

(11)Django框架学习-Templates进阶用法--下
Template加载机制
一般来说,你在你的文件系统中存入模板,但你也可以使用自定义的template加载器去从其它地方
加载你的模板。
Django有两种方式去加载你的模板:
1. django.template.loader.get_template(template_name):get_template通过模板名参数,返回
一个模板对象,如果模板不存在,报错TemplateDoesNotExist
2. django.template.loader.select_template(template_name_list):参数为模板名的列表,返回第一个
存在的模板,如果列表中所有模板都不存在,就报错TemplateDoesNotExist
以上函数都默认在settings.py中TEMPLATE_DIRS属性下添加的路径下查找,不过,在内部机制上,这些函数
也可以指定不同的加载器来完成这些任务。
加载器的设置在settings.py中的TEMPLATE_LOADERS属性中,它是一个字符串元组类型,每一个字符串代表
一个loader类型。有些被默认开启,有些是默认关闭的。可以一起使用,直到找到模板为止。
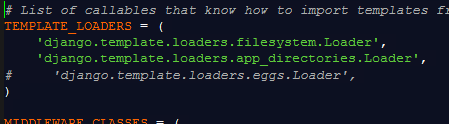
1. django.template.loaders.filesystem.Loader:默认开启,从TEMPLATE_DIRS路径中加载模板
2. django.template.loaders.app_directories.Loader:默认开启,这个装载器会在每一个INSTALLED_APPS
注册的app目录下寻找templates子目录,如果有的话,就会在子目录中加载模板。这样就可以把模板和
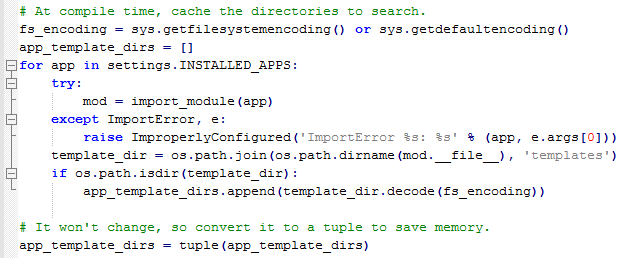
app放在一起,方便重用。这个装载器会有一些优化,在第一次导入的时候,会缓存包含templates子目录的app
包的列表。
优化的源码如下:
3. django.template.loaders.eggs.Loader:默认关闭,从egg文件中加载模板,egg文件类似jar包,python
中打包发布代码的一种方式。和app_directories Loader类似也是从app子目录template中加载egg文件。
扩展你的模板系统
一般是扩展模板的tag和filter两个功能。可以用来创建你自己的tag和filter功能库。
创建模板库
分为两步:
1. 首先决定由模板库在哪一个注册的app下放置,你可以放在一个已有的app目录下,也可以新建一个
专门管理模板库的app,比如python manage.py startapp myTemplateLibrary。推荐后者,
因为可以方便将来的重用。
2. 在app目录下创建templatetags子目录,并在里面创建两个文件,__init__.py,用来声明这是一个
包,另一个是你的tag/filter定义文件。比如myNewLibrary.py,那么在模板文件中可以这样使用:
{% load myNewLibrary %}
{% load %}只允许导入注册app目录下的模板库。这样做是为了保证你的模板库可以不被其它Django
程序使用。
实现自定义过滤器
1. 创建register变量
在你的模块文件中,你必须首先创建一个全局register变量,它是用来注册你自定义标签和过滤器的,
你需要在你的python文件的开始处,插入几下代码:
from django import template
register = template.Library()
register = template.Library()
2. 定义过滤器函数
自定义的过滤器就是一个带1,2个参数的python函数,一个参数放变量值,一个用来放选项值。
比如{{ var|remove:"bar" }}, var是变量值,"bar"是选项值,remove过滤器可以定义为:
def remove(var, arg):
#移除字符串中var的arg字串
return var.replace(arg, '')
#移除字符串中var的arg字串
return var.replace(arg, '')
过滤器函数应该总是返回一些信息,即使出错,也不应该抛出异常,可以返回默认值或者空字符串。
不带参数的过滤器也很常见:
def lower(value):
"Converts a string into all lowercase"
return value.lower()
"Converts a string into all lowercase"
return value.lower()
3. 注册过滤器函数
#第一个参数是在模板中使用的过滤器的名字
#第二个就是你的过滤器函数引用名
register.filter('remove', remove)
register.filter('lower', lower)
#第二个就是你的过滤器函数引用名
register.filter('remove', remove)
register.filter('lower', lower)
python2.4以上版本,可以使用装饰符(decorator)功能
@register.filter(name='remove')
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
如果装饰符不加name,则默认使用函数名来当作使用名。
下面是完整代码:
from django import template
register = template.Library()
@register.filter(name='remove')
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
register = template.Library()
@register.filter(name='remove')
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
实现自定义tag
过程比实现过滤器要复杂,首先回顾一下模板系统的工作流程:
1. 编译生成模板对象
2. 模板对象使用上下文对象,渲染生成HTML内容
如果你要实现自己的tag,就需要告诉Django怎样对你的tag进行上面的两个步骤。
了解模板编译过程
当Django编译一个模板时,它把原始的模板文件中的内容变成一个个节点,每一个节点
是django.template.Node的实例,节点都有一个render()函数。因此,一个编译过的
模板对象可以看成是一个结点对象的列表。例如,模板文件内容:
Hello, {{ person.name }}.
