
第三次课后作业
学号:2017********7047
姓名:车功明
码云地址:https://gitee.com/f-q/word_frequency.git
from string import punctuation
def process_file(dst):
try:
f = open(dst)
except IOError as s:
print (s)
return None
try:
bvffer = f.read()
except:
print ("Read File Error!")
return None
f.close()
return bvffer
打开、读取文档并将文档存储到buffer里面,执行完毕后关闭文档
def process_buffer(bvffer):
if bvffer:
word_freq = {}
for item in bvffer.strip().split():
word = item.strip(punctuation+' ')
if word in word_fred:
word_freq[word] += 1
else:
word_freq[word] = 1
return word_freq
将buffer内的数据进行切片,去掉符号空格,用for循环进行统计,将统计数据存储在word_freq并返回值
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]:
print (item)
将统计好的数据进行排序并输出前十个数据
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
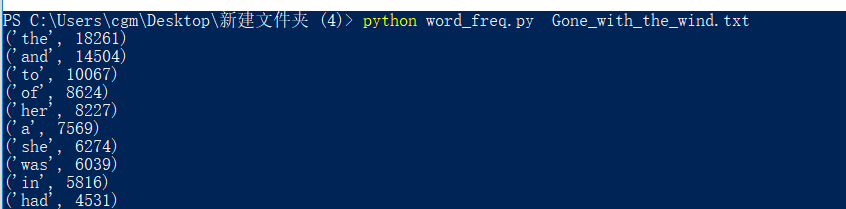
程序运行命令
程序运行结果
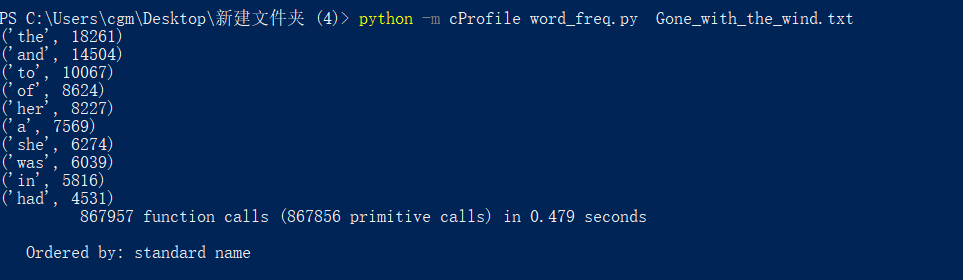
改进前
总时长
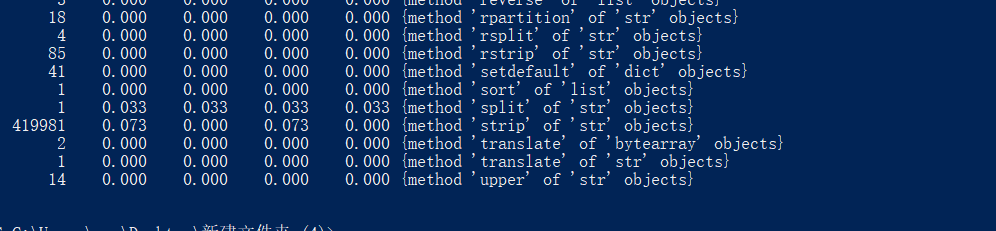
找到的执行时间最长,执行次数最多的代码
改进后:
总时长:
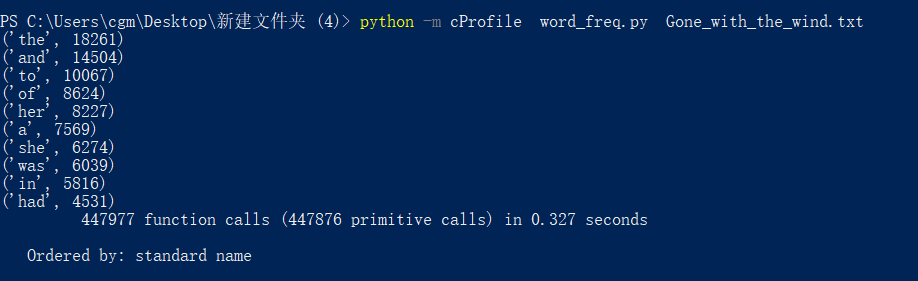
找到的执行时间最长,执行次数最多的代码:
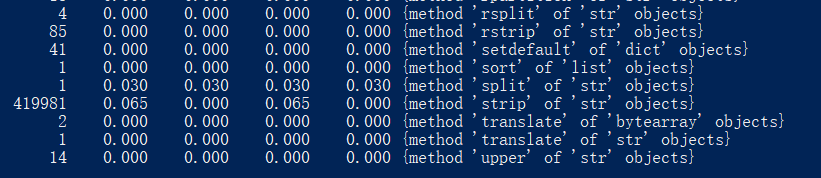
总结与反思:通过这次作业,我学会了用git上传文件分支,也学会了用python找到重复的单词,收获颇丰
