


[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
原文链接:http://www.cnblogs.com/blog5277/p/8615984.html
原文作者:博客园--曲高终和寡
点击下面菜单查看大数据入门全部教程
网址:
http://www.cnblogs.com/blog5277/category/1179528.html
**********************************分割***********************************
其实按理说,Java项目是完全可以开发spark项目的,并不是一定需要scala来开发.
但是天不遂人愿,新项目里面用到了supermap的组件,他们的组件对scala支持的更好一点,就表现在,用scala的话,某函数的入口参数只有两个

但是用java的话就有4个

然后我还完全不知道这些参数指的是啥,
那没办法,只能换scala了(再加上spark就是基于scala开发的,技多不压身,学一学呗)
万万没想到,我在用IDEA在集成scala的时候,遇到了这么多坑(部分是因为我自己对scala的认知不够)
下面进入正题:
**********************************分割***********************************
一.下载IDEA的scala插件
1.个人推荐方式:
在IDEA-->设置-->插件-->搜索scala-->在仓库里找-->往下面翻一点,找到scala,看一下对应的版本号,记住这个版本号

然后在:
http://plugins.jetbrains.com/plugin/1347-scala
去这里下载对应的版本(下载完的zip不要解压缩):
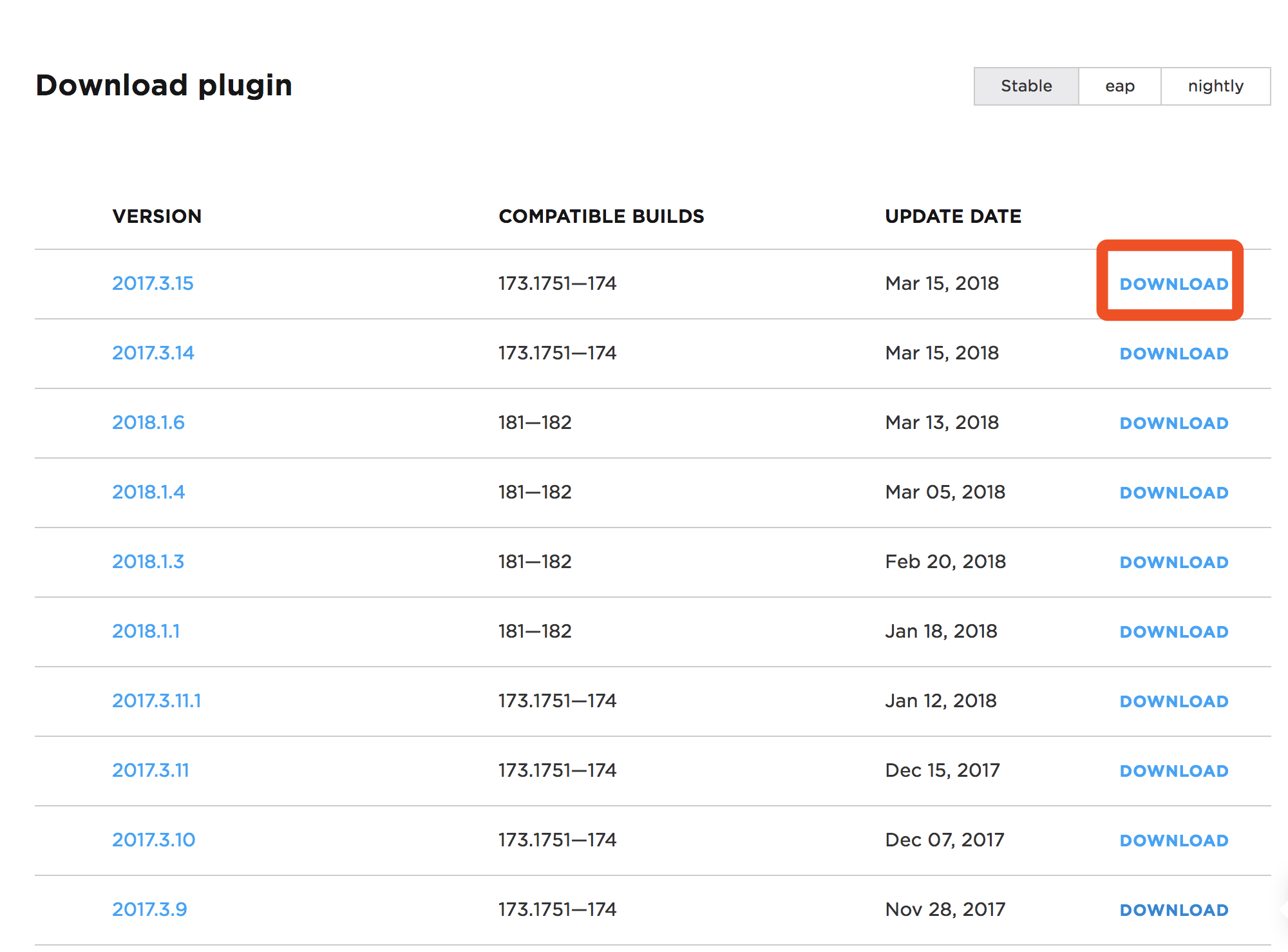
经过非常非常漫长的下载....下载完了之后返回IDEA,在设置页面选择添加本地的插件:
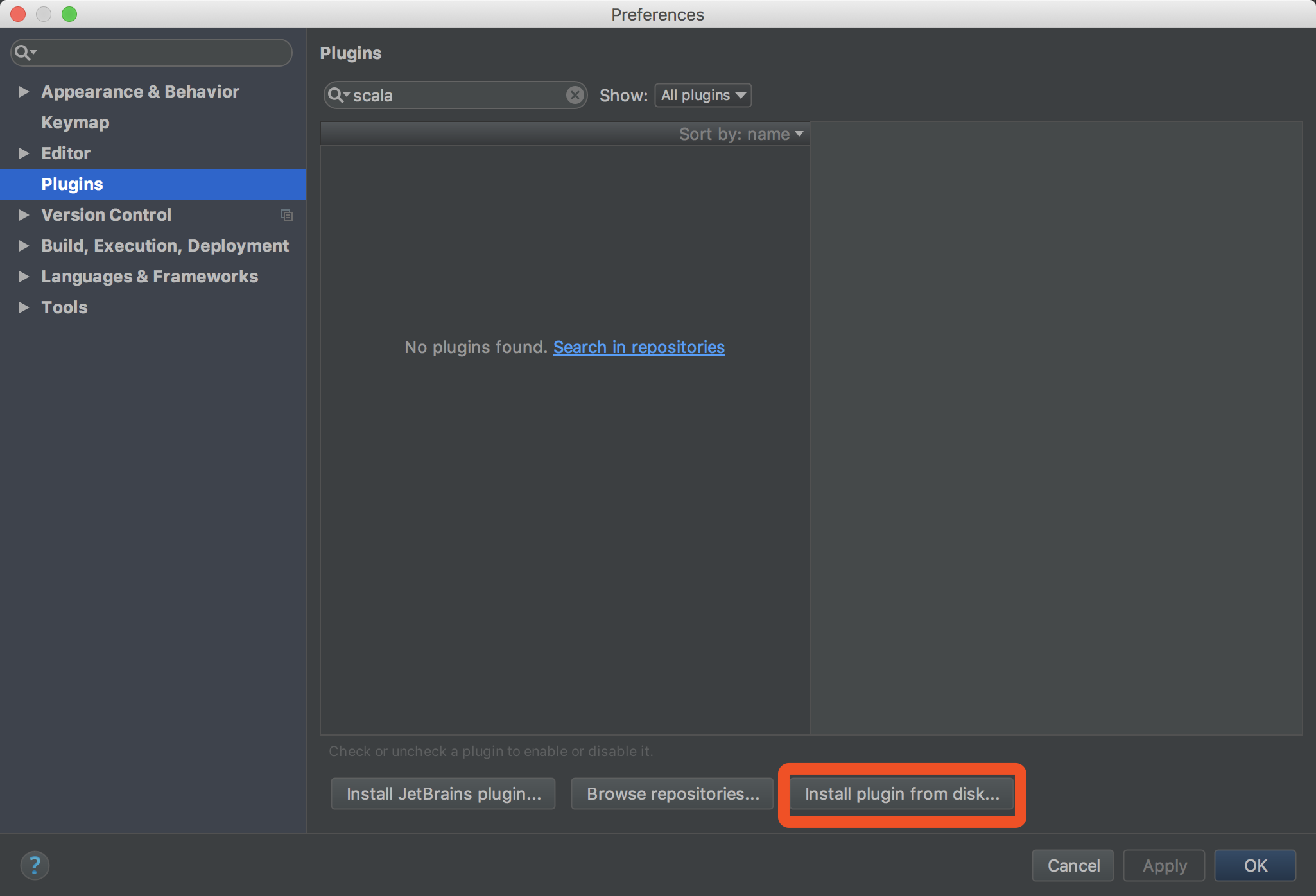
选择你刚刚下载完的zip,添加,apply一下,确定就可以了,IDEA会提示你重启idea生效,你重启一下,插件就装完了.
