


NoSQL学习笔记 – Dynamo
要想入门NoSQL,先读圣经Dynamo。
Amazon的这篇论文《Dynamo: Amazon's Highly Available Key-value Store》网上随处可以下得到,据说搞NoSQL的人都是从这里爬出去的。短短16页,不大好看,但非常精彩。不好看不是说写的不好,而是里面提到了很多分布式系统的概念和算法,要引经据典不容易弄懂(好吧,其实是个人基础太差);精彩在于从数据存储格式到分布式管理算法到系统布局架构都有,已有技术的运用也非常漂亮,就算不是玩NoSQL,学了也有益处。
废话太多,入正题。分下面几部分一步步介绍(注:有不对的地方欢迎提出)
- 需求背景
- 算法设计
- 系统实现
- 总结陈词
1. 需求背景
第一个问题,为什么amazon要做Dynamo这个东西,用传统的数据库不行么?回答这个问题之前我们先看看Amazon网站架设的需求。
Amazon拥有5900万活跃用户、25万多可在线全文阅读的图书、数据存储总量达到42TB。2010年有个统计,amazon每年通过每部kindle卖出的图书数量为24本,按2010年销售kindle300万台来算,amazon光kindle上每天卖出的图书就有19.7万。amazon还提供了服务水平协议(SLA),简单的例子来说,amazon服务器要求对99.9%的用户请求在300ms内提供响应。
别误会,我不是在给Amazon做广告,而是想说,对应这样的存储率、吞吐量和性能要求,传统数据库很难全部兼顾。还记得CAP原理么?传统数据库没有P,数据集中存储。存储率可能不是问题,但是对吞吐量和性能来说就有点吃力。再加上为了防止单点故障,数据必然有备份与复制,在强一致性的要求下,又必将以损失性能为代价。而且人家生意越做越大,数据越来越多,传统数据库的可扩展性也是个问题,这不是一部强大的机器不停的挂硬盘就能解决的问题。
所以,时势造英雄,Dynamo应运而生。它的最大特点是去中心化的分布式系统,整个Dynamo存储平台由多个物理异构的机器组成(可以是廉价的普通机器),每台机器角色一样,可以随意添加或去除,且不需要太多人为干预。每台机器存放一部分数据,这些数据的备份同步完全由系统自己完成,单台机器故障甚至一个数据中心的断电故障都不会影响系统对外的可用性,是具有高可用性和高扩展性的分布式数据存储系统。
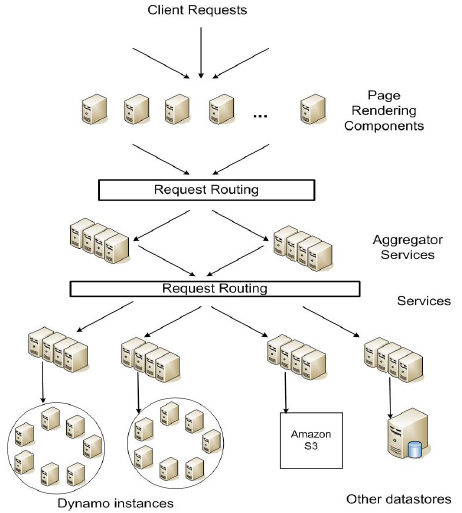
神奇吧,嗯,胃口先得吊足了。下面这张图是Amazon平台的服务架构,先看看Dynamo在整个平台中的作用和位置,后面会有对其实现的具体讨论。每个物理的Dynamo instance我们叫做一个结点。
2. 算法设计
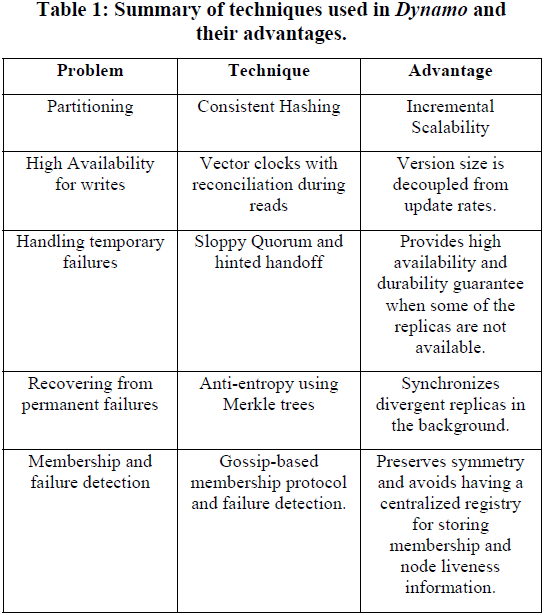
要实现上面所说的那么神奇的系统,用到的技术非常的不少。下图列出了Dynamo用来解决问题的一些技术。包括Consistent hashing、Vector clock、Merkle tree、Quorum、Gossip protocol等等一系列的相关概念。
这部分会用需要解决的问题,一个一个来解释他们的使用。
2.1 数据存储格式(key-value)
既然是数据存储系统,存储格式是首先要看看的。
和传统关系型数据库用表来组织数据不同,Dynamo用key-value来存储数据。这是由Amazon服务的特点决定的。Amazon的大部分服务只需要根据primary key来查询存储操作数据,不需要复杂查询或类似JOIN那样的SQL操作,所以key-value结构就够了。(其实这也是NoSQL的一个缺点,应用场景关联,如果业务逻辑需要复杂RDBMS的功能,NoSQL可能并不是一个好的选择)
