text) 70 except: 71 print("请求文章失败") 72 73 # 指定编码等于原始页面编码 74 respon.encoding = respon.apparent_encoding 75 # 获取想要地址对应的BeautifulSoup 76 html = BeautifulSoup(respon.text, 'lxml') 77 # 选择 第六个script标签 即数据所在标签 78 try: 79 src = html.select('script')[6].string 80 #print(src) 81 except: 82 print("获取数据失败!") 83 result = [] 84 try: 85 # 正则找到数据中标签字段 86 labels = re.findall('tags:(.*),', respon.text) 87 #print(type(labels)) 88 # strip()去空格 89 # 把字符串转为列表 90 result = labels[0].strip() 91 # print(type(result)) 92 # print(labels) 93 # eval() 将字符串列表 转为列表 94 result = eval(result) 95 # print(result) 96 except: 97 print("未获得labels") 98 with open("labels.json", 'a', encoding='utf-8') as f: 99 for i in range(len(result)-1): 100 f.write(result[i]['name']) 101 f.write(' ') 102 103 104 def cut_word(): 105 ''' 106 生成词云 107 :return: 108 ''' 109 with open("labels.json", 'r', encoding='utf-8') as f: 110 label =f.read() 111 wl = "".join(label) 112 print(wl) 113 return wl 114 115 116 def create_word_cloud(): 117 ''' 118 生成词云 119 :return: 120 ''' 121 # 设置词云形状图片 122 #wc_mask = np.array(WC_MASK_IMG) 123 # 设置词云配置 字体 背景 大小等 124 wc = WordCloud(background_color='white', max_words=2000, mask=backgroud_Image, scale=4, 125 max_font_size=50, random_state=42, font_path=WC_FONT_PATH) 126 # 生成词云 127 wc.generate(cut_word()) 128 129 # 在只设置mask情况下, 你会得到一个图片形得词云 130 plt.imshow(wc, interpolation='bilinear') 131 #plt.axis("off") 132 plt.figure() 133 plt.show() 134 135 136 if __name__ == '__main__': 137 get_info() 138 create_word_cloud()