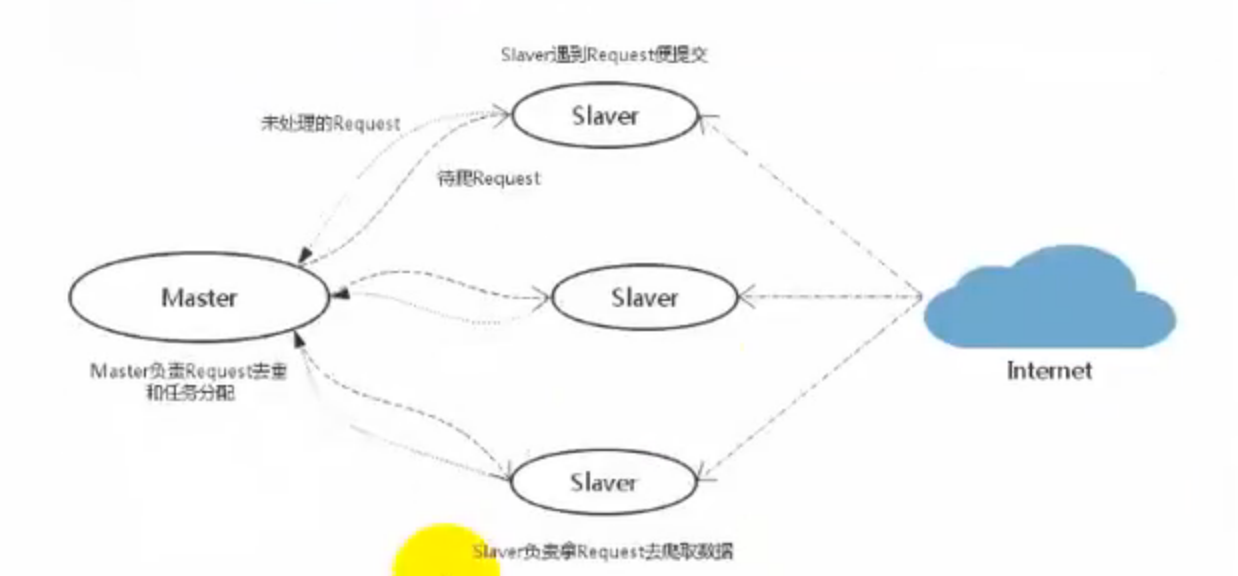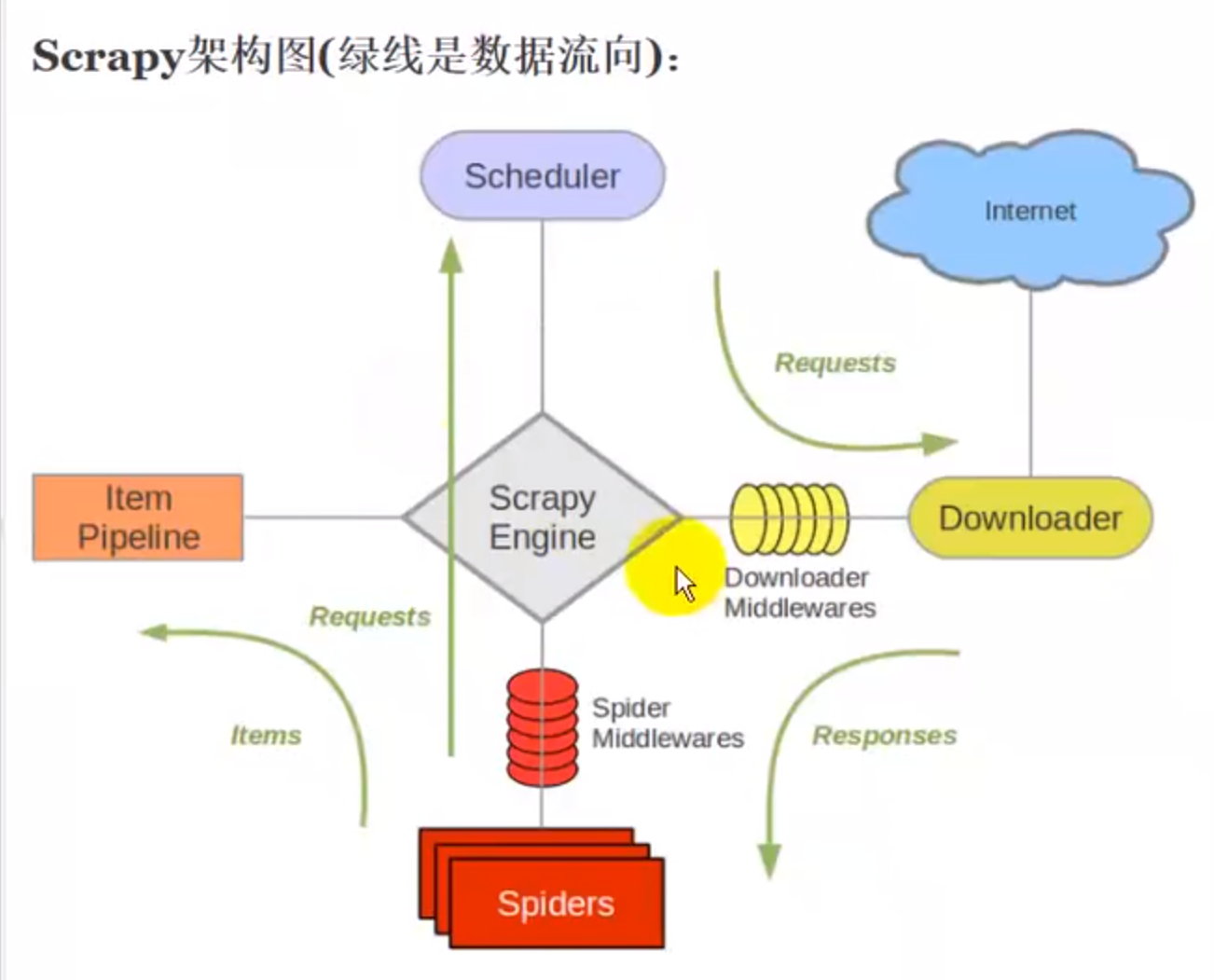
1.爬虫spiders将请求通过引擎传递给调度器scheduler
2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader
3.downloader从Internet的服务器端请求数据,下载下来
4.下载下来的响应体交还给我们自己写的spiders,对响应体做相应的处理
5.响应体处理后有两种情况,1):如果是数据,交给pipeline管道,处理数据 2):如果是请求,接着交给调度器放到请求队列中等待处理,然后交给下载器处理,如此循环,直到没有请求产生
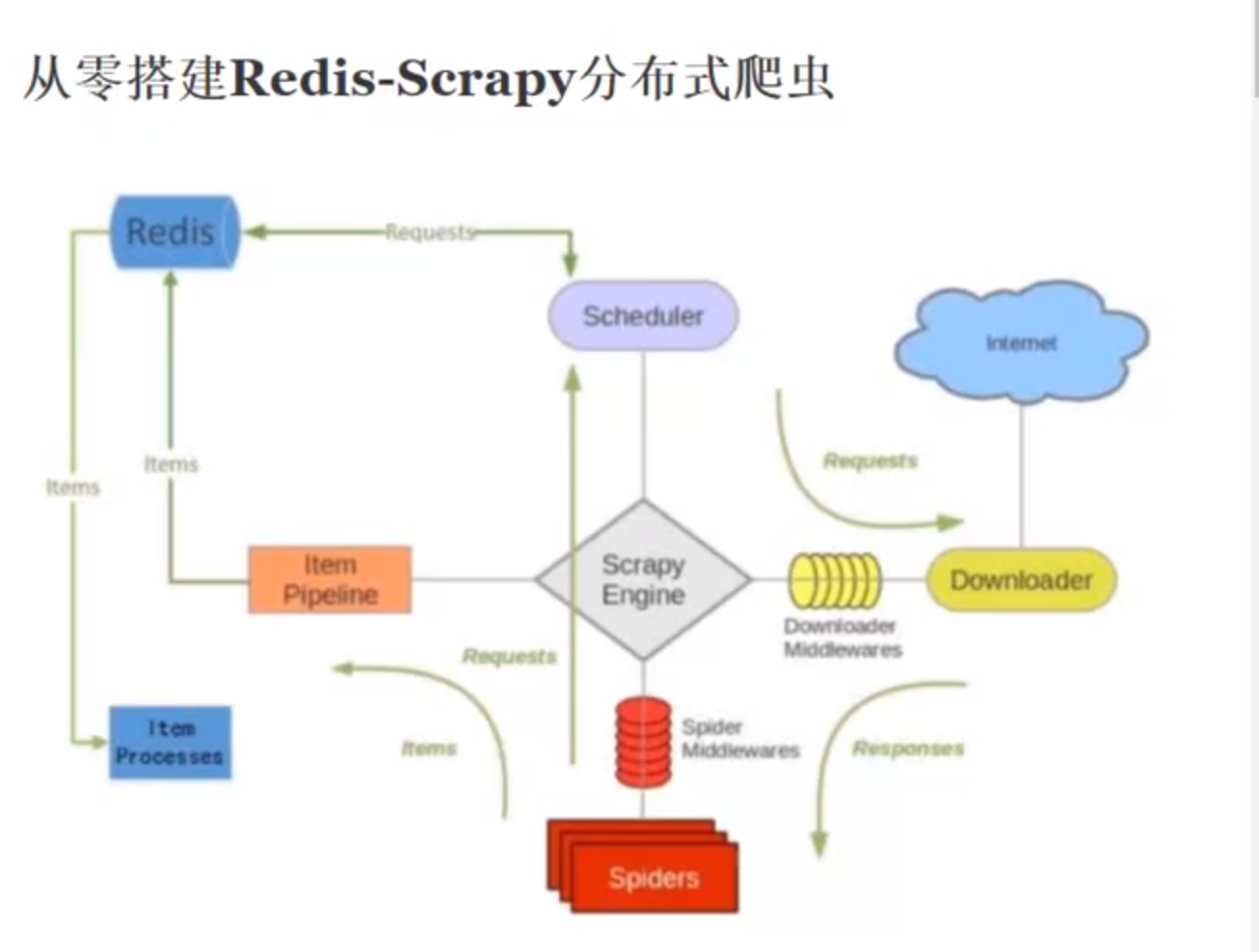
redis-scrapy是基于scrapy框架的一套组件
scrapy是一个通用的爬虫框架,不支持分布式操作,scrapy-redis是为了更方便的是scrapy进行分布式的爬取,而提供了一些以redis为基础的组件(仅有组件)
scrapy提供了四种组件(components),四种组件也就意味这四个模块都要做相应的修改:
- scheduler
