


原文出处:
http://www.c-sharpcorner.com/UploadFile/rmcochran/csharp_memory01122006130034PM/csharp_memory.aspx
尽管在.NET framework下我们并不需要担心内存管理和垃圾回收(Garbage Collection),但是我们还是应该了解它们,以优化我们的应用程序。同时,还需要具备一些基础的内存管理工作机制的知识,这样能够有助于解释我们日常程序编写中的变量的行为。在本文中我将讲解栈和堆的基本知识,变量类型以及为什么一些变量能够按照它们自己的方式工作。
在.NET framework环境下,当我们的代码执行时,内存中有两个地方用来存储这些代码。假如你不曾了解,那就让我来给你介绍栈(Stack)和堆(Heap)。栈和堆都用来帮助我们运行代码的,它们驻留在机器内存中,且包含所有代码执行所需要的信息。
* 栈vs堆:有什么不同?
栈负责保存我们的代码执行(或调用)路径,而堆则负责保存对象(或者说数据,接下来将谈到很多关于堆的问题)的路径。
可以将栈想象成一堆从顶向下堆叠的盒子。当每调用一次方法时,我们将应用程序中所要发生的事情记录在栈顶的一个盒子中,而我们每次只能够使用栈顶的那个盒子。当我们栈顶的盒子被使用完之后,或者说方法执行完毕之后,我们将抛开这个盒子然后继续使用栈顶上的新盒子。堆的工作原理比较相似,但大多数时候堆用作保存信息而非保存执行路径,因此堆能够在任意时间被访问。与栈相比堆没有任何访问限制,堆就像床上的旧衣服,我们并没有花时间去整理,那是因为可以随时找到一件我们需要的衣服,而栈就像储物柜里堆叠的鞋盒,我们只能从最顶层的盒子开始取,直到发现那只合适的。
[heapvsstack1.gif]
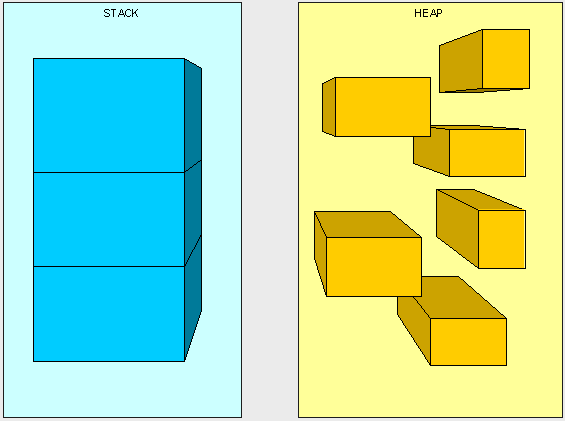
以上图片并不是内存中真实的表现形式,但能够帮助我们区分栈和堆。
栈是自行维护的,也就是说内存自动维护栈,当栈顶的盒子不再被使用,它将被抛出。相反的,堆需要考虑垃圾回收,垃圾回收用于保持堆的整洁性,没有人愿意看到周围都是赃衣服,那简直太臭了!
* 栈和堆里有些什么?
当我们的代码执行的时候,栈和堆中主要放置了四种类型的数据:值类型(Value Type),引用类型(Reference Type),指针(Pointer),指令(Instruction)。
1.值类型:
在C#中,所有被声明为以下类型的事物被称为值类型:
bool
byte
char
decimal
double
enum
float
int
long
sbyte
short
struct
uint
ulong
ushort
2.引用类型:
所有的被声明为以下类型的事物被称为引用类型:
class
interface
delegate
object
string
3.指针:
在内存管理方案中放置的第三种类型是类型引用,引用通常就是一个指针。我们不会显示的使用指针,它们由公共语言运行时(CLR)来管理。指针(或引用)是不同于引用类型的,是因为当我们说某个事物是一个引用类型时就意味着我们是通过指针来访问它的。指针是一块内存空间,而它指向另一个内存空间。就像栈和堆一样,指针也同样要占用内存空间,但它的值是一个内存地址或者为空。
[heapvsstack2.gif]