举个例子,对交易数据了来说,(key,value)对应(交易id,交易信息(包含用户id和书本id等等)),文章没提具体的实现,所以不知道value的具体存储格式。在实际操作中,除了key和value,每个key还会附加一个context内容用来记录一些数据上下文,这个后面再说。
这些value会根据key值的md5不同,被存放到不同的分区结点上。
2.2 数据分区(Partitioning)
Dynamo是怎样将那么多数据平均放在多个结点上的呢?做Hash平均分配就行了嘛。假设有N个结点,hash(key)模N就可以把key值平均分配在结点上。但这样有个问题,当有新结点加入的时候,因为N变了,所有的数据必须重算并重新迁移分配。一般的应用可能无所谓,考虑Amazon那么大的数据量和SLA要求,把所有的数据重算一遍就要了命了。
Dynamo用Consistent Hashing(http://en.wikipedia.org/wiki/Consistent_hashing)来解决这个问题
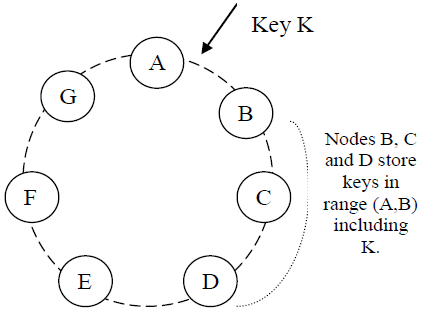
一样是hash,但是不是根据取模结果,而是根据区间范围来存放。每个结点被分配一个区间,比如说A分配的区间是[A,B),那么只有满足A<=hash(key)<B的key值会存放在A结点上。这样,当有新结点加入时,受影响的只有相邻结点而不是所有结点。比如,在AB之间加入一个结点H,只要把A上的数据拆成[A,H)和[H,B),并把[Q,B)迁到Q上就行了
这样迁移时还是需要对A的所有数据进行扫描拆分,会影响结点A的响应速度。有没有更好的方法?有,Dynamo引入虚结点的概念。假设有N个结点,把所有key值分成Q个区间(Q>>N),一个区间就是一个虚结点,这Q个虚结点轮番依次放在N个真实结点上,每个结点上存放Q/N个虚结点。比如说,has(key)的结果是128位,那么K的范围在[0,2^128)。把这个范围平均分成2^8份,也就是说Q=256个虚结点,第一个虚结点范围就将是[0,2^16)。再假设一共有N=10个物理结点,那么每个结点将平均存放25个虚结点。1号结点上存放的key值范围是[0,2^16),[2^144,2^160),[2^304,2^320)……一共25个,二号结点放的是[2^16,2^32),[2^160,2^176),[2^320,2^336)等25个。那么当再添加一个新结点时,平均每个结点上存放23个,它需要从其他10个上挨次拿2个出来。
这样的好处是,结点的添加和删除只需要重新分配虚结点,省去了数据扫描和拆分的工作,而且迁移时负载平均。
2.3 数据分区的复制(Replication)
为了达到数据高可用性和数据持久型,所有的结点都要求备份。在Consistent Hashing Ring上面,用后续结点为前面的结点做备份。在上面的图上,B、C、D为A做备份,一共备份3份。也就是说key值K同时存在4个结点上。
虽然K值存在4个结点上,但这4个结点会记在一个persist list上面,以这个例子来说list=(A,B,C,D),只有排在第一的结点负责K值的操作以及将它复制到其他结点。当A结点挂掉时,才按persist list的排序由后续结点接手。
