
一文看懂迁移学习:怎样用预训练模型搞定深度学习? ——重用神经网络的结构


以上示例都是人类的迁移学习的能力。
迁移学习是什么?
所谓迁移学习,或者领域适应Domain Adaptation,一般就是要将从源领域(Source Domain)学习到的东西应用到目标领域(Target Domain)上去。源领域和目标领域之间往往有gap/domain discrepancy(源领域的数据和目标领域的数据遵循不同的分布)。
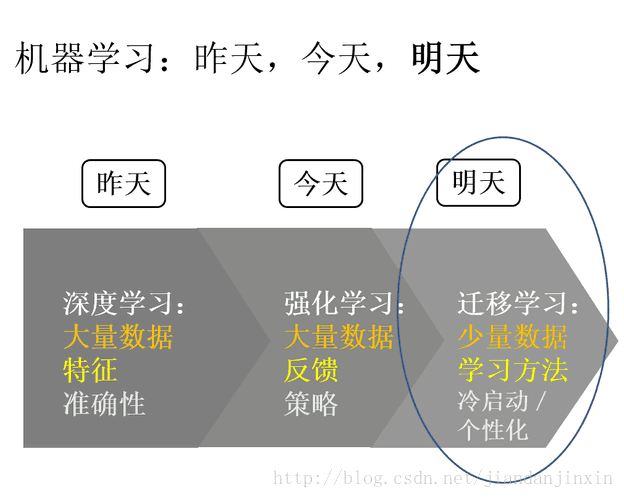
迁移学习能够将适用于大数据的模型迁移到小数据上,实现个性化迁移。
迁移什么,怎么迁移,什么时候能迁移,这是迁移学习要解决的主要问题。
迁移学习能解决那些问题?
小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。
迁移学习四种实现方法
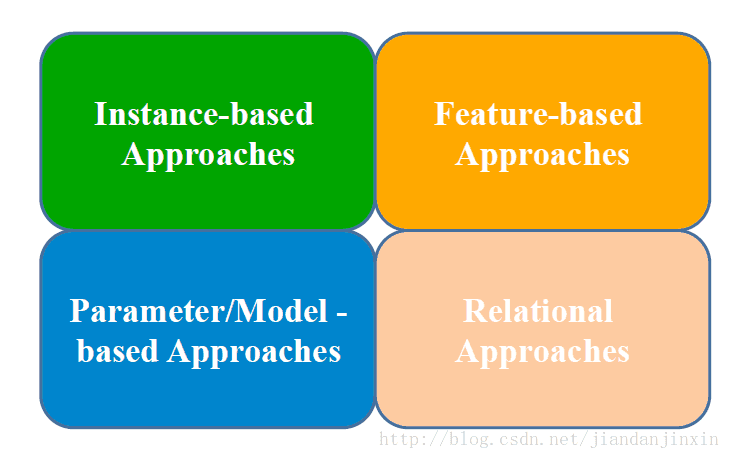
1. 样本迁移 Instance-based Transfer Learning

一般是对样本进行加权,给比较重要的样本较大的权重。
样本迁移即在数据集(源领域)中找到与目标领域相似的数据,把这个数据放大多倍,与目标领域的数据进行匹配。其特点是:需要对不同例子加权;需要用数据进行训练。
2. 特征迁移 Feature-based Transfer Learning

在特征空间进行迁移,一般需要把源领域和目标领域的特征投影到同一个特征空间里进行。
特征迁移是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征间进行自动迁移。
3. 模型迁移 Model-based Transfer Learning
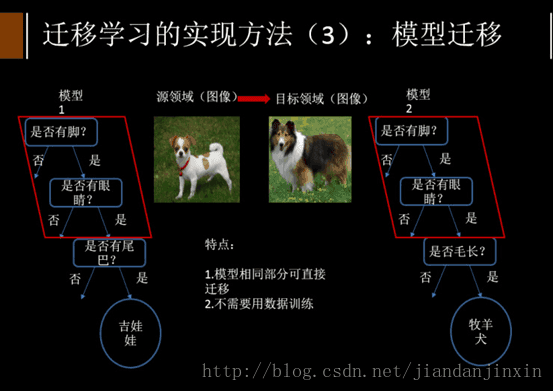
整个模型应用到目标领域去,比如目前常用的对预训练好的深度网络做微调,也可以叫做参数迁移。
模型迁移利用上千万的图象训练一个图象识别的系统,当我们遇到一个新的图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些
4. 关系迁移 Relational Transfer Learning
社会网络,社交网络之间的迁移。

前沿的迁移学习方向
Reinforcement Transfer Learning
怎么迁移智能体学习到的知识:比如我学会了一个游戏,那么我在另一个相似的游戏里面也是可以应用一些类似的策略的
Transitive Transfer Learning
传递性迁移学习,两个domain之间如果相隔得太远,那么我们就插入一些intermediate domains,一步步做迁移
Source-Free Transfer Learning
不知道是哪个源领域
最后用一张图总结一下深度学习、强化学习、迁移学习的趋势
参考资料:
https://mp.weixin.qq.com/s?__biz=MzAwMjM2Njg2Nw==&mid=2653144126&idx=1&sn=d9633d71ed89590100422c85f6bdb845
http://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651982064&idx=1&sn=92e65d423db5aa79d8c8c782afc19111&scene=1&srcid=0426Sj6blqQWPuyUb8qCswf3&from=singlemessage&isappinstalled=0#wechat_redirect
http://geek.csdn.net/news/detail/92051
http://www.leiphone.com/news/201612/hF1AX5yNwcxtf005.html
https://zhuanlan.zhihu.com/p/22023097