4.指令:
在后面的文章中你会看到指令是如何工作的...
* 如何决定放哪儿?
这里有一条黄金规则:
1. 引用类型总是放在堆中。(够简单的吧?)
2. 值类型和指针总是放在它们被声明的地方。(这条稍微复杂点,需要知道栈是如何工作的,然后才能断定是在哪儿被声明的。)
就像我们先前提到的,栈是负责保存我们的代码执行(或调用)时的路径。当我们的代码开始调用一个方法时,将放置一段编码指令(在方法中)到栈上,紧接着放置方法的参数,然后代码执行到方法中的被“压栈”至栈顶的变量位置。通过以下例子很容易理解...
下面是一个方法(Method):
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
现在就来看看在栈顶发生了些什么,记住我们所观察的栈顶下实际已经压入了许多别的内容。
首先方法(只包含需要执行的逻辑字节,即执行该方法的指令,而非方法体内的数据)入栈,紧接着是方法的参数入栈。(我们将在后面讨论更多的参数传递)
[heapvsstack3.gif]
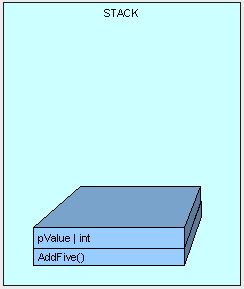
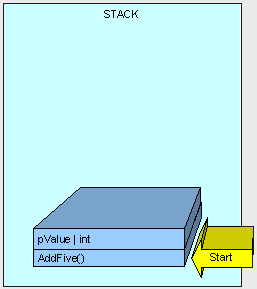
接着,控制(即执行方法的线程)被传递到堆栈中AddFive()的指令上,
[heapvsstack4.gif]

当方法执行时,我们需要在栈上为“result”变量分配一些内存,
[heapvsstack5.gif]
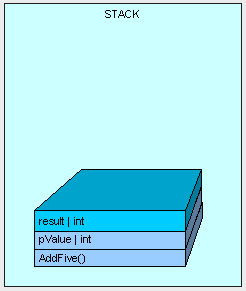
The method finishes execution and our result is returned.
方法执行完成,然后方法的结果被返回。
[heapvsstack6.gif]
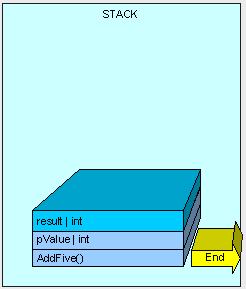
通过将栈指针指向AddFive()方法曾使用的可用的内存地址,所有在栈上的该方法所使用内存都被清空,且程序将自动回到栈上最初的方法调用的位置(在本例中不会看到)。
[heapvsstack7.gif]
在这个例子中,我们的"result"变量是被放置在栈上的,事实上,当值类型数据在方法体中被声明时,它们都是被放置在栈上的。
值类型数据有时也被放置在堆上。记住这条规则--值类型总是放在它们被声明的地方。好的,如果一个值类型数据在方法体外被声明,且存在于一个引用类型中,那么它将被堆中的引用类型所取代。
来看另一个例子:
假如我们有这样一个MyInt类(它是引用类型因为它是一个类类型):
public class MyInt
{
public int MyValue;
}
然后执行下面的方法:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
就像前面提到的,方法及方法的参数被放置到栈上,接下来,控制被传递到堆栈中AddFive()的指令上。
[heapvsstack8.gif]
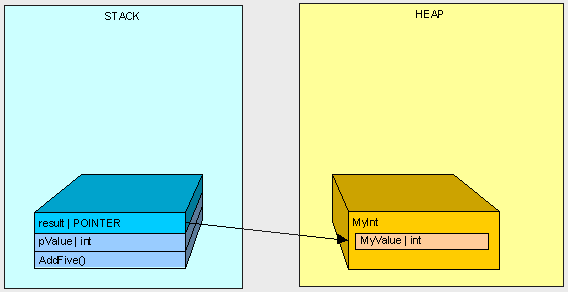
接着会出现一些有趣的现象...
因为"MyInt"是一个引用类型,它将被放置在堆上,同时在栈上生成一个指向这个堆的指针引用。
[heapvsstack9.gif]
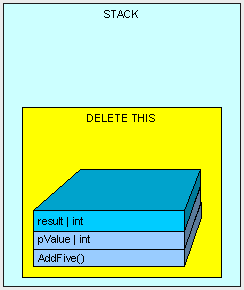
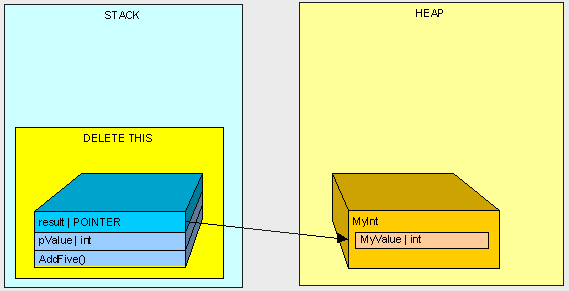
在AddFive()方法被执行之后,我们将清空...
[heapvsstack10.gif]
我们将剩下孤独的MyInt对象在堆中(栈中将不会存在任何指向MyInt对象的指针!)
[heapvsstack11.gif]