这里有两点需要考虑,一个是虚结点的问题,另一个是备份数量的问题。上面提到Consistent Hashing Ring上的每一个结点其实都是一个虚结点,ABCD可能位于同一个物理结点上,如果这样的话,备份就是去了意义。因为如果这个结点故障了,所有备份都会丢失。所以在选择备份结点时,必须保证挑选不同的物理结点。关于备份的数量,少了容易丢失数据,多了备份间同步开销增大。在Amazon系统中备份数量是3,具体怎么得出来的,下面再看
2.4 多复制分区的数据版本管理(Data Versioning)
复制的版本多了,那么对这些不同复制版本的同步写会造成数据冲突,或者说数据不一致性。比如说K=1在ABCD上都有备份,客户请求1由A结点接手,要求K值加1,那么在A结点上K=K+1=2。这个改动还没来得及复制到BCD,客户请求2到了,又要求加1,这次由B接手,那么B结点上K=K+1=2。这时候,当客户请求读时,K到底是几?
传统数据库有集中管理ACID(http://en.wikipedia.org/wiki/ACID)保证,分布式数据库系统该怎么做呢?写涉及磁盘操作,如果要求对所有的备份都写完成才算事物结束,会严重影响性能。
Dynamo用vector clock允许多版本数据存在。首先先来看下vector clock(http://en.wikipedia.org/wiki/Vector_clock)的概念,它是在分布式系统中用来记录事件发生时序的算法。
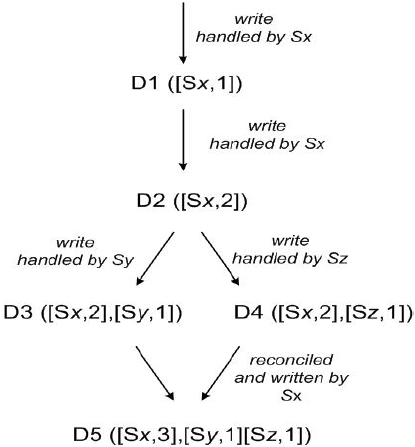
上面的图给了个用clock vector记录数据版本的例子。一共有3个结点处理4次写请求。第一次写请求由Sx完成。第二次写请求依旧发生在Sx上,所以数据版本直接加1。第三次请求由Sy处理,这时候它从Sx复制过来的数据版本是2,但是有可能在复制完到处理请求这段时间内,Sx上的版本变成了3但是没有复制过来,所以不能直接在Sx上操作,另加[Sy,1]这个版本信息。第四个写请求同理。在这个时候,读请求将读出所有的版本,根据业务逻辑算出合理的值返回客户,并将合并后的结果写回。
假设W是代表写成功的结点的个数,R是读成功的结点的个数,N表示复制版本的数量。这个例子用W=1,R=N的模式,通过由请求客户自己完成多版本合成的方式保证数据同步。这种例子的好处是写很快,但是读很慢。但是如果对于读要求高但是写要求不高的应用就不适用。而且如果刚写入的那个结点还没来得及复制就挂掉了,会造成数据丢失。
在Dynamo系统中,NRW是可以配置调优的。根据最终测评结果,(N,R,W)=(3,2,2)。也就是说,一份数据会有3份拷贝,写操作时,当有2个结点返回写成功,就代表事务成功。读操作一样,至少读到两个结点的数据才算读成功。至于多版本的数据之间怎样合并,以及NRW更多的考量,在后面的系统实现部分会有更多的讨论。
2.5 故障处理(Handling Failures)
前面说过,虽然有很多复制版本,但只有persist list上最前面一个负责拥有的key值的操作。所有它上面的key值得操作请求都会路由给它。拿上面的例子举例,对K值的操作会路由给A,当A挂掉时,如果后续请求依旧路由给A处理显然不合适。
Dynamo用Hinted Handoff(http://wiki.apache.org/cassandra/HintedHandoff)来解决这个问题。当A挂掉后,persist list上后面一个结点B负担起A原来的责任,对K值得操作由B来负责。同时B定期查询A活了没有,如果活过来了,将所有数据复制回A,并将操作权交还给A。保证任何时刻数据都有高可用性
2.6 分区数据的同步机制(Replica synchronization)
多复制版本之间进行数据同步在分布式系统中是不可避免的,那么怎样同步么?系统怎样快速的知道各个结点上数据版本的差别并进行快速同步么?
