爬虫进度
队友柯奇豪负责WordCount、测试部分、附加题
高裕翔负责了网络爬虫的实现
-
**代码规范: **
java
-
壹- psp
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 200 |
| Development | 开发 | 120 | 120 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 160 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 30 | 40 |
| · Code Review | · 代码复审 | 40 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 40 | 60 |
| · Test Repor | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 2 | 1 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 892 | 1001 |
-
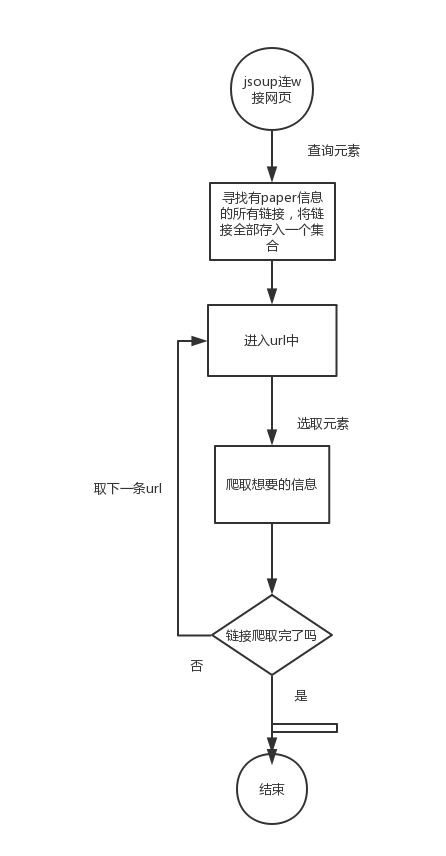
贰-设计思路
1. main主体 , 将url传入util中获取html文件,util将文件传给parse(jsoup+httpclient)解析,封装在集合中,数据最后返回main,再导入sql中 (ps太过麻而烦被放弃了,不过之前上传过);
2.只用jsoup解析,不采用数据库方法,直接打印到result文件中;
-
叁- 主要代码&解释
1. 连接主页,寻找到有每篇paer信息的所有链接作为一个elements
Document document = Jsoup.connect("http://openaccess.thecvf.com/CVPR2018.py").timeout(50000).maxBodySize(0).get(); /* 这里用connect(String url) 方法创建一个 Connection,解析html文件 */
Elements mainPage= document.select("dt.ptitle"); /* 寻找主页中的pititle元素 */
int t=mainPage.size();
System.out.println("一共有"+ t +"篇论文");/*这一部分只是想看看有多少篇论文,可以去掉*/
Elements urlLink=mainPage.select("a[href^=content_cvpr_2018/html/]");/*用select选择器,在之前寻找到的pititle元素下,寻找a标签中,href为content_cvpr_2018/html/的那些元素*/
int paperid= -1; /*ID,标记第几篇paper*/
PrintStream ps = new PrintStream("e:/results.txt"); /*建立一个输出流txt*/
System.setOut(ps); /*输出到ps中,既打印到results文件*/
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
2.循环爬取连接所有elements中的url,爬取论文信息
for(Element paper:urlLink) { /*循环爬取url列表*/
String URL = paper.attr("href"); /*寻找URLLINK元素下的超链接(即每篇论文信息的入口)*/