- duplication filter
- item pipeline
- base spider
scrapy的去重是在内存中执行的,如果请求量非常大的时候,scrapy占用的内存会非常高,如果我们把这个去重的指纹队列放到redis数据库中的话就会很方便了
scrapy中的数据是交给pipeline来处理的,在scrapy-redis中,数据是直接存储到redis数据库中的,然后我们对数据进行处理持久化到mongodb中或者mysql中,因为redis也是基于内存的存储,不适合持久化数据
Scheduler:
scrapy改造了python本来的collection.deque(双向队列)形成了自己的scrapy queue,但是scrapy多个spider不能共享待爬取队列scrapy queue,即scrapy本身不支持爬取分布式,scrapy-redis的解决是把这个scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider从同一个数据库中读取。
scrapy中跟待爬队列直接相关的就是调度器scheduler,它把新的request进行入列操作,放到scrapy queue中,把要爬取的request取出,从scrapy queue中取出,它把待爬队列按照优先级建立了一种字典结构
{
优先级0:队列0
优先级1:队列1
优先级2:队列2
}
然后根据request中的优先级,来决定该入到哪个队列中,出列时则是按照优先级较小的优先出列。对于这个较高级别的队列结构,scrapy要提供一系列的方法来管理它,原有的scrapy scheduler以无法满足,此时需要使用scrapy-redis中的scheduler组件。
duplication filter:
scrapy中用集合来实现request的去重功能。scrapy中将已经发送的request指纹信息放入到set中,然后把将要发送的request指纹信息和set中的进行比较,如果存在则返回,否则继续进行操作。核心实现功能代码如下:
1 def request_seen(self,request): 2 #self.request_figerprints就是一个指纹集合 3 fp=self.request_fingerprint(request) 4 5 #这就是判重的核心操作 6 if fp in self.fingerprints: 7 return True 8 self.fingerprints.add(fp) 9 if self.file: 10 self.file.write(fp+os.linesep)