

BugPhobia进阶篇章:系统架构技术规格
0x01 :开发级需求分析
在开发过程中,团队本身在开发的起始阶段确定了基本的开发级需求分析:
|
在开发过程中,除了需要满足用户级需求以为,我们还需要针对开发团队的特点,满足一些开发级的需求和约束。作为一个学生团队,我们的开发时间极为有限,很难抽调出大量的时间进行开发。因此,开发效率就显得尤为关键。幸运地是,我们团队本身的学习能力较强,成员对于项目的开发较为积极,且对于新知识上手较快。因此,我们选择大量采用成熟的开源技术来加快我们整体的开发效率,力求以最低的成本实现最多的功能。 |
因此,在开发策略上,团队经过商议后确定了基本方向:
|
我们简要分析了往届遗留下来的代码,认为其功能较弱且不稳定,相较于目前日益成熟的一些开源技术来说,各方面都相去甚远。因此,我们经过细致的讨论后决定大胆地扔掉遗留代码,采用新技术重新实现。一则可以规避原有代码本身遗留下来的诸多问题,二则采用新技术可以快速地实现更多功能,三则可以使团队成员学到一些当下流行的技术,对成员将来的发展也会有所裨益。 |
综上所述,我们团队将尽可能地在开发中采用成熟的开源框架和开源技术,以实现我们对于开发效率和开发质量的需求。
0x02 :架构设计
0x0200 :设计摘要说明
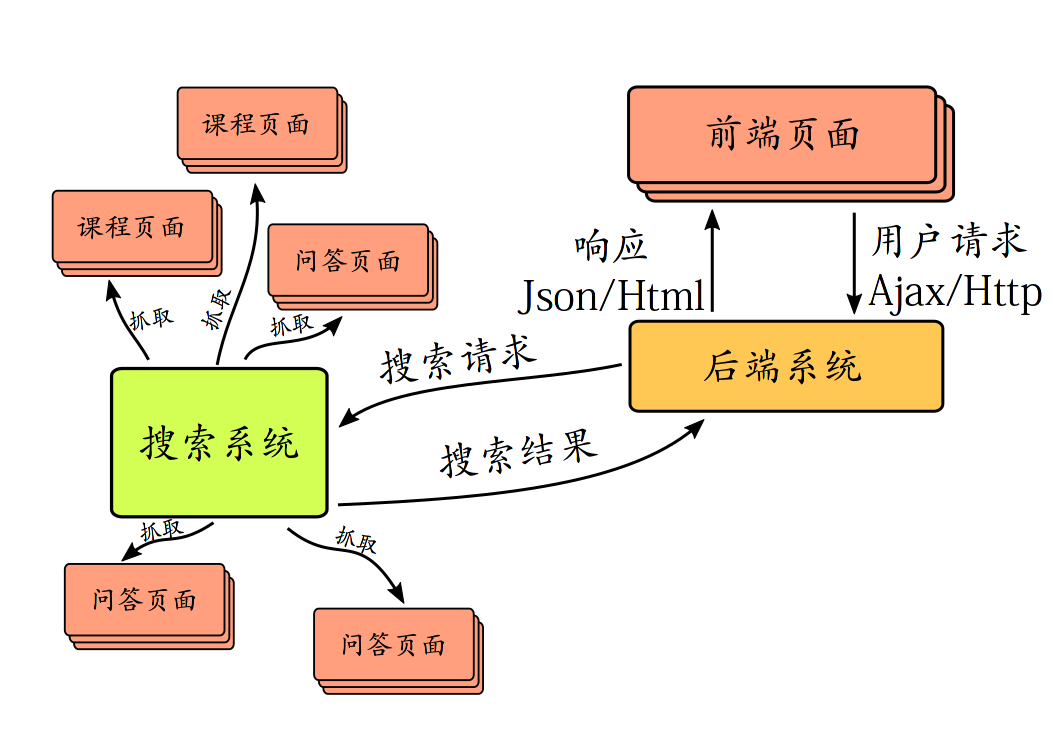
首先从架构的层次上,对本身的设计进行最简短的概述:
|
前端页面 |
直接与用户打交道,与用户进行交互 |
|
后端系统 |
负责处理用户的请求,并衔接搜索系统,为用户提供其想要的数据 |
|
搜索系统 |
负责搜集、整合数据,并响应网站后端的搜索请求,提供搜索结果 |
因此,不妨设计学霸在线系统的概念架构图如下图所示。
ü 搜索系统和后端系统为两个不同的执行体,二者通过HTTP协议进行交互,实现搜索系统与后端系统的解耦,使得我们可以轻松地扩展搜索系统本身,而不会对后端造成太大的影响。
ü 前端页面适当地运用ajax技术和后端进行交互,在减少服务器刷新压力的同时,也可以在一定程度上使前后端分离。
0x0204 :前端页面设计
|
我们团队的主要任务是大幅改善原有UI,实现一个优质的前端交互效果。为了达到这一目标,我们经过细致地调研,最终选用了Semantic UI前端框架。该框架具有时下流行的响应式布局特性。且该框架主打UI效果,很多组件都自带了动画效果,整体主题风格前卫,能体现出现代网页设计的特点,符合当代的审美观点。 Semantic UI最主要的特征是采用语义化开发。这套框架中的class都被命名为了描述其对应功能的形容词或者名词。这样的设计使得我们得以快速上手,对于我们提高开发效率大有帮助。使用该框架可以快速开发出现代化的高质量的前端页面,从而保证我们团队能够高质量地完成我们的任务。 |
0x0208 :后端系统设计
|
为了达到我们的开发级需求——快速开发,我们选择使用Python作为后端开发语言,并采用了Django这一重量级的后端框架来实现我们的后端。 Python的开发效率素来为人所称道。且我们团队中的大部分成员对于Python都有一定程度的了解,使用Python学习成本低,且开发效率高。因此,我们认为后端采用Python进行开发是一个相当正确的选择。 为了快速地实现我们的后端,我们采用了Django框架。Django框架经过开源社区多年来的努力,已经成为Python后端开发的不二之选。