
迁移学习
1. 前言
迁移学习(Transfer Learning,TL)对于人类来说,就是掌握举一反三的学习能力。比如我们学会骑自行车后,学骑摩托车就很简单了;在学会打羽毛球之后,再学打网球也就没那么难了。对于计算机而言,所谓迁移学习,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术。
不久前,香港科技大学的杨强教授在机器之心GMIS大会中回顾AlphaGo和柯洁的围棋大战时曾说,AlphaGo 看上去像神一样的存在,好像是无懈可击,而我们如果从机器学习的角度来看,它还是有弱点的,而且这个弱点还很严重。这个弱点即,AlphaGo不像人类一样有迁移学习的能力。它不能在学会围棋后,迁移到拥有下象棋的能力,这一局限性需要迁移学习来攻破。另一位大牛吴恩达在NIPS 2016 tutorial中也曾表示非常看好迁移学习的应用前景。他认为迁移学习将是监督学习之后的,在ML的商业应用中得到成功的下一波动力。现实世界纷繁复杂,包含众多场景。迁移学习可以帮助我们透过现象抓住问题共性,巧妙处理新遇到的问题。
传统机器学习通常有两个基本假设,即训练样本与测试样本满足独立同分布的假设和必须有足够可利用的训练样本假设。然而,现实生活中这两个基本假设有时往往难以满足。比如,股票数据的时效性通常很强,利用上个月数据训练出来的模型,往往很难顺利地运用到下个月的预测中去;比如公司开设新业务,但愁于没有足够的数据建立模型进行用户推荐。近年来在机器学习领域受到广泛关注的迁移学习恰恰解决了这两个问题。迁移学习用已有的知识来解决目标领域中仅有少量有标签样本数据甚至没有数据的学习问题,从根本上放宽了传统机器学习的基本假设。由于被赋予了人类特有的举一反三的智慧,迁移学习能够将适用于大数据的模型迁移到小数据上,发现问题的共性,从而将通用的模型迁移到个性化的数据上,实现个性化迁移。
2. 迁移学习的一般化定义
- 条件:给定一个源域Ds和源域上的学习任务Ts,目标域Dt和目标域上的学习任务Tt
- 目标:用Ds和Ts学习目标域上的预测函数f(·)
- 限制条件:Ds≠Dt,Ts≠Tt
3 迁移学习的分类
3.1 按特征空间分
- 同构迁移学习(Homogeneous TL): 源域和目标域的特征空间相同,XS=XT
- 异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同,XS≠XT
3.2 按迁移情景分
- 归纳式迁移学习(Inductive TL):源域和目标域的学习任务不同
- 直推式迁移学习(Transductive TL):源域和目标域不同,学习任务相同
- 无监督迁移学习(Unsupervised TL):源域和目标域均没有标签
4. 迁移学习的基本方法
- 样本迁移(Instance based TL)
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配。下图的例子就是找到源域的例子3,然后加重该样本的权值,使得在预测目标域时的比重加大。优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。
- 特征迁移(Feature based TL)