下面就是深度学习模型重用例子。迁移学习!
跟传统的监督式机器学习算法相比,深度神经网络目前最大的劣势是什么?
贵。
尤其是当我们在尝试处理现实生活中诸如图像识别、声音辨识等实际问题的时候。一旦你的模型中包含一些隐藏层时,增添多一层隐藏层将会花费巨大的计算资源。
庆幸的是,有一种叫做“迁移学习”的方式,可以使我们在他人训练过的模型基础上进行小改动便可投入使用。在这篇文章中,我将会讲述如何使用预训练模型来加速解决问题的过程。
注:这篇文章默认读者对于神经网络和深度学习有着一定的了解,如果你不了解深度学习,那么我强烈建议你先了解一下深度学习的基础概念:
深度学习入门者必看:25个你一定要知道的概念
目录
1.什么是迁移学习?
2.什么是预训练模型?
3.为什么我们使用预训练模型?-结合生活实例
4.我们可以怎样运用预训练模型?
▪提取特征(extract features)
▪优化模型(fine tune the model)
5.优化模型的方式
6.在数字识别中使用预训练模型
▪只针对输出密集层(output dense layer)的重新训练
▪冻结初始几层网络的权重因子
1. 什么是迁移学习?
为了对迁移学习产生一个直观的认识,不妨拿老师与学生之间的关系做类比。
一位老师通常在ta所教授的领域有着多年丰富的经验,在这些积累的基础上,老师们能够在课堂上教授给学生们该领域最简明扼要的内容。这个过程可以看做是老手与新手之间的“信息迁移”。
这个过程在神经网络中也适用。
我们知道,神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。
现在,让我们从自身进化的角度来讨论这种迁移学习的重要性。这是Tim Urban最近在waitbutwhy.com上的一篇文章中提出的观点。
Tim说,在语言发明之前,每一代人类都需要自身重新习得很多知识,这也是知识从上一代到下一代一增长缓慢的原因。
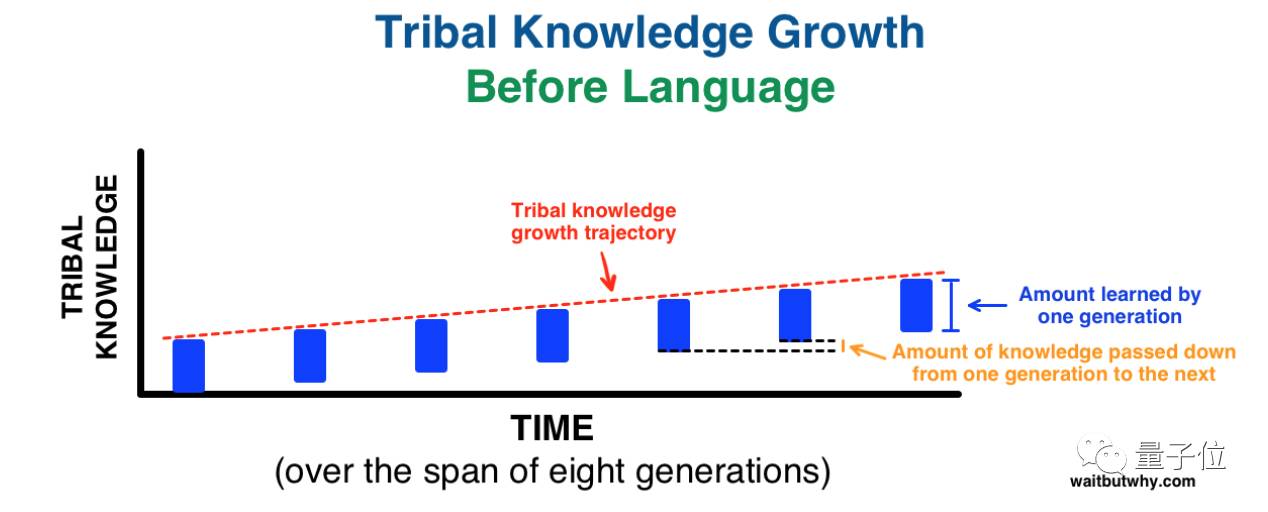
随后,我们发明了语言,这为知识在世代间的传递提供了载体,下图是在语言发明后,同样时间尺度下知识增长速度的示意图。

是不是看起来很牛逼?而通过权重的传递来进行迁移学习和人类在世代交替中通过语言传播知识,是一个道理。
2. 什么是预训练模型?
简单来说,预训练模型(pre-trained model)是前人为了解决类似问题所创造出来的模型。你在解决问题的时候,不用从零开始训练一个新模型,可以从在类似问题中训练过的模型入手。
比如说,如果你想做一辆自动驾驶汽车,可以花数年时间从零开始构建一个性能优良的图像识别算法,也可以从Google在ImageNet数据集上训练得到的inception model(一个预训练模型)起步,来识别图像。
一个预训练模型可能对于你的应用中并不是100%的准确对口,但是它可以为你节省大量功夫。
接下来,我会举个例子来说明。
3. 为什么我们要用预训练模型?
上周我一直在尝试解决Crowdanalytix platform上的一个问题:从手机图片中分辨场景。
这是一个图像分类的问题,训练数据集中有4591张图片,测试集中有1200张图片。我们的任务是将图片相应地分到16个类别中。在对图片进行一些预处理后,我首先采用一个简单的MLP(Multi-later Perceptron)模型,结构如下图所示:
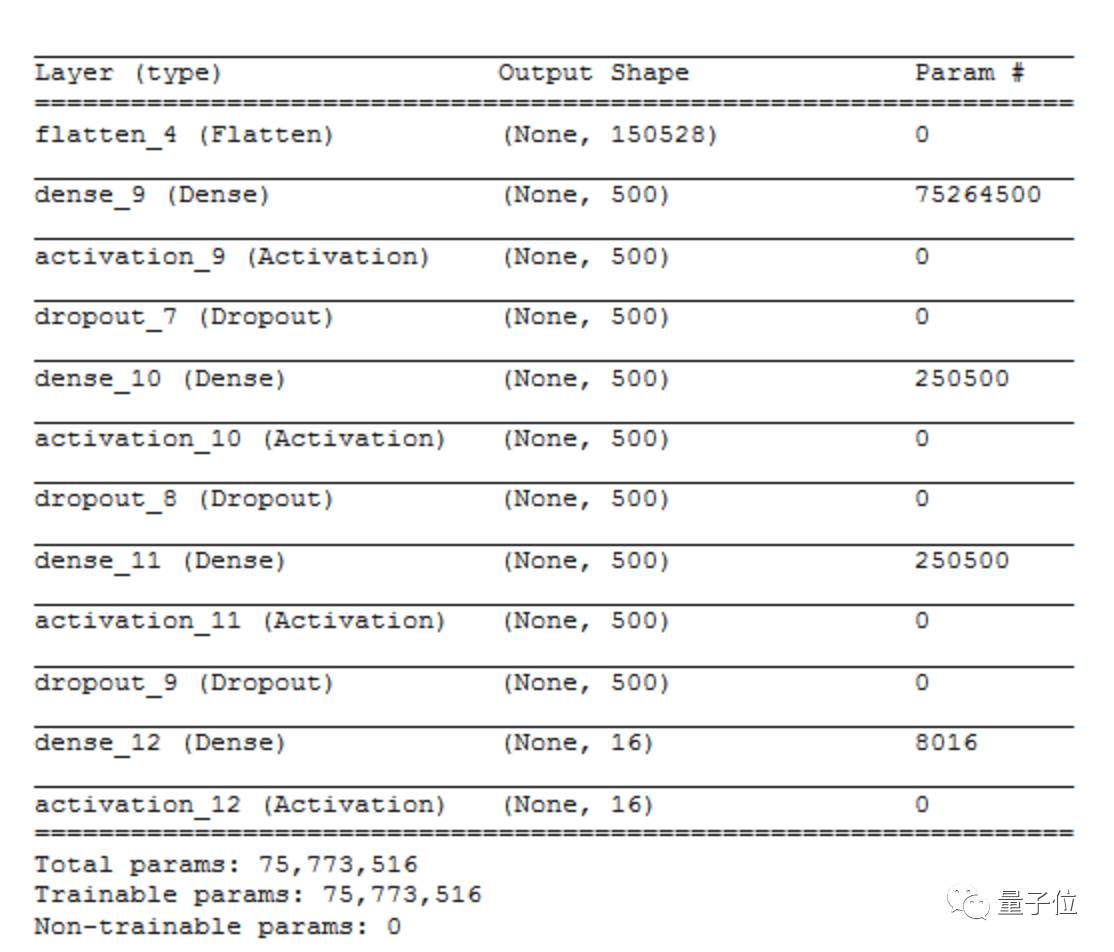
在对输入图片(224*224*3)平整化后,为了简化上述结构,我用了三个各含有500个神经元的隐藏层。在输出层中,共有16个神经元对应着十六个类别。
我只能将训练的准确率控制在6.8%,这是个很不理想的结果。我尝试对隐藏层、隐层中神经元的数量以及drop out速率进行调整,但准确度都没有太大的提升。而如果增加隐藏层和其中神经元的数量,每个周期的运行时间则会增加20s以上。(我的开发环境是12GB VRAM,Titan X GPU)