这就是垃圾回收器(后简称GC)起作用的地方。当我们的程序达到了一个特定的内存阀值,我们需要更多的堆空间的时候,GC开始起作用。GC将停止所有正在运行的线程,找出在堆中存在的所有不再被主程序访问的对象,并删除它们。然后GC会重新组织堆中所有剩下的对象来节省空间,并调整栈和堆中所有与这些对象相关的指针。你肯定会想到这个过程非常耗费性能,所以这时你就会知道为什么我们需要如此重视栈和堆里有些什么,特别是在需要编写高性能的代码时。
Ok... 这太棒了, 当它是如何影响我的?
Good question.
当我们使用引用类型时,我们实际是在处理该类型的指针,而非该类型本身。当我们使用值类型时,我们是在使用值类型本身。听起来很迷糊吧?
同样,例子是最好的描述。
假如我们执行以下的方法:
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
}
我们将得到值3,很简单,对吧?
假如我们首先使用MyInt类
public class MyInt
{
public int MyValue;
}
接着执行以下的方法:
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y = x;
y.MyValue = 4;
return x.MyValue;
}
我们将得到什么?... 4!
为什么?... x.MyValue怎么会变成4了呢?... 看看我们所做的然后就知道是怎么回事了:
在第一例子中,一切都像计划的那样进行着:
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
}
[heapvsstack12.gif]
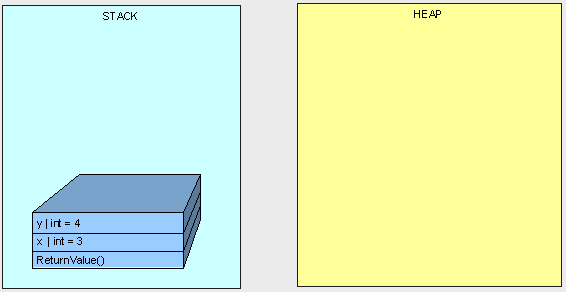
在第二个例子中,我们没有得到"3"是因为变量"x"和"y"都同时指向了堆中相同的对象。
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
}
[heapvsstack13.gif]

希望以上内容能够使你对C#中的值类型和引用类型的基本区别有一个更好的认识,并且对指针及指针是何时被使用的有一定的基本了解。在系列的下一个部分,我们将深入内存管理并专门讨论方法参数。
To be continued...
原文出处:
http://www.c-sharpcorner.com/UploadFile/rmcochran/csharp_memory2B01142006125918PM/csharp_memory2B.aspx
尽管在.NET framework下我们并不需要担心内存管理和垃圾回收(Garbage Collection),但是我们还是应该了解它们,以优化我们的应用程序。同时,还需要具备一些基础的内存管理工作机制的知识,这样能够有助于解释我们日常程序编写中的变量的行为。在本文中我将讲解我们必须要注意的方法传参的行为。
在第一部分里我介绍了栈和堆的基本功能,还介绍到了在程序执行时值类型和引用类型是如何分配的,而且还谈到了指针。
* 参数,大问题
这里有一个代码执行时的详细介绍,我们将深入第一部分出现的方法调用过程...
当我们调用一个方法时,会发生以下的事情:
1.方法执行时,首先在栈上为对象实例中的方法分配空间,然后将方法拷贝到栈上(此时的栈被称为帧),但是该空间中只存放了执行方法的指令,并没有方法内的数据项。
3.方法参数的分配和拷贝是需要空间的,这一点是我们需要进一步注意。
示例代码如下:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
此时栈开起来是这样的:

就像第一部分讨论的那样,放在栈上的参数是如何被处理的,需要看看它是值类型还是引用类型。值类型的值将被拷贝到栈上,而引用类型的引用(或者说指针)将被拷贝到栈上。
* 值类型传递
首先,当我们传递一个值类型参数时,栈上被分配好一个新的空间,然后该参数的值被拷贝到此空间中。
来看下面的方法:
class Class1
{
public void Go()
{
int x = 5;
AddFive(x);
Console.WriteLine(x.ToString());
}
public int AddFive(int pValue)
{
pValue += 5;
return pValue;
}
}
方法Go()被放置到栈上,然后执行,整型变量"x"的值"5"被放置到栈顶空间中。

然后AddFive()方法被放置到栈顶上,接着方法的形参值被拷贝到栈顶,且该形参的值就是"x"的拷贝。

当AddFive()方法执行完成之后,线程就通过预先放置的指令返回到Go()方法的地址,然后从栈顶依次将变量pValue和方法AddFive()移除掉:

所以我们的代码输出的值是"5",对吧?这里的关键之处就在于任何传入方法的值类型参数都是复制拷贝的,所以原始变量中的值是被保留下来而没有被改变的。
必须注意的是,如果我们要将一个非常大的值类型数据(如数据量大的struct类型)入栈,它会占用非常大的内存空间,而且会占有过多的处理器周期来进行拷贝复制。栈并没有无穷无尽的空间,它就像在水龙头下盛水的杯子,随时可能溢出。struct是一个能够存放大量数据的值类型成员,我们必须小心地使用。
这里有一个存放大数据类型的struct:
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
来看看当我们执行了Go()和DoSometing()方法时会发生什么:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(x);
}
public void DoSomething(MyStruct pValue)
{
// DO SOMETHING HERE....
}
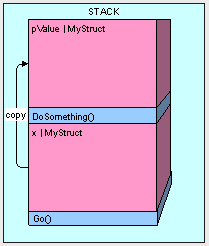
这将会非常的低效。想象我们要是传递2000次MyStruct,你就会明白程序是怎么瘫痪掉的了。
那么我们应该如何解决这个问题?可以通过下列方式来传递原始值的引用:
public void Go()
{
MyStruct x = new MyStruct();
DoSomething(ref x);
}
public struct MyStruct
{
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
public void DoSomething(ref MyStruct pValue)
{
// DO SOMETHING HERE....
}
通过这种方式我们能够提高内存中对象分配的效率。

唯一需要注意的是,在我们通过引用传递值类型时我们会修改该值类型的值,也就是说pValue值的改变会引起x值的改变。执行以下代码,我们的结果会变成"123456",这是因为pValue实际指向的内存空间与x变量声明的内存空间是一致的。
public void Go()
{
MyStruct x = new MyStruct();
x.a = 5;
DoSomething(ref x);
Console.WriteLine(x.a.ToString());
}
public void DoSomething(ref MyStruct pValue)
{
pValue.a = 12345;
}
* 引用类型传递
传递引用类型参数的情况类似于先前例子中通过引用来传递值类型的情况。
如果我们使用引用类型:
public class MyInt
{
public int MyValue;
}
然后调用Go()方法,MyInt对象将放置在堆上:
public void Go()
{
MyInt x = new MyInt();
}

如果我们执行下面的Go()方法:
public void Go()
{
MyInt x = new MyInt();
x.MyValue = 2;
DoSomething(x);
Console.WriteLine(x.MyValue.ToString());
}
public void DoSomething(MyInt pValue)
{
pValue.MyValue = 12345;
}
将发生这样的事情...

1.方法Go()入栈
2.Go()方法中的变量x入栈
3.方法DoSomething()入栈
4.参数pValue入栈
5.x的值(MyInt对象的在栈中的指针地址)被拷贝到pValue中
因此,当我们通过MyInt类型的pValue来改变堆中MyInt对象的MyValue成员值后,接着又使用指向该对象的另一个引用x来获取了其MyValue成员值,得到的值就变成了"12345"。
而更有趣的是,当我们通过引用来传递一个引用类型时,会发生什么?
让我们来检验一下。假如我们有一个"Thing"类和两个继承于"Thing"的"Animal"和"Vegetable" 类:
public class Thing
{
}
public class Animal:Thing
{
public int Weight;
}
public class Vegetable:Thing
{
public int Length;
}
然后执行下面的Go()方法:
public void Go()
{
Thing x = new Animal();
Switcharoo(ref x);
Console.WriteLine(
"x is Animal : "
+ (x is Animal).ToString());
Console.WriteLine(
"x is Vegetable : "
+ (x is Vegetable).ToString());
}
public void Switcharoo(ref Thing pValue)
{
pValue = new Vegetable();
}
变量x被返回为Vegetable类型。
x is Animal : False
x is Vegetable : True
让我们来看看发生了什么:

1.Go()方法入栈
2.x指针入栈
3.Animal对象实例化到堆中
4.Switcharoo()方法入栈
5.pValue入栈且指向x

6.Vegetable对象实例化到堆中
7.x的值通过被指向Vegetable对象地址的pValue值所改变。
如果我们不使用Thing的引用,相反的,我们得到结果变量x将会是Animal类型的。
如果以上代码对你来说没有什么意义,那么请继续看看我的文章中关于引用变量的介绍,这样能够对引用类型的变量是如何工作的会有一个更好的理解。
我们看到了内存是怎样处理参数传递的,在系列的下一部分中,我们将看看栈中的引用变量发生了些什么,然后考虑当我们拷贝对象时是如何来解决某些问题的。
To be continued...
原文出处
http://www.c-sharpcorner.com/UploadFile/rmcochran/chsarp_memory401152006094206AM/chsarp_memory4.aspx
尽管在.NET framework下我们并不需要担心内存管理和垃圾回收(Garbage Collection),但是我们还是应该了解它们,以优化我们的应用程序。同时,还需要具备一些基础的内存管理工作机制的知识,这样能够有助于解释我们日常程序编写中的变量的行为。在本文中我们将涉及到堆中引用变量引起的问题,以及如何使用ICloneable接口来解决该问题。
需要回顾堆栈基础,值类型和引用类型,请转到第一部分和第二部分
* 副本并不是真的副本
为了清楚的阐明问题,让我们来比较一下当堆中存在值类型和引用类型时都发生了些什么。首先来看看值类型,如下面的类和结构。这里有一个类Dude,它的成员中有一个string型的Name字段及两个Shoe类型的字段--RightShoe、LeftShoe,还有一个CopyDude()方法可以很容易地生成新的Dude实例。
public struct Shoe{
public string Color;
}
public class Dude
{
public string Name;
public Shoe RightShoe;
public Shoe LeftShoe;
public Dude CopyDude()
{
Dude newPerson = new Dude();
newPerson.Name = Name;
newPerson.LeftShoe = LeftShoe;
newPerson.RightShoe = RightShoe;
return newPerson;
}
public override string ToString()
{
return (Name + " : Dude!, I have a " + RightShoe.Color +
" shoe on my right foot, and a " +
LeftShoe.Color + " on my left foot.");
}
}
Dude是引用类型,而且由于结构Shoe的两个字段是Dude类的成员,所以它们都被放在了堆上。

当我们执行以下的方法时:
public static void Main()
{
Class1 pgm = new Class1();
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.CopyDude();
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
我们得到了预期的结果:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot.
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.
如果我们将结构Shoe换成引用类型会发生什么?问题就在于此。
假如我们将Shoe改为引用类型:
public class Shoe{
public string Color;
}
然后在与前面相同的Main()方法中运行,再来看看我们的结果:
Bill : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
可以看到红鞋子被穿到别人(Bill)脚上了,很明显出错了。你想知道这是为什么吗?我们再来看看堆就明白了。

由于我们现在使用的Shoe是引用类型而非值类型,当引用类型的内容被拷贝时实际上只拷贝了该类型的指针(并没有拷贝实际的对象),我们需要作一些额外的工作来使我们的引用类型能够像值类型一样使用。
幸运的是.NET Framework中已经有了一个IClonealbe接口(System.ICloneable)来帮助我们解决问题。使用这个接口可以规定所有的Dude类必须遵守和定义引用类型应如何被复制,以避免出现"共享鞋子"的问题。所有需要被克隆的类都需要使用ICloneable接口,包括Shoe类。
System.IClonealbe只有一个方法定义:Clone()
public object Clone()
{
}
我们应该在Shoe类中这样实现:
public class Shoe : ICloneable
{
public string Color;
#region ICloneable Members
public object Clone()
{
Shoe newShoe = new Shoe();
newShoe.Color = Color.Clone() as string;
return newShoe;
}
#endregion
}
在方法Clone()中,我们创建了一个新的Shoe对象,克隆了所有引用类型,并拷贝了所有值类型,然后返回了这个新对象。你可能注意到了string类已经实现了ICloneable接口,所以我们可以直接调用Color.Clone()方法。因为Clone()方法返回的是对象的引用,所以我们需要在设置鞋的颜色前重构这个引用。
接着,在我们的CopyDude()方法中我们需要克隆鞋子而非拷贝它们:
public Dude CopyDude()
{
Dude newPerson = new Dude();
newPerson.Name = Name;
newPerson.LeftShoe = LeftShoe.Clone() as Shoe;
newPerson.RightShoe = RightShoe.Clone() as Shoe;
return newPerson;
}
现在,当我们执行Main()函数时:
public static void Main()
{
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.CopyDude();
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
我们得到的是:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
这就是我们想要的。