if(!URL.contains("https://")){
URL ="openaccess.thecvf.com/"+URL; /*加入http协议的开头,方便访问*/
}
Document doc = Jsoup.connect("http://"+URL).timeout(80000).maxBodySize(0).get();/*进入论文信息界面,设置超时好参数*/
Elements paperdatas=doc.select("#content");/*寻找conttent id*/
Elements title1=paperdatas.select("#papertitle");/*标题*/
Elements abs=paperdatas.select("#abstract");/*概述*/
Elements authors = paperdatas.select("#authors");/*作者*/
Elements opway = paperdatas.select("a[href]");/*其他格式*/
String author=authors.select("b").text();
String title = title1.text();
paperid=paperid+1;
String abst=abs.text();
String openway=opway.text(); /*将爬取的信息转为text,放入对应的变量中方便输出*/
-
肆 遇到的困难
-
1.代码编译过程中主类函数找不到(
未解决)
描述:编译时疯狂报错,找不到主类main
尝试方法:修改路径,改动大小写……
解决方法:最后发现多引用了重复的jar包,删除掉以后就恢复正常了,但是不久后又开始报错找不到主类,于是更换了平台,
eclipse,转IDEA
收获:IDEA好用多了……
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-
2.超时(半解决)
描述:有时候成功运行,不过有时候会报错说connect time out
尝试方法:设置time(只能减少超时出现的频率,网速太慢了还是会超时)
解决方法:设置time()参数,设置大一些(不过只能减少超时出现的频率,网速太慢了还是会超时)
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-
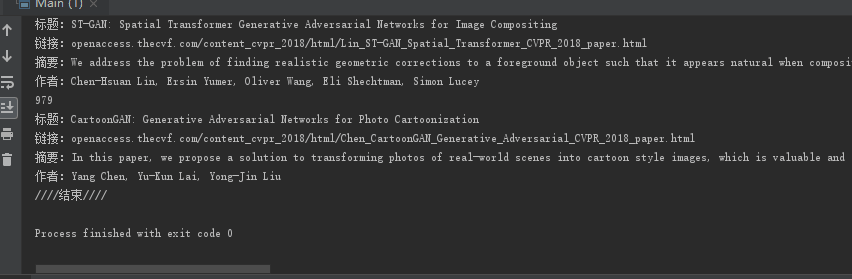
3.只能爬502篇……(
未解决)
问题描述:
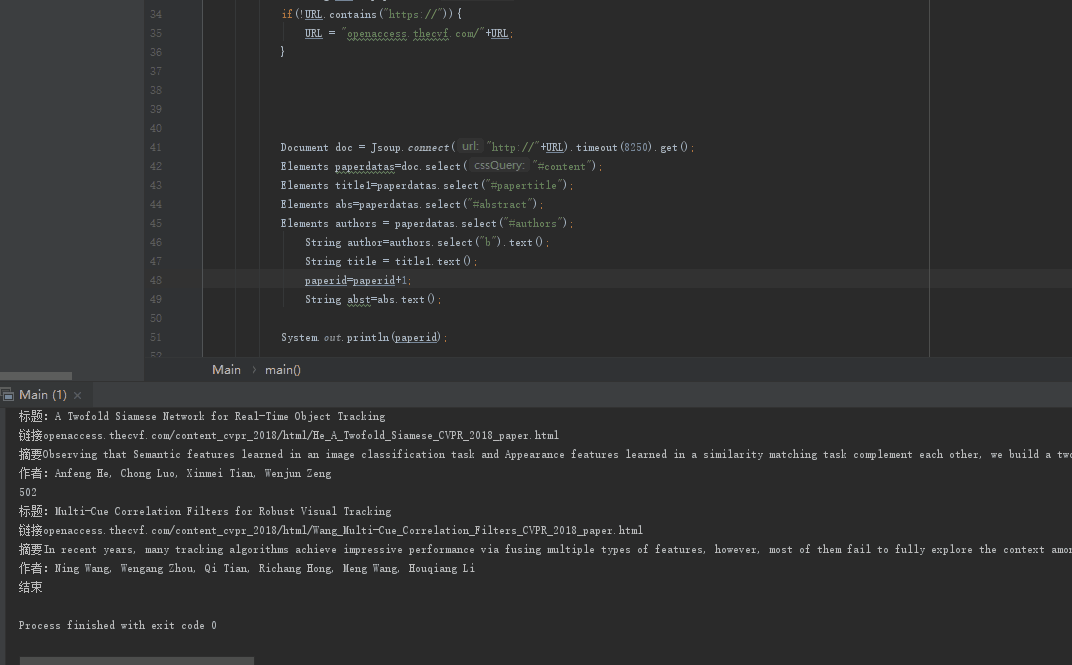
解决方法:设置maxbodysize就可以了,是jsoup的Api设置问题(不过我之前去找并没有找到这个参数),它默认设置了爬取大小,把函数置0就可以没限制了
收获:第一次遇到这种问题,也是涨姿势了……
参考博客链接
-
伍 单元测试
-
陆 github记录(部分截图)
-
柒 队友评价
编码水平和分析能力都很厉害,有耐心,懂得很多,查找东西的能力也很厉害
望洋兴叹,我只会喊666
-
捌 学习进度
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 2 | 2 | 拜读博客 |
| 2 | 255 | 255 | 12 | 14 | |
| 3 | 0 | 255 | 23 | 37 | 再读构建之法和数据结构,收获很大……尤其是第八章第九章那部分 |
| 4 | 540 | 795 | 20 | 57 | 第一次用java做爬虫…… |