下面是我用上文所述结构的MLP模型训练输出的结果。

可以看出,除非指数级地增加训练时长,MLP模型无法提供给我更好的结果。因此,我转而采用CNN(卷积神经网络),看看他们在这个数据集上的表现,以及是否能够提高训练的准确度。
CNN的结构如下:

我使用了3个卷积的模块,每个模块由以下部分组成:
-
32个5*5的filter
-
线性整流函数(ReLU)作为激活函数
-
4*4的最大值池化层
最后一个卷积模块输出的结果经过平整化后会被传递到一个拥有64的神经元的隐藏层上,随后通过一个drop out rate = 0.5处理后传递到输出层。
最终训练的结果记录如下:
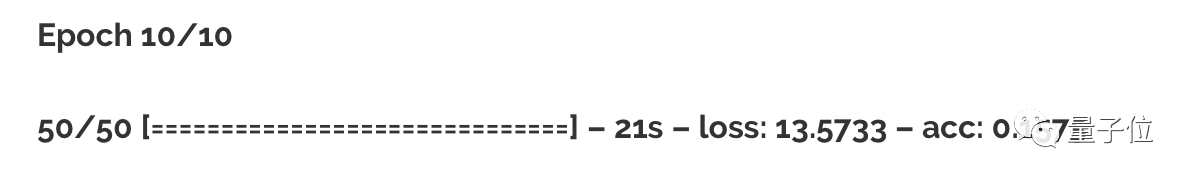
准确率15.75%,尽管与MLP模型相比有所提升,但每个周期的运行时间也增加了。
而更重要的是,数据集中最大类别所含图片数量约占总数17.6%左右。
只要把所有的图片都归到最大的类别,我们就能够得到比MLP、CNN训练出来的模型更好的结果(ノへ ̄、)。
此外,增加更多的卷积模块也会大大增加训练时长。
于是,我转而去采用预训练模型,这样我不需要重新训练我的整个结构,只需要针对其中的几层进行训练即可。
因此,我采用了在ImageNet数据集上预先训练好的VGG16模型,这个模型可以在Keras库中找到。
模型的结构如下所示:

在VGG16结构的基础上,我只将softmax层的1000个输出改为16个,从而适应我们这个问题的情景,随后重新训练了dense layer。
跟MLP和CNN相比,这个结构的准确率能够达到70%。同时,使用VGG16最大的好处是大大减少了训练时间,只需要针对dense layer进行训练,所需时间基本可以忽略。
4.怎样使用预训练模型?
当在训练经网络的时候我们的目标是什么?我们希望网络能够在多次正向反向迭代的过程中,找到合适的权重。
通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上。这被称作是“迁移学习”,即将预训练的模型“迁移”到我们正在应对的特定问题中。
在选择预训练模型的时候你需要非常仔细,如果你的问题与预训练模型训练情景下有很大的出入,那么模型所得到的预测结果将会非常不准确。
举例来说,如果把一个原本用于语音识别的模型用来做用户识别,那结果肯定是不理想的。
幸运的是,Keras库中有许多这类预训练的结构。
ImageNet数据集已经被广泛用作训练集,因为它规模足够大(包括120万张图片),有助于训练普适模型。ImageNet的训练目标,是将所有的图片正确地划分到1000个分类条目下。这1000个分类基本上都来源于我们的日常生活,比如说猫猫狗狗的种类,各种家庭用品,日常通勤工具等等。
在迁移学习中,这些预训练的网络对于ImageNet数据集外的图片也表现出了很好的泛化性能。
既然预训练模型已经训练得很好,我们就不会在短时间内去修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(fine tune)。
在修改模型的过程中,我们通过会采用比一般训练模型更低的学习速率。
5. 微调模型的方法
特征提取
我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
采用预训练模型的结构
我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
训练特定层,冻结其他层
另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用与训练模型,是由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的。
下图表展示了在各种情况下应该如何使用预训练模型:
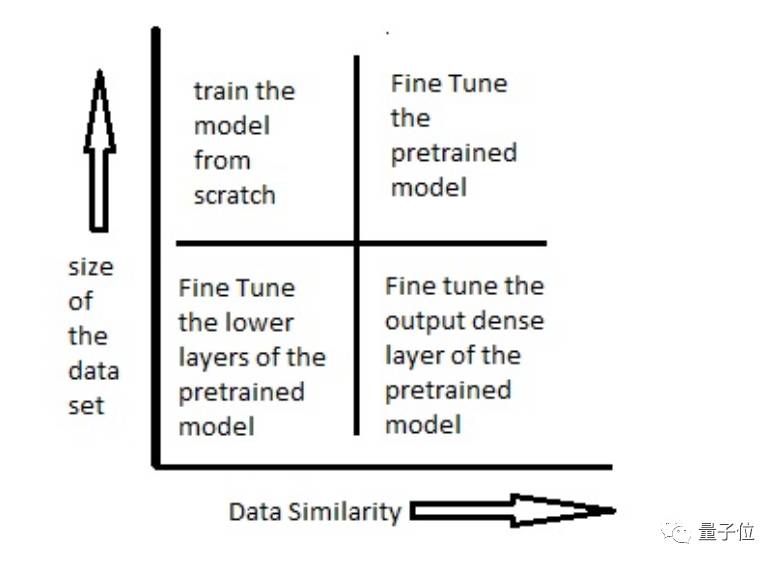