2.不太推荐的方式...在idea-->设置-->插件-->搜索scala-->在仓库中搜索这里,其实可以直接安装的...
明明这么方便,我为啥不推荐呢...因为在国内,这个插件的下载速度也太慢了...还很容易失败(方法一也巨慢无比,但是毕竟是用浏览器/迅雷下的,不会失败,失败了也会断点续传),而在这里,极其容易失败...
开$$走PAC/全局代理/V屁N的方法我都试了,并不能加快下载速度,让人绝望...
二,开始scala的hello world
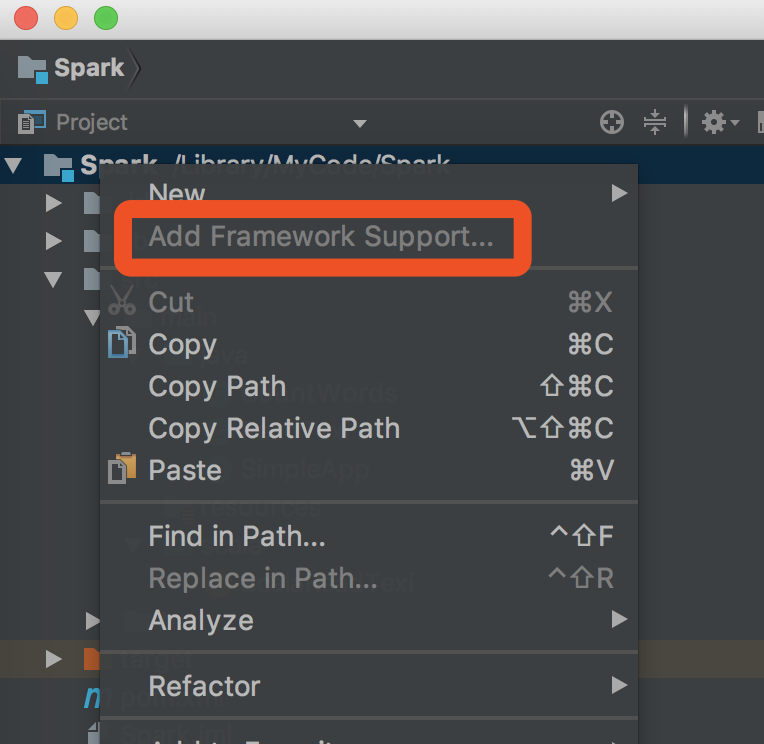
1.在项目上,右键,添加框架支持,选中出现的Scala
2.(这一项是可选项,还是建议选的)在maven里加入scala相关的jar包和编译组件插件
这里引用了 菩提树下的杨过 大神的教程
https://www.cnblogs.com/yjmyzz/p/4694219.html

<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.3.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.scala-lang/scala-library --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.12.4</version> </dependency> <!