在通常情况下,我们应该"克隆"引用类型,"拷贝"值类型。(这样,在你调试以上介绍的情况中的问题时,会减少你买来控制头痛的阿司匹林的药量)
在头痛减少的激烈下,我们可以更进一步地使用Dude类来实现IClonealbe,而不是使用CopyDude()方法。
public class Dude: ICloneable
{
public string Name;
public Shoe RightShoe;
public Shoe LeftShoe;
public override string ToString()
{
return (Name + " : Dude!, I have a " + RightShoe.Color +
" shoe on my right foot, and a " +
LeftShoe.Color + " on my left foot.");
}
#region ICloneable Members
public object Clone()
{
Dude newPerson = new Dude();
newPerson.Name = Name.Clone() as string;
newPerson.LeftShoe = LeftShoe.Clone() as Shoe;
newPerson.RightShoe = RightShoe.Clone() as Shoe;
return newPerson;
}
#endregion
}
然后我们将Main()方法中的Dude.CopyDude()方法改为Dude.Clone():
public static void Main()
{
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.Clone() as Dude;
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
最后的结果是:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot.
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.
非常好!
比较有意思的是请注意为System.String类分配的操作符("="号),它实际上是将string型对象进行克隆,所以你不必担心会发生引用拷贝。尽管如此你还是得注意一下内存的膨胀。
如果你重新看一下前面的那些图,会发现string型应该是引用类型,所以它应该是一个指针(这个指针指向堆中的另一个对象),但是为了方便起见,我在图中将string型表示为值类型(实际上应该是一个指针),因为通过"="号重新被赋值的string型对象实际上是被自动克隆过后的。
总结一下:
通常,如果我们打算将我们的对象用于拷贝,那么我们的类应该实现IClonealbe借口,这样能够使引用类型仿效值类型的行为。从中可以看到,搞清楚我们所使用的变量的类型是非常重要的,因为在值类型和引用类型的对象在内存中的分配是有区别的。
在下一部分内容中,会看到我们是怎样来减少代码在内存中的"脚印"的,将会谈到期待已久的垃圾回收器(Garbage Collection)。
To be continued...
终于翻完了第四篇,本来每次都是周末发的,可惜上周末有些事儿没忙过来,所以今天中午给补上来。不知道这套文章还能不能继续了,因为作者也只写到了第四篇,连他都不知道第五篇什么时候出得来...
原文出处
http://www.c-sharpcorner.com/UploadFile/rmcochran/csharp_memory_401282006141834PM/csharp_memory_4.aspx
可以参看该系列文章的前面部分内容:Part I,Part II,Part III
尽管在.NET framework下我们并不需要担心内存管理和垃圾回收(Garbage Collection),但是我们还是应该了解它们,以优化我们的应用程序。同时,还需要具备一些基础的内存管理工作机制的知识,这样能够有助于解释我们日常程序编写中的变量的行为。在本文中我们将深入理解垃圾回收器,还有如何利用静态类成员来使我们的应用程序更高效。
* 更小的步伐 == 更高效的分配
为了更好地理解为什么更小的足迹会更高效,这需要我们对.NET的内存分配和垃圾回收专研得更深一些。
* 图解:
让我们来仔细看看GC。如果我们需要负责"清除垃圾",那么我们需要拟定一个高效的方案。很显然,我们需要决定哪些东西是垃圾而哪些不是。
为了决定哪些是需要保留的,我们首先假设所有的东西都不是垃圾(墙角里堆着的旧报纸,阁楼里贮藏的废物,壁橱里的所有东西,等等)。假设在我们的生活当中有两位朋友:Joseph Ivan Thomas(JIT)和Cindy Lorraine Richmond(CLR)。Joe和Cindy知道它们在使用什么,而且给了我们一张列表说明了我们需要需要些什么。我们将初始列表称之为"根"列表,因为我们将它用作起始点。我们需要保存一张主列表来记录出我们家中的必备物品。任何能够使必备物品正常工作或使用的东西也将被添加到列表中来(如果我们要看电视,那么就不能扔掉遥控器,所以遥控器将被添加到列表。如果我们要使用电脑,那么键盘和显示器就得添加到列表)。
这就是GC如何保存我们的物品的,它从即时编译器(JIT)和通用语言运行时(CLR)中获得"根"对象引用的列表,然后递归地搜索出其他对象引用来建立一张我们需要保存的物品的图表。
根包括:
* 全局/静态指针。为了使我们的对象不被垃圾回收掉的一种方式是将它们的引用保存在静态变量中。
* 栈上的指针。我们不想丢掉应用程序中需要执行的线程里的东西。
* CPU寄存器指针。托管堆中哪些被CPU寄存器直接指向的内存地址上的东西必须得保留。

在以上图片中,托管堆中的对象1、3、5都被根所引用,其中1和5时直接被引用,而3时在递归查找时被发现的。像我们之前的假设一样,对象1是我们的电视机,对象3是我们的遥控器。在所有对象被递归查找出来之后我们将进入下一步--压缩。
* 压缩
我们现在已经绘制出哪些是我们需要保留的对象,那么我们就能够通过移动"保留对象"来对托管堆进行整理。