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。
我们使用预处理模型作为模式提取器。
比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。
在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。
因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。
因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
6. 在手写数字识别中使用预训练模型
现在,让我们尝试来用预训练模型去解决一个简单的问题。
我曾经使用vgg16作为预训练的模型结构,并把它应用到手写数字识别上。
让我们先来看看这个问题对应着之前四种场景中的哪一种。我们的训练集(MNIST)有大约60,000张左右的手写数字图片,这样的数据集显然是偏小的。所以这个问题应该属于场景一或场景二。
我们可以尝试把两种对应的方法都用一下,看看最终的效果。
只重新训练输出层 & dense layer
这里我们采用vgg16作为特征提取器。随后这些特征,会被传递到依据我们数据集训练的dense layer上。输出层同样由与我们问题相对应的softmax层函数所取代。
在vgg16中,输出层是一个拥有1000个类别的softmax层。我们把这层去掉,换上一层只有10个类别的softmax层。我们只训练这些层,然后就进行数字识别的尝试。
# importing required librariesfromkeras.models importSequential fromscipy.miscimportimreadget_ipython().magic( 'matplotlib inline') importmatplotlib.pyplot aspltimportnumpy asnp importkeras fromkeras.layers importDense importpandas aspdfromkeras.applications.vgg16 importVGG16 fromkeras.preprocessing importimagefromkeras.applications.vgg16 importpreprocess_input importnumpy asnpfromkeras.applications.vgg16 importdecode_predictionstrain=pd.read_csv("R/Data/Train/train.csv")test=pd.read_csv( "R/Data/test.csv")train_path="R/Data/Train/Images/train/"test_path= "R/Data/Train/Images/test/"fromscipy.miscimportimresize # preparing the train datasettrain_img=[] fori inrange(len(train)): temp_img=image.load_img(train_path+train[ 'filename'][i],target_size=( 224, 224)) temp_img=image.img_to_array(temp_img) train_img.append(temp_img) #converting train images to array and applying mean subtraction processingtrain_img=np.array(train_img) train_img=preprocess_input(train_img) # applying the same procedure with the test