假设源域和目标域含有一些共同的交叉特征,通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。
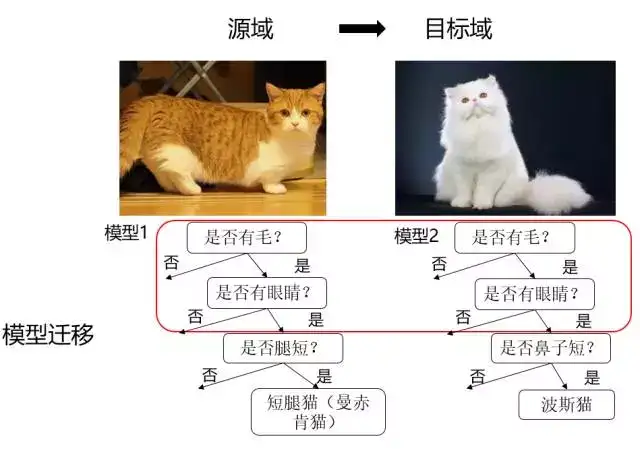
- 模型迁移(Parameter based TL)
假设源域和目标域共享模型参数,是指将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测,比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
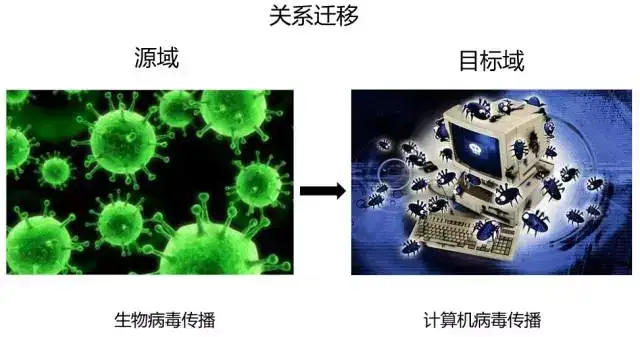
- 关系迁移(Relation based TL)
假设两个域是相似的,那么它们之间会共享某种相似关系,将源域中逻辑网络关系应用到目标域上来进行迁移,比方说生物病毒传播到计算机病毒传播的迁移。
5. 迁移学习的应用场景
5.1 迁移学习的理论研究价值
- 解决标注数据稀缺性
大数据时代亿万级别规模的数据导致数据的统计异构性、标注缺失问题越来越严重。标注数据缺失会导致传统监督学习出现严重过拟合问题。目前解决数据稀缺性的方法有传统半监督学习、协同训练、主动学习等,但这些方法都要求目标域中存在一定程度的标注数据,而在标注数据稀缺的时候额外获取人工标注数据的代价太大。这时需要迁移学习来辅助提高目标领域的学习效果。
- 非平稳泛化误差分享
经典统计学习理论给出了独立同分布条件下模型的泛化误差上界保证。而在非平稳环境(不同数据域不服从独立同分布假设)中,传统机器学习理论不再成立,这给异构数据分析挖掘带来了理论风险。从广义上看,迁移学习可以看做是传统机器学习在非平稳环境下的推广。因此在非平稳环境下,迁移学习是对经典机器学习的一个重要理论补充。
5.2 迁移学习的实际应用
- 训练机械臂
在真实的机器人上训练模型太慢,而且非常昂贵。解决办法是先进行模拟学习,将模拟学习学到的知识迁移到现实世界的机器人训练中,这里源域和目标域之间的特征空间是相同的。近年来该领域的研究又引发了许多人的兴趣。下图是谷歌DeepMind的工作:图左是在模拟环境下训练机械臂的移动,训练好之后,可以把知识迁移到现实世界的机械臂上,真实的机械臂稍加训练也可以达到非常好的效果,如下图右。
视频参见:https://www.youtube.com/watch?v=YZz5Io_ipi8

- 舆情分析
迁移学习也可应用在舆情分析中的用户评价上。以电子产品和视频游戏产品用户评价为例,图中绿色为好评标签,而红色为差评标签。从图左的电子产品评价(源域)中抽取特征,建立电子产品评价领域的模型,然后将其应用到右图的视频游戏领域(目标域)中,实现舆情大规模的迁移,并且在新的领域不需要标签。

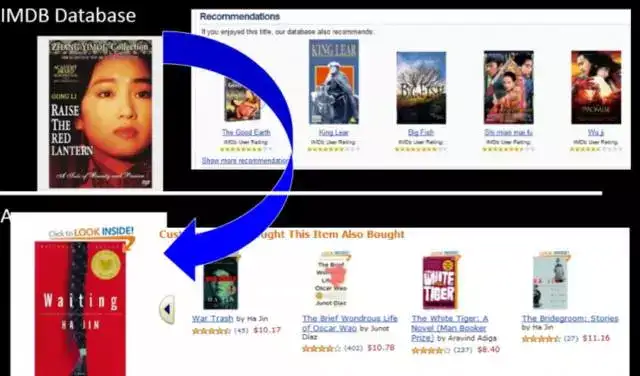
- 推荐系统
迁移学习也可以用在推荐系统中,在某个领域做好一个推荐系统,然后应用在稀疏的、新的垂直领域。比如已成熟完善的电影推荐系统可以应用在冷启动中的书籍推荐系统中。
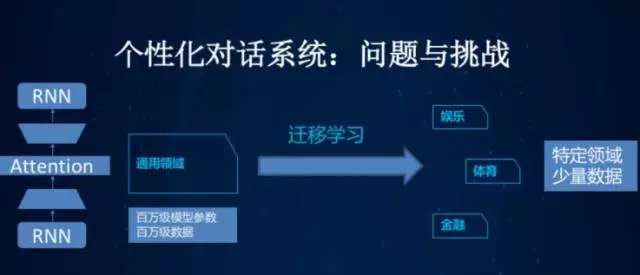
- 个性化对话
先训练一个通用型的对话系统,然后再根据特定领域的小数据修正它,使得这个对话系统适应该特定领域的任务。比如,一个用户想买咖啡,他并不想回答所有繁琐的问题,例如是问要大杯小杯,热的冷的?