幸运的是,在我们的房间里没有必要为了放入别的东西而去清理空间。因为对象2已经不再需要了,所以GC会将对象3移下来,同时修复它指向对象1的指针。

然后,GC将对象5也向下移,

现在所有的东西都被清理干净了,我们只需要写一张便签贴到压缩后的堆上,让Claire(指CLR)知道在哪儿放入新的对象就行了。

理解GC的本质会让我们明白对象的移动是非常费力的。可以看出,假如我们能够减少需要移动的物品大小是非常有意义的,通过更少的拷贝动作能够使我们提升整个GC的处理性能。
* 托管堆之外是怎样的情景呢?
作为负责垃圾回收的人员,有一个容易出现入的问题是在打扫房间时如何处理车里的东西,当我们打扫卫生时,我们需要将所有物品清理干净。那家里的台灯和车里的电池怎么办?
在一些情况下,GC需要执行代码来清理非托管资源(如文件,数据库连接,网络连接等),一种可能的方式是通过finalizer来进行处理。
 class Sample
class Sample

 {
{ ~Sample()
~Sample()
 { // FINALIZER: CLEAN UP HERE
{ // FINALIZER: CLEAN UP HERE }
} }
}在对象创建期间,所有带有finalizer的对象都将被添加到一个finalizer队列中。对象1、4、5都有finalizer,且都已在finalizer队列当中。让我们来看看当对象2和4在应用程序中不再被引用,且系统正准备进行垃圾回收时会发生些什么。

对象2会像通常情况下那样被垃圾回收器回收,但是当我们处理对象4时,GC发现它存在于finalizer队列中,那么GC就不会回收对象4的内存空间,而是将对象4的finalizer移到一个叫做"freachable"的特殊队列中。

有一个专门的线程来执行freachable队列中的项,对象4的finalizer一旦被该线程所处理,就将从freachable队列中被移除,然后对象4就等待被回收。

因此对象4将存活至下一轮的垃圾回收。
由于在类中添加一个finalizer会增加GC的工作量,这种工作是十分昂贵的,而且会影响垃圾回收的性能和我们的程序。最好只在你确认需要finalizer时才使用它。
在清理非托管资源时有一种更好的方法:在显式地关闭连接时,使用IDisposalbe接口来代替finalizer进行清理工作会更好些。
* IDisposable
实现IDisposable接口的类需要执行Dispose()方法来做清理工作(这个方法是IDisposable接口中唯一的签名)。因此假如我们使用如下的带有finalizer的ResourceUser类:
public class ResourceUser { ~ResourceUser() // THIS IS A FINALIZER { // DO CLEANUP HERE }}
我们可以使用IDisposable来以更好的方式实现相同的功能:
public class ResourceUser : IDisposable{ IDisposable Members#region IDisposable Members public void Dispose() { // CLEAN UP HERE!!! } #endregion}IDisposable被集成在了using块当中。在using()方法中声明的对象在using块的结尾处将调用Dispose()方法,using块之外该对象将不再被引用,因为它已经被认为是需要进行垃圾回收的对象了。
public static void DoSomething(){ResourceUser rec = new ResourceUser();using (rec){ // DO SOMETHING } // DISPOSE CALLED HERE // DON'T ACCESS rec HERE}我更喜欢将对象声明放到using块中,因为这样可视化很强,而且rec对象在using块的作用域之外将不再有效。这种模式的写法更符合IDisposable接口的初衷,但这并不是必须的。
public static void DoSomething(){using (ResourceUser rec = new ResourceUser()){ // DO SOMETHING } // DISPOSE CALLED HERE}
在类中使用using()块来实现IDisposable接口,能够使我们在清理垃圾对象时不需要写额外的代码来强制GC回收我们的对象。
* 静态方法
静态方法属于一种类型,而不是对象的实例,它允许创建能够被类所共享的方法,且能够达到"减肥"的效果,因为只有静态方法的指针(8 bytes)在内存当中移动。静态方法实体仅在应用程序生命周期的早期被一次性加载,而不是在我们的类实例中生成。当然,方法越大那么将其作为静态就越高效。假如我们的方法很小(小于8 bytes),那么将其作为静态方法反而会影响性能,因为这时指针比它指向的方法所占的空间还大些。
接着来看看例子...
我们的类中有一个公共的方法SayHello():
class Dude{ private string _Name = "Don"; public void SayHello() { Console.WriteLine(this._Name + " says Hello"); }} 在每一个Dude类实例中SayHello()方法都会占用内存空间。

一种更高效的方式是采用静态方法,这样我们只需要在内存中放置唯一的SayHello()方法,而不论存在多少个Dude类实例。因为静态成员不是实例成员,我们不能使用this指针来进行方法的引用。
class Dude{ private string _Name = "Don"; public static void SayHello(string pName) { Console.WriteLine(pName + " says Hello"); }}