{% ifequal name.birthday today %}
Happy birthday!
{% else %}
Be sure to come back on your birthday
for a splendid surprise message.
{% endifequal %}
{% ifequal name.birthday today %}
Happy birthday!
{% else %}
Be sure to come back on your birthday
for a splendid surprise message.
{% endifequal %}
被编译后的Node列表:
- Text node: "Hello, "
- Variable node: person.name
- Text node: ".\n\n"
- IfEqual node: name.birthday and today
当你调用模板对象的render()方法时,它会去调用Node列表上的每一个Node的render方法。最
后输出的结果就是所有render方法的输出结果的合并。所以要创建你自己的tag,需要实现你自己的
Node类,实现你自己的render方法。
创建tag实战
下面我们来实现一个tag,调用方法为:
{% current_time "%Y-%m-%D %I:%M %p" %}
功能是按照给定格式,显示当前时间,这个格式字符串和time.strftime()中定义的格式一样
这里是为了演示一下,格式内容可以参考http://docs.python.org/library/time.html#l2h-1941,
这个标签也支持不需要参数的默认显示。
1. 定义Node节点类,实现render方法
import datetime
from django import template
#这一句还是要的
register = template.Library()
class CurrentTimeNode(template.Node):
def __init__(self, format_string):
self.format_string = str(format_string)
def render(self, context):
now = datetime.datetime.now()
#返回的是格式化后的时间表示字符串
return now.strftime(self.format_string)
from django import template
#这一句还是要的
register = template.Library()
class CurrentTimeNode(template.Node):
def __init__(self, format_string):
self.format_string = str(format_string)
def render(self, context):
now = datetime.datetime.now()
#返回的是格式化后的时间表示字符串
return now.strftime(self.format_string)
render函数一定返回的是字符串,即使是空字符串
2. 创建Compilation函数
这个函数主要用于获取模板中的参数,并创建相应的Node类对象
def do_current_time(parser, token):
try:
tag_name, format_string = token.split_contents()
except ValueError:
msg = '%r tag requires a single argument' % token.split_contents()[0]
raise template.TemplateSyntaxError(msg)
return CurrentTimeNode(format_string[1:-1])
每一个tag的编译函数都需要两个参数parser和token:try:
tag_name, format_string = token.split_contents()
except ValueError:
msg = '%r tag requires a single argument' % token.split_contents()[0]
raise template.TemplateSyntaxError(msg)
return CurrentTimeNode(format_string[1:-1])
parser是模板分析对象
token是被parser分析后的内容,可以直接使用
token.contents 是tag的内容,这里token的值是'current_time "%Y-%m-%d %I:%M %p"'
token.split_contents 按空格分割字符串,返回tuple,但保留引号之单位的内容,这里得到
('current_time', '%Y-%m-%d %I:%M %p')
和实现filter不一样,如果tag运行出错,一定要抛出TemplateSyntaxError,返回一些有用的信息。
不要硬编码你的tag名,使用token.split_contents()[0]可以得到它。
编译函数总是返回一个Node子类实例,返回其它类型会报错。
3. 注册tag
register.tag('current_time', do_current_time)
和注册filter类似,两个参数,一个是使用名,一个是对应的函数引用名
python2.4版本以上,也可以使用装饰符功能
@register.tag(name="current_time")
def do_current_time(parser, token):
# ...
@register.tag
def shout(parser, token):