对于常见的Web开发需求,Django都提供了相应的模块。特别是几乎每个网站都必备的用户系统,Django中更是提供了相当多的支持,使得我们可以在短时间内实现我们的设计。除了其本身的功能外,Django具有大量的优质文档,以及成熟的开源社区。遇到问题时,我们有很多途径可以查找到相应的解决方案。Django的上述优势,使我们最终做出了采用它来实现我们的后端系统的决定。 后端系统主要有两部分功能,一部分是与用户系统相关的功能,如用户的登陆、管理、活动等等,另一部分则是与搜索引擎的衔接。同时还有一个模块负责整个站点的衔接、整合等。 |
0x0204 :搜索系统设计摘要
|
我们待搜索的内容一个有两类,一类是问答数据,一类是课程资源。这两类资源在系统中的处理是不同的,因此,在搜索系统设计的时候,我们就选择将这两类数据源直接分开。 对于课程资源的搜索类似于传统的页面爬取,我们采用分布式的nutch进行爬取,提高爬取能力的同时,减轻团队在爬取方面的工作量。同时,使用solr作为搜索引擎后端进行搜索,其对于海量数据的处理能力较强,可以实现较好的搜索效果。 对于问答资源,我们采用另外一种方案:StackExchange API可以直接返回Json格式编码好的相关信息。该API可以返回Tags、Posts、Answers、Questions等一系列信息。我们通过一个类似爬虫的程序在后台请求相关API,将数据直接整理入库,从而实现对于问答资源的整合。 |
0x03 :平台架构设计
0x0300 :HTTP Server
|
我们选用的Web服务器是Apache HTTP Server。Apache HTTP服务器是一个模块化的服务器,源于NCSAhttpd服务器,经过多次修改,成为世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上。 |
0x0304 :搜索引擎
对于搜索业务,我们选用了搭建在Apache服务器上的Solr + Nutch的配置。Solr和Nutch均为Apache项目中的搜索引擎项目,而二者所擅长的方向不同。
|
Nutch |
与类似于Apache Droids 这样的抓取框架相比,Nutch提供了我们很多很好的优势。其中,显而易见的一点是Nutch 提供了可以让你完整的实现搜索应用的特性集,其次是Nutch 的高可伸缩性(scalablity)和健壮性(robust),Nutch 运行在Hadoop 上,你可以运行在单态机器上,也可以运行在一个100台机器构成的集群(cluster)上,另外,Nutch 有很高的抓取质量,你可以配置哪些页面更重要,优先抓取,拥有丰富的APIs可以让你容易的集成Nutch 到你的应用中(可扩展性),更重要的一点是,Nutch 的内建组件,超链数据库(LinkDatabase),拥有该组件,可以大幅的提高搜索结果的关联度,Nutch 在被抓取的页面之间跟踪超链接,以便依靠內部链接来判断页面和页面之间的相关度。 |
|
Solr |
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。Solr是基于Lucene的全文搜索服务器,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。 |