datasettest_img=[] fori inrange(len(test)): temp_img=image.load_img(test_path+test['filename'][i],target_size=( 224, 224)) temp_img=image.img_to_array(temp_img) test_img.append(temp_img)test_img=np.array(test_img) test_img=preprocess_input(test_img) # loading VGG16 model weightsmodel = VGG16(weights= 'imagenet', include_top= False) # Extracting features from the train dataset using the VGG16 pre-trained modelfeatures_train=model.predict(train_img) # Extracting features from the train dataset using the VGG16 pre-trained modelfeatures_test=model.predict(test_img) # flattening the layers to conform to MLP inputtrain_x=features_train.reshape( 49000, 25088) # converting target variable to arraytrain_y=np.asarray(train[ 'label']) # performing one-hot encoding for the target variabletrain_y=pd.get_dummies(train_y)train_y=np.array(train_y) # creating training and validation setfromsklearn.model_selection importtrain_test_splitX_train, X_valid, Y_train, Y_valid=train_test_split(train_x,train_y,test_size= 0.3, random_state= 42) # creating a mlp modelfromkeras.layers importDense, Activationmodel=Sequential()model.add(Dense(1000, input_dim= 25088, activation= 'relu',kernel_initializer='uniform'))keras.layers.core.Dropout( 0.3, noise_shape= None, seed=None)model.add(Dense( 500,input_dim= 1000,activation='sigmoid'))keras.layers.core.Dropout( 0.4, noise_shape= None, seed=None)model.add(Dense( 150,input_dim= 500,activation='sigmoid'))keras.layers.core.Dropout( 0.2, noise_shape= None, seed=None)model.add(Dense(units= 10))model.add(Activation( 'softmax'))model.compile(loss='categorical_crossentropy', optimizer= "adam", metrics=[ 'accuracy']) # fitting the modelmodel.fit(X_train, Y_train, epochs= 20, batch_size= 128,validation_data=(X_valid,Y_valid))
冻结最初几层网络的权重
