机器学习第一周笔记
监督学习
回归:我们根据之前的数据预测出一个准确的输出值.
分类:推测出离散的输出值
训练集:在监督学习中我们有一个数据集,这个数据集被称训练集。
无监督学习
无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。别的都不知道,就是一个数据集。针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
单变量线性回归(Linear Regression with One Variable)
含义:单变量一个变量,只含有一个特征/输入变量的函数。
字母解释:
m:训练样本的数量
x:输入变量,往往也被称之为特征量。表示输入的特征。
y:输出变量或者目标变量,也就是预测结果。
(x,y):代表训练集中的一个实例
(x^(i),y^(i)):代表第i个观察实例,训练集里的第i行(上标i)
h:代表学习算法的解决方案或函数也称为假设.
代价函数
代价函数,又叫损失函数或成本函数,简单理解就是求误差的函数。
在线性回归中我们有一个像这样的训练集,代表了训练样本的数量,比如 。而我们的假设函数,也就是
用来进行预测的函数,是这样的线性函数形式::
我们把θi成为模型参数,在这个表达式中我们需要做的是考虑如何选择这两个参数值θ0和θ1。
模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
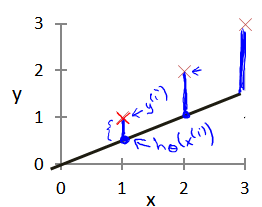
到后面会知道这是降低误差的其中一个方法称之为:均方误差,这种比较适合解决回归问题
为什么是1/2n,而不是1/n?
后面要用梯度下降法,要求导,这样求导多出的乘2就和二分之一抵消了,一个简化后面计算的技巧.
代价函数的直观理解
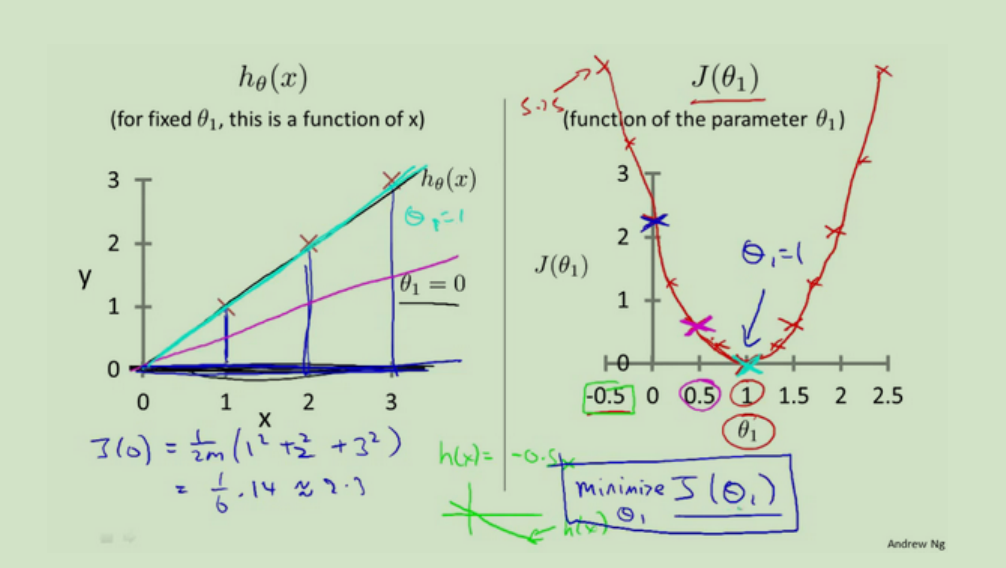
左图是θ1=0,θ1=1(也就是斜率是45和90)的值。发现θ=1时蓝色部分的差距最小趋近于0,也就是最拟合。
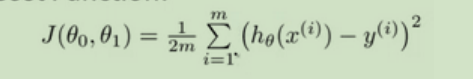
左图下面的那个蓝色的公式就是根据这个算的。
右图的顶点位置为这个函数的极小值。也就是最小代价函数,(成本函数,损失函数。)
梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 的最小值。对于J(θ0,θ1),我们需要求其最小值。
一般初始θ0=0和θ1=0;
因为梯度下降的时候是所以的特征值一起下降,也就是θ0,θ1同时操作,所以一般称之为批量梯度下降,其算法的公式为:
 批量梯度下降
批量梯度下降α是学习速率,理解成下山的步伐,大步子和小步子。
:=表示赋值
在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。我们要更新θ0和θ1
α后面那一堆是一个导数,转到坐标上来说实际是直线在那一点的斜率。
 同时让所有的参数减去学习速率乘以代价函数的导数。
同时让所有的参数减去学习速率乘以代价函数的导数。
梯度下降的线性回归
梯度下降算法和线性回归算法比较如图:

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
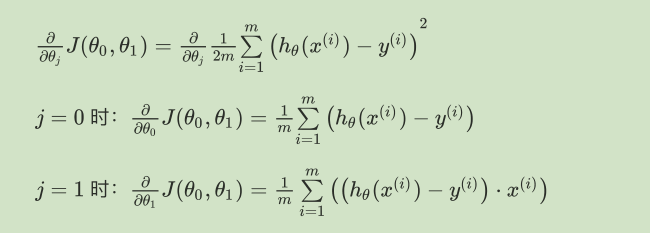
则算法改写成:
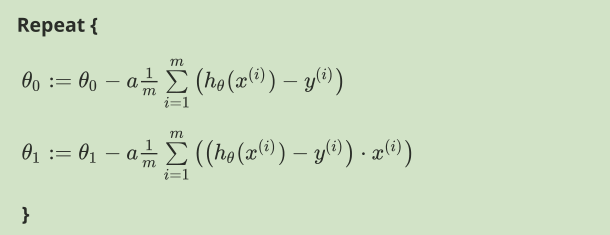
最后来几张我的笔记
 梯度下降参数分析
梯度下降参数分析 梯度下降和代价函数结合
梯度下降和代价函数结合 α学习速率变化α学习速率变化
α学习速率变化α学习速率变化 矩阵乘法以及妙用
矩阵乘法以及妙用 矩阵替代多次循环
矩阵替代多次循环 向量维度为一的矩阵
向量维度为一的矩阵