# ...
不用名字,表示默认使用函数名def do_current_time(parser, token):
# ...
@register.tag
def shout(parser, token):
# ...
完整代码为:
from django import template
import datetime
register = template.Library()
@register.filter(name='remove')
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
class CurrentTimeNode(template.Node):
def __init__(self, format_string):
self.format_string = str(format_string)
def render(self, context):
now = datetime.datetime.now()
return now.strftime(self.format_string)
def do_current_time(parser, token):
try:
tag_name, format_string = token.split_contents()
except ValueError:
msg = '%r tag requires a single argument' % token.split_contents()[0]
raise template.TemplateSyntaxError(msg)
return CurrentTimeNode(format_string[1:-1])
register.tag('current_time', do_current_time)
import datetime
register = template.Library()
@register.filter(name='remove')
def remove(value, arg):
return value.replace(arg, '')
@register.filter
def lower(value):
return value.lower()
class CurrentTimeNode(template.Node):
def __init__(self, format_string):
self.format_string = str(format_string)
def render(self, context):
now = datetime.datetime.now()
return now.strftime(self.format_string)
def do_current_time(parser, token):
try:
tag_name, format_string = token.split_contents()
except ValueError:
msg = '%r tag requires a single argument' % token.split_contents()[0]
raise template.TemplateSyntaxError(msg)
return CurrentTimeNode(format_string[1:-1])
register.tag('current_time', do_current_time)
4. 运行
在模板文件中添加:

访问页面:

复杂的实现自定义tag的其他几种方法
1. 在Node类的render函数中设置context
def render(self, context):
now = datetime.datetime.now()
#设置context对象的值
context['current_time'] = now.strftime(self.format_string)
# render函数一定要返回字符串,即使是空串
return ''
now = datetime.datetime.now()
#设置context对象的值
context['current_time'] = now.strftime(self.format_string)
# render函数一定要返回字符串,即使是空串
return ''
这样调用的时候,就是如下用法:
{% current_time "%Y-%M-%d %I:%M %p" %}
<p>The time is {{ current_time }}.</p>
<p>The time is {{ current_time }}.</p>
但这样做一个不好的地方就是,current_time变量名是硬编码,可能会覆盖相同名字的值。
重新设计一个tag的使用格式,如:
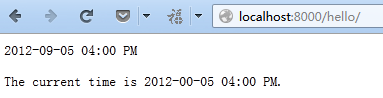
{% get_current_time "%Y-%M-%d %I:%M %p" as my_current_time %}
<p>The current time is {{ my_current_time }}.</p>
<p>The current time is {{ my_current_time }}.</p>
这样就需要修改一下编译函数,Node类和注册代码,代码如下:
import re
class CurrentTimeNode3(template.Node):
def __init__(self, format_string, var_name):
#增加自定义变量名的参数
self.format_string = str(format_string)
self.var_name = var_name
def render(self, context):
now = datetime.datetime.now()
context[self.var_name] = now.strftime(self.format_string)
return ''
def do_current_time(parser, token):
#使用正规表达式来处理token
try:
# 使用string.split(sep[, maxsplit]),1代表最大分割数,也就是
# 分割后会产生maxsplit+1个元素
# 这里分割后的结果为(get_current_time, '"%Y-%M-%d %I:%M %p" as my_current_time')
tag_name, arg = token.contents.split(None, 1)
except ValueError:
msg = '%r tag requires arguments' % token.contents.split_contents()[0]
raise template.TemplateSyntaxError(msg)
#使用()代表正则组,匹配as两边的字符串
m = re.search(r'(.*?) as (\w+)', arg)
if m:
fmt, var_name = m.groups()
else:
msg = '%r tag had invalid arguments' % tag_name
raise template.TemplateSyntaxError(msg)
#如果格式没被引号引用,报错
if not (fmt[0] == fmt[-1] and fmt[0] in ('"', "'")):
msg = "%r tag's argument should be in quotes" % tag_name
raise template.TemplateSyntaxError(msg)
# [1:-1]去除格式两边的引号
return CurrentTimeNode3(fmt[1:-1], var_name)