Dynamo用Merkle Tree(Hash Tree)来解决这个问题。Merkle Tree(http://en.wikipedia.org/wiki/Hash_tree)是一种数据结构,它只在叶子结点存放数据,父结点用来存放子结点的摘要信息。父结点的变化只受子结点决定。比如说一棵Merkel tree有一个跟结点Z,两个子结点XY,子结点X拥有叶子结点ABC,子结点Y拥有叶子结点DEF。那么A变化时,X受A牵连重算,Z受X牵连重算,而Y不变。这样,当这棵树有两个备份同步时,通过比较结点是否一样,就可以找出最小变化集合,并同步相应内容。上面的例子中,Y分支不需要任何同步操作,需要同步的只有结点AXZ。
如果知道Git的同学这部分会相当好理解,貌似Git的branch和submit的管理和合并也是通过Merkel Tree实现的
2.7 新结点加入和故障侦测(Membership and Failure Detection)
一个Dynamo神奇的地方就是很少需要人工干预,这点有个问题。当新加入一个结点或者移除一个结点,或者当一台机器挂掉之后,怎么通知所有的结点这个信息呢?Dynamo系统是完全去中心化的,没有一个结点有管理员这样的角色,通知大家一起更新,所有的机器都是peer-to-peer的。
在这种分布式环境下,各个结点之间也有peer-to-peer的通信方式,gossip protocol(http://en.wikipedia.org/wiki/Gossip_protocol)。它是一系列用于P2P的通信协议。简单来说,就是模拟人类社会中流言传播的方式。每个节点随机地把消息发给它的邻居,接到消息的节点,如果之前没收到这个消息,则会继续随机地转发给它的邻居,否则不转发。这样,失败的结点或者成员信息的变化会像流言一样迅速到达Dynamo的所有结点。
当然根据传播内容的不同,可以用gossip protocol来达到不同的目的。其中一种类型就是Anti-entropy protocols,用于复制版本之间的错误侦测和错误校正
3. 系统实现
好,基于以上的算法设计,对分布式数据管理中的问题都有了相应的技术解决方案,现在对照最开始的系统架构图,来看看怎么由这些算法设计拼出Dynamo的整个系统实现。
3.1 物理架构
先从物理结构来看,整个Dynamo系统由多台异构的机器组成,就是我们上面所说的结点。这些机器分布在多个数据中心,数据中心之间通过高速网连接,persist list的top N结点也会尽量保证分布在不同的数据中心上。这样,即使发生地域性的整体数据中心损坏,系统还是可以照样提供服务。
每台机器上都有三个功能模块:请求协调器(request coordinator),成员关系和失败监测器(membership and failure detector)和一个本地引擎(local persistence engine)。其中,协调器用来接收来自前端server的请求。
3.2 请求的发送
前端的请求有两种:get(key)和put(key,value,context),分别对应数据库系统的读和写请求。他们由前端server利用基于HTTP协议的Amazon的infrastructure-specific request processing framework(别问我这是个什么东西,我也不知道,文章里面没说……)触发。