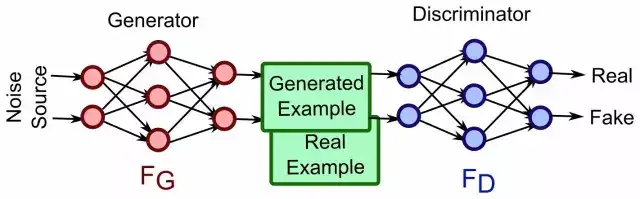
- 数据生成式的迁移学习-GAN
生成式对抗网络(GAN)是一个新的机器学习的思想。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声z生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D输出大概率,否则,D输出小概率。GAN的优化是一个极小极大博弈问题,最终的目的是generator的输出给discriminator时很难判断是真实or伪造的。
如果我们有一个很好的生成式模型,在某个数据集上已经训练好了,如果有一些新的数据,和前一个数据集有明显的区别,那么我们可以利用“GAN+边界条件”,把生成式模型迁移到新的数据分布上。比方说,我们写字的时候,每个人签名都是不同的,我们不会用印刷体来签名,因为我们每个人都有自己的写字的特点。那么,如果用大量的印刷体字作为第一部分的训练样本,来训练一个不错的通用模型,而用某个人手写的斜体字做第二部分的训练样本,就可以利用Wasserstein GAN把印刷体的模型迁移到个人的签名。也就是说,这样的签名也就更具个性化特点。
6. 迁移学习相关竞赛
- [Unsupervised and Transfer Learning Challenge] (http://www.causality.inf.ethz.ch/unsupervised-learning.php)
- [2007 IEEE ICDM Data Mining Contest Overview] (http://www.cse.ust.hk/~qyang/ICDMDMC07/)
7. 迁移学习代表性研究学者
开展迁移学习的研究可以从跟踪迁移学习代表性研究学者的成果着手。国内外迁移学习方面的代表人物有:
- 香港科技大学的杨强教授
- 第四范式的CEO [戴文渊] (https://scholar.google.com.sg/citations?user=AGR9pP0AAAAJ&hl=zh-CN)
- 南洋理工大学的助理教授[Sinno Jialin Pan] (http://www.ntu.edu.sg/home/sinnopan/)
- 中科院计算所副教授[庄福振] (http://www.intsci.ac.cn/users/zhuangfuzhen/)
8. 迁移学习工具包
- [Boosting for Transfer Learning] (http://www.cse.ust.hk/TL/code/C_TraDaBoost.rar), Wenyuan Dai,Qiang Yang, et al., C语言
- [Selective Transfer Between Learning Tasks Using Task-Based Boosting] (http://cs.brynmawr.edu/~eeaton/TransferBoost/TransferBoostExp.java), Eric Eaton and Marie desJardins, Java
- [Domain Adaptation in Natural Language Processing] (http://www.mysmu.edu/faculty/jingjiang/software/DALR.html), Jiang Jiang,C++
- [Triplex Transfer Learning: Exploiting both Shared and Distinct Concepts for Text Classification] (http://www.intsci.ac.cn/users/zhuangfuzhen/code&data_TriTL.rar), Fuzhen Zhuang , Ping Luo, et al.,Matlab
- [Heterogeneous Transfer Learning for Image Classification] (http://www.cse.ust.hk/~yinz/htl4ic.zip), Yin Zhu, Yuqiang Chen, et al.,Matlab
- [Domain Adaptation Toolbox] (https://github.com/viggin/domain-adaptation-toolbox), Ke Yan,Matlab
9. 参考资料
2017香港科技大学杨强机器之心GMIS峰会演讲
2016香港科技大学杨强KDD China技术峰会演讲
Sinno Jialin Pan and Qiang Yang, A survey on transfer learning
Karl Weiss, Taghi M. Khoshgoftaar and DingDing Wang, A survey of transfer learning
龙明盛,迁移学习问题与方法研究
注:上文部分图片摘自以上参考资料
作者:李中杰

