
百度Tera数据库介绍——类似cassandra,levelDB
转自:https://my.oschina.net/u/2982571/blog/775452
设计背景
百度的链接处理系统每天处理万亿级的超链数据,在过去,这是一系列Mapreduce的批量过程,对时效性收录很不友好。在新一代搜索引擎架构设计中,我们采用流式、增量处理替代了之前的批量、全量处理。链接从被发现到存入链接库再到被调度程序选出,变成一个全实时的过程。在这个实时处理过程中,无论链接的入库还是选取,都需要对链接库进行修改,存储系统需要支持千万甚至上亿QPS的随机读写。旧的存储系统无论在单机性能,还是在扩展性方面,都无法满足,所以我们设计了Tera。
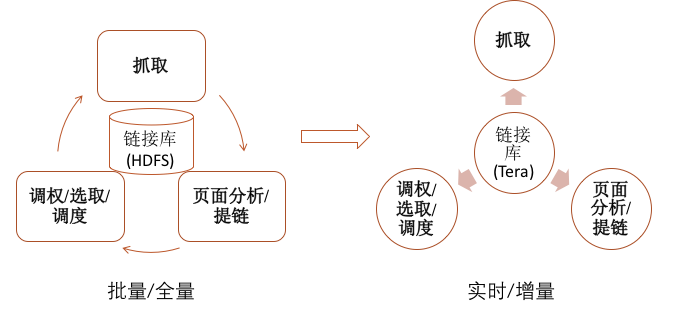
链接存储的需求
1. 数据按序存储
支持主域、站点和前缀等多维度统计、读取。
2. 自动负载均衡
分区可以动态调整,在一个分区数据量变大或者访问频率过高时,可以自动切分,小的分区也可以自动合并。
3. 记录包含时间戳和多个版本
对于链接历史抓取状态等记录,需要保留多个版本,对于策略回灌等场景,需要根据时间戳判断,避免旧的数据覆盖新的。
4. 强一致性
写入成功,立即可被所有的用户看到。
5. 支持列存储
在用户只访问固定的少数几列时,能使用更小的IO,提供更高的性能(相对于访问全记录),要求底层存储将这部分列在物理上单独存储。
设计目标
功能目标
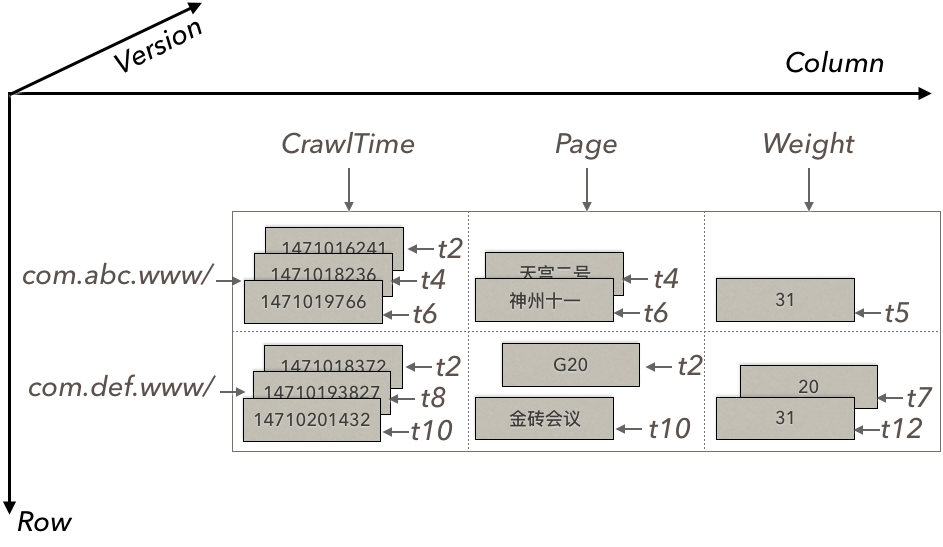
1. 全局有序
key可以是任意字符串(二进制串),不限长度,比较逻辑可由用户定义,按Key的范围分区,分区内由单机维护有序,分区间由Master维护有序。
2. 多版本
每个字段(单元格)都可以保留指定多个版本,系统自动回收过期版本,用户可以按时间戳存取。
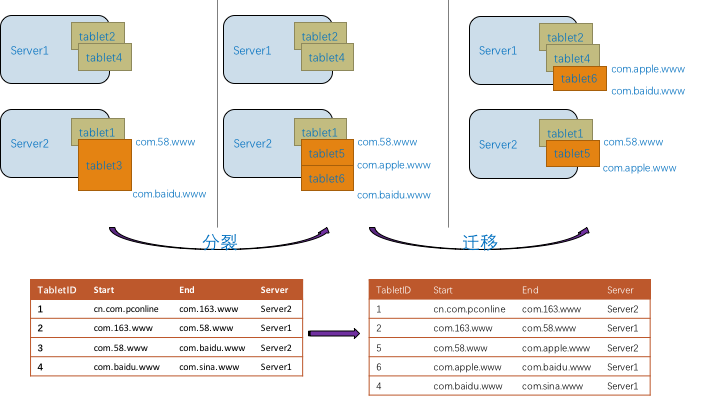
3. 自动分片
用户不需要关心分片信息,系统自动处理热点区间的分裂,数据稀疏区间的合并。
单个分区的数据量超过阈值,自动切分为多个,单个分区的读写频率增高时,自动切分。
4. 自动负载均衡和扩容
单机上保存多个分区,分区的总大小和总访问量达到阈值时,可以触发将部分分区迁移到空闲的机器。
性能指标
Tera设计使用SSD+SATA磁盘混布机型。
1. 单机吞吐
顺序读写: 100MB/S
随机读1KB: 30000QPS
随机写1KB: 30000QPS
2. 延迟
延迟和吞吐需要折衷考虑,在延迟敏感性不高的场合,使用延迟换吞吐策略,延迟定位在10ms级,写操作延迟<50ms,读延迟<10ms。
对于对延迟要求高的场合,读写延迟定位在<1ms,但吞吐会有损失,初期不做优化重点。
3. 扩展性
水平扩展至万台级别机器,单机管理百级别数据分片。
| 数据量 | 系统吞吐 | |
|---|---|---|
| 站点信息服务 | 10TB | 百亿次/天 |
| 用户行为分析 | 1PB | 百亿次/天 |
| 超链存储 | 10PB | 万亿次/天 |
| 页面存储 | 100PB | 万亿次/天 |
设计思路
数据存储
1. 数据持久性
为保证数据安全性,要使用三副本存储,但维护副本的一致性与副本丢失恢复需要处理大量细节,基于一个分布式的文件系统构建,可以显著降低开发代价,所以我们选择了使用DFS(如BFS)。
系统的所有数据(用户数据和系统元数据)都存储在DFS上,通过DFS+WriteAheadLog保证数据的持久性,每次写入,保证在DFS上三副本落地后,才返回成功。
2. 强一致性
数据会按key分区存储在DFS上,分区信息由Master统一管理,Master保证每个分区同一时间只由一个数据节点提供读写服务,保证一致性。
3. 延迟换吞吐
每次写操作落地一次导致的性能问题可以通过批量落地实现,比如每10ms数据落地一次,在数据落地前写操作不返回,代价是增加了5ms的平均响应时间。
4. 存储接口封装
Tera不会以某一种DFS作为唯一选择,而是通过底层存储接口的封装,使其可搭建在其他分布式存储之上,方便用户根据个性化需求灵活地部署Tera。
希望了解更多?请点击 https://github.com/baidu/tera