这里我们将会把vgg16网络的前8层进行冻结,然后对后面的网络重新进行训练。这么做是因为最初的几层网络捕获的是曲线、边缘这种普遍的特征,这跟我们的问题是相关的。我们想要保证这些权重不变,让网络在学习过程中重点关注这个数据集特有的一些特征,从而对后面的网络进行调整。
fromkeras.models importSequential fromscipy.misc importimreadget_ipython().magic('matplotlib inline') importmatplotlib.pyplot asplt importnumpy asnp importkerasfromkeras.layers importDense importpandas aspd fromkeras.applications.vgg16importVGG16 fromkeras.preprocessing importimage fromkeras.applications.vgg16importpreprocess_input importnumpy asnp fromkeras.applications.vgg16importdecode_predictions fromkeras.utils.np_utils importto_categoricalfromsklearn.preprocessing importLabelEncoder fromkeras.models importSequentialfromkeras.optimizers importSGD fromkeras.layers importInput, Dense, Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D, Dropout, Flatten, merge, Reshape, Activation fromsklearn.metrics importlog_losstrain=pd.read_csv("R/Data/Train/train.csv")test=pd.read_csv( "R/Data/test.csv")train_path="R/Data/Train/Images/train/"test_path= "R/Data/Train/Images/test/"fromscipy.miscimportimresizetrain_img=[] fori inrange(len(train)): temp_img=image.load_img(train_path+train[ 'filename'][i],target_size=( 224, 224)) temp_img=image.img_to_array(temp_img) train_img.append(temp_img)train_img=np.array(train_img) train_img=preprocess_input(train_img)test_img=[] foriinrange(len(test)):temp_img=image.load_img(test_path+test[ 'filename'][i],target_size=(224, 224)) temp_img=image.img_to_array(temp_img) test_img.append(temp_img)test_img=np.array(test_img) test_img=preprocess_input(test_img) fromkeras.models importModeldefvgg16_model(img_rows, img_cols, channel=1, num_classes=None):model = VGG16(weights= 'imagenet', include_top= True) model.layers.pop() model.outputs = [model.layers[- 1].output] model.layers[- 1].outbound_nodes = [] x=Dense(num_classes, activation= 'softmax')(model.output) model=Model(model.input,x) #To set the first 8 layers to non-trainable (weights will not be updated)forlayer inmodel.layers[: 8]: layer.trainable =False# Learning rate is changed to 0.001sgd = SGD(lr= 1e-3, decay= 1e-6, momentum=0.9, nesterov= True) model.compile(optimizer=sgd, loss= 'categorical_crossentropy', metrics=[ 'accuracy']) returnmodeltrain_y=np.asarray(train[ 'label'])le = LabelEncoder()train_y = le.fit_transform(train_y)train_y=to_categorical(train_y)train_y=np.array(train_y)fromsklearn.model_selection importtrain_test_splitX_train, X_valid, Y_train, Y_valid=train_test_split(train_img,train_y,test_size= 0.2, random_state= 42) # Example to fine-tune on 3000 samples from Cifar10img_rows, img_cols = 224, 224# Resolution of inputschannel = 3num_classes = 10batch_size = 16nb_epoch = 10# Load our modelmodel = vgg16_model(img_rows, img_cols, channel, num_classes)model.summary() # Start Fine-tuningmodel.fit(X_train, Y_train,batch_size=batch_size,epochs=nb_epoch,shuffle= True,verbose=1,validation_data=(X_valid, Y_valid)) # Make predictionspredictions_valid = model.predict(X_valid, batch_size=batch_size, verbose= 1) # Cross-entropy loss scorescore = log_loss(Y_valid, predictions_valid) 相关资源
原文:
https://www.analyticsvidhya.com/blog/2017/06/transfer-learning-the-art-of-fine-tuning-a-pre-trained-model/
VGG-16:
https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
Keras库中的ImageNet预训练模型:
https://keras.io/applications/
手写数字数据集MNIST:
http://yann.lecun.com/exdb/mnist/