那么server是怎样把put或者get请求发送到对应的包含该key的机器上呢?有两种方式。一、随便发到任一机器,由任一机器根据成员关系图找到对应的结点,转发请求过去。二、在server端调用Dynamo结点分配算法直接找到对应key的结点把请求发过去。第一种方法的好处是server端不需要依赖Dynamo的实现,第二种方法的好处是请求不需要转发,低延迟。实际选用哪种文章也没提,估计是对不同应用选不同方式吧。
3.3 请求的处理
当一个请求被发送到对应结点后(persist list上的第一个结点),该结点上的协调器接收这个请求并作出相应的处理。
在解释具体怎么处理put和get请求之前,是时候解释下NRW模型了,这个模型的背后是分布式数据库系统中多个数据备份之间的读写效率、数据一致性和持久性之间一系列的取舍。在数据版本的时候已经说过一点了,N表示数据备份的数量,R表示至少读R个备份才算读请求成功,W表示至少写入W份才算写入成功。如果要求强一致性,所有数据备份必须都是一致的,那么W=N、R=1,这样永远不会有数据不一致的问题。但是这样对写请求来说就不是高效的,甚至在某一结点失效的情况下,写请求将永远失败,这对Amazon的购物车之类的请求是无法忍受的。那么是不是设成W=1,R=N就可以解决这个问题了呢?好,假设W=1,那如果刚写完这个结点,这个结点就挂了呢?数据丢失,同样不可接受。那Dynamo是怎么做的呢?
在Dynamo里(N,R,W)是可配置的,根据调优的结果(有兴趣看怎么调优的可以看原文)最终选定(N,R,W)=(3,2,2)加上writer thread的解决方案。这样既符合Quorum W+R>N的要求,又保证了数据持久性,同时利用writer thread方案提高响应速度。
好,一切就绪,来看看具体put和get请求的处理吧。
当一个结点的协调器收到put请求时,它会向top N里的结点都发出写请求,当其中2个返回写成功后,它会向请求server发回确认写请求成功的相应。为了减少写磁盘造成的响应延迟,Dynamo只要求N个结点中有一个真正写入磁盘就行,其他的暂时写入内存就算写入成功。这些内存中的数据将来会由writer thread批量写回磁盘,跟PostgreSQL的logger进程有异曲同工之妙。利用writer thread,只要N>W+1,就能达到既不影响写效率有不丢失数据的效果
当收到get请求时,同样向top N里的所有结点发出读请求,当其中2个返回数据时就算读成功。在这里,不是光读出数值那么简单,除了读出的数值外,还包含一个context结构,里面包含了数据版本等一些额外信息。协调器需要对应不同的应用需求对多个版本的数据进行合并返回。
这其中还有很多有趣的东西,比如多个结点对put和get的响应时间都会随context一起返回,作为从persist list挑选合适结点达到SLA的依据,又比如写请求之后一般会跟随一个读请求,可以把它们分配给同一个结点处理达到read-your-write的一致性要求等等。这块其实看的也不是很明白,就不再说了
4. 总结陈词
总而言之,Dynamo用很多已有的技术拼出这样一个神奇的系统,做法非常的漂亮。相对于传统数据库设计偏重于schema的设计来说,它的重点更偏向于分布式系统中的一些问题的处理。而传统数据库的一些基本要求,比如说数据一致性的同步处理和多个复制版本合并的问题,不再从属它的范畴,而是暴露给程序员自己解决,麻烦但是灵活,应用相关。
但它也有它的致命伤,应用场景的限制。对于要求复杂RDBMS操作的应用,它也很难处理。举个简单的例子,如果所有书本信息都是用(书本id,书本信息)的方式存放在多个数据结点上的话,那么按书名排序这样的应用该如何解决。如果Amazon有提供这个功能,那么我很好奇实现会是怎样的。
上面这两点,也刚好是NoSQL与传统数据库的差别。