register.tag('get_current_time', do_current_time)
class CurrentTimeNode3(template.Node):
def __init__(self, format_string, var_name):
#增加自定义变量名的参数
self.format_string = str(format_string)
self.var_name = var_name
def render(self, context):
now = datetime.datetime.now()
context[self.var_name] = now.strftime(self.format_string)
return ''
def do_current_time(parser, token):
#使用正规表达式来处理token
try:
# 使用string.split(sep[, maxsplit]),1代表最大分割数,也就是
# 分割后会产生maxsplit+1个元素
# 这里分割后的结果为(get_current_time, '"%Y-%M-%d %I:%M %p" as my_current_time')
tag_name, arg = token.contents.split(None, 1)
except ValueError:
msg = '%r tag requires arguments' % token.contents.split_contents()[0]
raise template.TemplateSyntaxError(msg)
#使用()代表正则组,匹配as两边的字符串
m = re.search(r'(.*?) as (\w+)', arg)
if m:
fmt, var_name = m.groups()
else:
msg = '%r tag had invalid arguments' % tag_name
raise template.TemplateSyntaxError(msg)
#如果格式没被引号引用,报错
if not (fmt[0] == fmt[-1] and fmt[0] in ('"', "'")):
msg = "%r tag's argument should be in quotes" % tag_name
raise template.TemplateSyntaxError(msg)
# [1:-1]去除格式两边的引号
return CurrentTimeNode3(fmt[1:-1], var_name)
register.tag('get_current_time', do_current_time)
运行结果:
2. 实现块作用区域的tag
如{% if %}...{% endif %},需要在你的编译函数中使用parse.parse()
例如我们想要实现{% comment %}...{% endcomment %},功能是
忽略中tag中间的所有内容。
def do_comment(parser, token):
nodelist = parser.parse(('endcomment',))
parser.delete_first_token()
return CommentNode()
class CommentNode(template.Node):
def render(self, context):
return ''
nodelist = parser.parse(('endcomment',))
parser.delete_first_token()
return CommentNode()
class CommentNode(template.Node):
def render(self, context):
return ''
parse.parse()的参数是一个包含多个tag名的元组,返回的是它遇到元组中任何一个
tag名之前的所有Node对象列表,所以这里的nodelist包含{% comment %}和
{% endcomment %}之间的所有node对象,并且不包含它们自身两个node对象。
parser.delete_first_token():因为执行完parse.parse()之后,{% endcomment %}
tag还在,所以需要显示调用一次,防止这个tag被处理两次。
3. 在块作用tag中保留context内容
代码如下
{% upper %}
This will appear in uppercase, {{ user_name }}.
{% endupper %}
This will appear in uppercase, {{ user_name }}.
{% endupper %}
这里需要context中的user_name参数,怎么才能在处理tag的时候,不丢失context信息呢?
def do_upper(parser, token):
nodelist = parser.parse(('endupper',))
parser.delete_first_token()
return UpperNode(nodelist)
class UpperNode(template.Node):
def __init__(self, nodelist):
self.nodelist = nodelist
def render(self, context):
output = self.nodelist.render(context)
return output.upper()
nodelist = parser.parse(('endupper',))
parser.delete_first_token()
return UpperNode(nodelist)
class UpperNode(template.Node):
def __init__(self, nodelist):
self.nodelist = nodelist
def render(self, context):
output = self.nodelist.render(context)
return output.upper()
只需要保留下nodelist,然后调用self.nodelist.render(contest),就可以间接调用每一个Node
的render函数。
有更多的例子,可以查看Django源代码,位置为:
D:\Python27\Lib\site-packages\django\template\defaulttags.py
4. 快速创建简单tag的方法
简单tag的定义,只带一个参数,返回经过处理的字符串,像之前的current_time标签一样。
Django提供了一种simple_tag方法来快速创建类似这样的tag。
def current_time(format_string):
try:
return datetime.datetime.now().strftime(str(format_string))
except UnicodeEncodeError:
return ''
register.simple_tag(current_time)
try:
return datetime.datetime.now().strftime(str(format_string))
except UnicodeEncodeError:
return ''
register.simple_tag(current_time)
simple_tag参数为一个函数引用,会把它包装进render函数中,然后再进行注册。也不用定义
Node子类了。
python2.4以上,可以使用装饰符
@register.simple_tag
def current_time(token):
# ...
def current_time(token):