请注意我们在传递变量时栈上发生了些什么(可以参看<第二部分>)。我们需要通过例子的看看是否需要使用静态方法来提升性能。例如,一个静态方法需要很多参数而且没有什么复杂的逻辑,那么在使用静态方法时我们可能会降低性能。
* 静态变量:注意了!
对于静态变量,有两件事情我们需要注意。假如我们的类中有一个静态方法用于返回一个唯一值,而下面的实现会造成bug:
class Counter{ private static int s_Number = 0; public static int GetNextNumber() { int newNumber = s_Number; // DO SOME STUFF s_Number = newNumber + 1; return newNumber; }}假如有两个线程同时调用GetNextNumber()方法,而且它们在s_Number的值增加前都为newNumber分配了相同的值,那么它们将返回同样的结果!
我们需要显示地为方法中的静态变量锁住读/写内存的操作,以保证同一时刻只有一个线程能够执行它们。线程管理是一个非常大的主题,而且有很多途径可以解决线程同步的问题。使用lock关键字能让代码块在同一时刻仅能够被一个线程访问。一种好的习惯是,你应该尽量锁较短的代码,因为在程序执行lock代码块时所有线程都要进入等待队列,这是非常低效的。
class Counter{ private static int s_Number = 0; public static int GetNextNumber() { lock (typeof(Counter)) { int newNumber = s_Number; // DO SOME STUFF newNumber += 1; s_Number = newNumber; return newNumber; } }}
* 静态变量:再次注意了!
静态变量引用需要注意的另一件事情是:记住,被"root"引用的事物是不会被GC清理掉的。我遇到过的一个最烦人的例子:
class Olympics{ public static Collection<Runner> TryoutRunners;} class Runner{ private string _fileName; private FileStream _fStream; public void GetStats() { FileInfo fInfo = new FileInfo(_fileName); _fStream = _fileName.OpenRead(); }}由于Runner集合在Olympics类中是静态的,不仅集合中的对象不会被GC释放(它们都直接被根所引用),而且你可能注意到了,每次执行GetStats()方法时都会为那个文件开放一个文件流,因为它没有被关闭所以也不会被GC释放,这个代码将会给系统造成很大的灾难。假如我们有100000个运动员来参加奥林匹克,那么会由于太多不可回收的对象而难以释放内存。天啦,多差劲的性能呀!
* Singleton
有一种方法可以保证一个类的实例在内存中始终保持唯一,我们可以采用Gof中的Singleton模式。(Gof:Gang of Four,一部非常具有代表性的设计模式书籍的作者别称,归纳了23种常用的设计模式)
public class Earth{ private static Earth _instance = new Earth(); private Earth() { } public static Earth GetInstance() { return _instance; }}我们的Earth类有一个私有构造器,所以Earth类能够执行它的构造器来创建一个Earth实例。我们有一个Earth类的静态实例,还有一个静态方法来获得这个实例。这种特殊的实现是线程安全的,因为CLR保证了静态变量的创建是线程安全的。这是我认为在C#中实现singleton模式最为明智的方式。
* .NET Framework 2.0中的静态类
在.NET 2.0 Framework中我们有一种静态类,此类中的所有成员都是静态的。这中特性对于工具类是非常有用的,而且能够节省内存空间,因为该类只存在于内存中的某个地方,不能在任何情况下被实例化。
* 总结一下...
总的来说,我们能够提升GC表现的方式有:
1. 清理工作。不要让资源一直打开!尽可能地保证关闭所有打开的连接,清除所有非托管的资源。当使用非托管对象时,初始化工作尽量完些,清理工作要尽量及时点。
2. 不要过度地引用。需要时才使用引用对象,记住,如果你的对象是活动着的,所有被它引用的对象都不会被垃圾回收。当我们想清理一些类所引用的事物,可以通过将这些引用设置为null来移除它们。我喜欢采用的一种方式是将未使用的引用指向一个轻量级的NullObject来避免产生null引用的异常。在GC进行垃圾回收时,更少的引用将减少映射处理的压力。
3. 少使用finalizer。Finalizer在垃圾回收时是非常昂贵的资源,我们应该只在必要时使用。如果我们使用IDisposable来代替finalizer会更高效些,因为我们的对象能够直接被GC回收而不是在第二次回收时进行。
4. 尽量保持对象和它们的子对象在一块儿。GC在复制大块内存数据来放到一起时是很容易的,而复制堆中的碎片是很费劲的,所以当我们声明一个包含许多其他对象的对象时,我们应该在初始化时尽量让他们在一块儿。
5. 最后,使用静态方法来保持对象的轻便也是可行的。
下一次,我们将更加深入GC的处理过程,看看在你的程序执行时GC是如何发现问题并清除它们的。
To be long long continued...


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?