# ...
5. 创建Inclusion Tag
另外一种比较普遍的tag类型是只是渲染其它模块显示下内容,这样的类型叫做Inclusion Tag。
例如,实现以下tag:
{% books_for_author author %}
渲染结果为:
<ul>
<li>The Cat In The Hat</li>
<li>Hop On Pop</li>
<li>Green Eggs And Ham</li>
</ul>
<li>The Cat In The Hat</li>
<li>Hop On Pop</li>
<li>Green Eggs And Ham</li>
</ul>
列出某个作者所有的书。
- 定义函数
def books_for_author(author):
books = Book.objects.filter(authors__id=author.id)
return {'books': books}
books = Book.objects.filter(authors__id=author.id)
return {'books': books}
- 创建另一个模板文件book_snippet.html
<ul>
{% for book in books %}
<li>{{ book.title }}</li>
{% endfor %}
</ul>
{% for book in books %}
<li>{{ book.title }}</li>
{% endfor %}
</ul>
- 注册tag
register.inclusion_tag('book_snippet.html')(books_for_author)
有些你的模板可以使用父模板的context内容,Django提供一个takes_context参数来实现,
使用之后,tag不能再带参数,
@register.inclusion_tag('link.html', takes_context=True)
def jump_link(context):
return {
'link': context['home_link'],
'title': context['home_title'],
}
模板文件link.html为def jump_link(context):
return {
'link': context['home_link'],
'title': context['home_title'],
}
Jump directly to <a href="{{ link }}">{{ title }}</a>.
使用方法:
{% jump_link %}
创建自定义模板加载类
可以自定其它的加载行为,比如从数据库中加载,从svn中加载,从zip中加载等。
需要实现一个接口load_template_source(template_name, template_dirs=None):
template_name就是类似'link.html'这样的模板名称
template_dirs是一个可选的路径列表,为空就使用TEMPLATE_DIRS属性定义的路径。
如果一个加载器加载模板成功,它将返回一个元组(template_source, template_path)。
template_source:模板文件的内容字符中,会用于被编译
template_path:模板文件的路径
如果加载失败,报错django.template.TemplateDoesNotExist
每一个加载函数都需要有一个is_usable的函数属性,对,是函数的属性,因为在python中,
函数也是个对象。这个属性告诉模板引擎在当前的python环境下这个加载器是否可用。
例如,之前的eggs加载器是默认关闭的,is_usable=False,因为需要pkg_resources模块
中的从egg中读取信息的功能。不一定每个用户会安装,如果安装了,就可以设置为True,开启
功能。
下面实现一个从zip文件中加载模板的自定义加载器,它使用TEMPLATE_ZIP_FILES作为搜索路径,来
代替系统的TEMPLATE_DIRS,路径上都是zip文件名。
from django.conf import settings
from django.template import TemplateDoesNotExist
import zipfile
def load_template_source(template_name, template_dirs=None):
"Template loader that loads templates from a ZIP file."
#从settings.py配置文件中读取属性TEMPLATE_ZIP_FILES的值,默认返回空列表
template_zipfiles = getattr(settings, "TEMPLATE_ZIP_FILES", [])
# Try each ZIP file in TEMPLATE_ZIP_FILES.
for fname in template_zipfiles:
try:
z = zipfile.ZipFile(fname)
source = z.read(template_name)
except (IOError, KeyError):
continue
z.close()
# 找到一个可用的文件就返回
template_path = "%s:%s" % (fname, template_name)
return (source, template_path)
# 如果一个zip文件没找到,报错
raise TemplateDoesNotExist(template_name)
# 设置为可用
load_template_source.is_usable = True
from django.template import TemplateDoesNotExist
import zipfile
def load_template_source(template_name, template_dirs=None):
"Template loader that loads templates from a ZIP file."
#从settings.py配置文件中读取属性TEMPLATE_ZIP_FILES的值,默认返回空列表
template_zipfiles = getattr(settings, "TEMPLATE_ZIP_FILES", [])
# Try each ZIP file in TEMPLATE_ZIP_FILES.
for fname in template_zipfiles:
try:
z = zipfile.ZipFile(fname)
source = z.read(template_name)
except (IOError, KeyError):
continue
z.close()
# 找到一个可用的文件就返回
template_path = "%s:%s" % (fname, template_name)
return (source, template_path)
# 如果一个zip文件没找到,报错
raise TemplateDoesNotExist(template_name)
# 设置为可用
load_template_source.is_usable = True
保存为zip_loader.py,放在app目录下,剩下我们需要做的是,在TEMPLATE_LOADERS属性
中注册你的加载器:
TEMPLATE_LOADERS = (
'books.zip_loader.load_template_source',
)
'books.zip_loader.load_template_source',
)
作者:btchenguang
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