-- https://mvnrepository.com/artifact/org.scala-lang/scala-compiler --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>2.12.4</version> </dependency> <!-- https://mvnrepository.com/artifact/org.scala-lang/scala-reflect --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>2.12.4</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
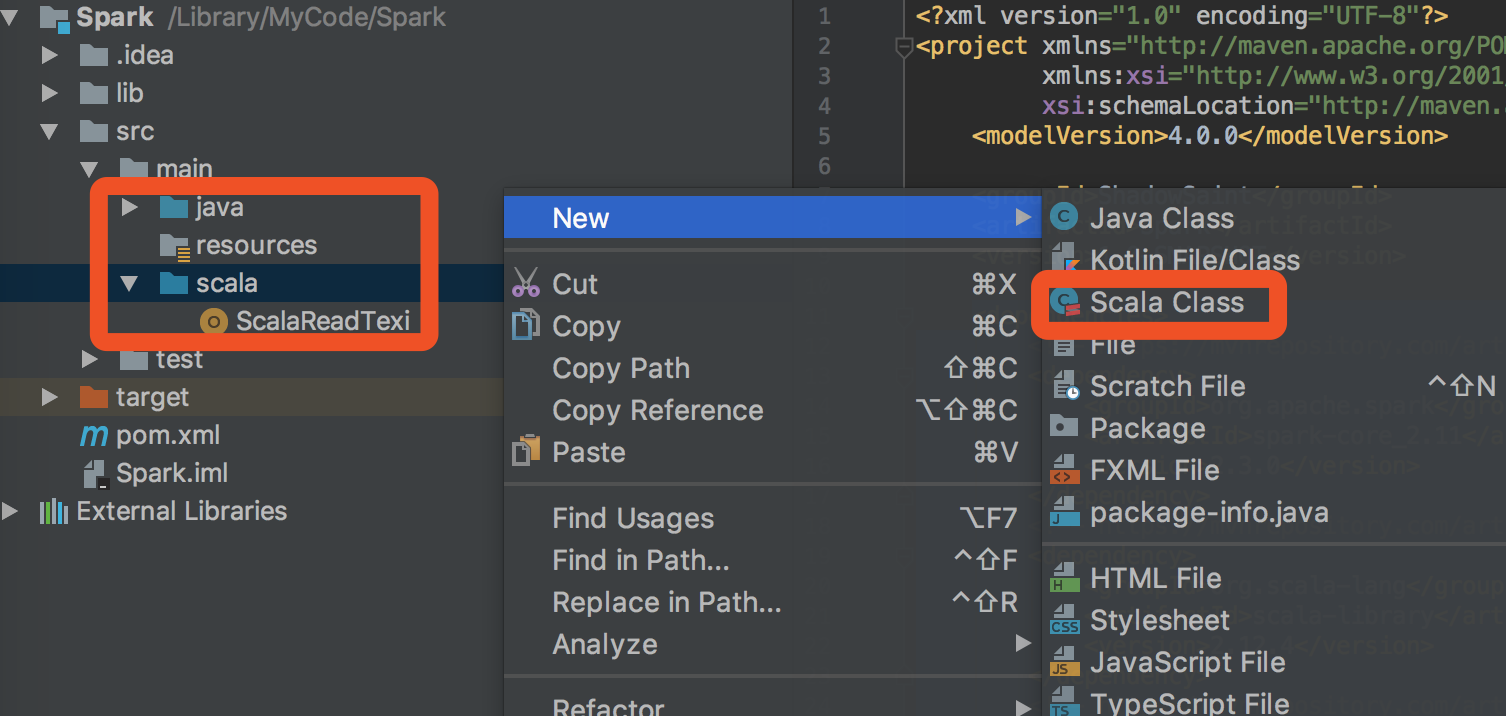
3.在项目main下,和java同一级,新建个文件夹叫scala,你在这个文件下下就可以新建scala项目了
4.这里介绍2种运行scala项目的方式,这里困扰了我好久...
5.用java方式调用
新建scala文件,用默认的方式建class文件,如下图:
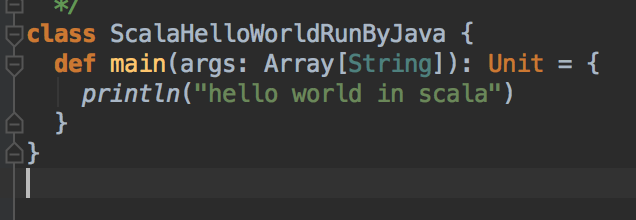
在新建出来的scala文件里面,按 command + j (windows下应该是alt吧...不行就试试ctrl),或者手动照着下面敲也可以

输完后面的代码:
这个时候你会发现你运行不了...:
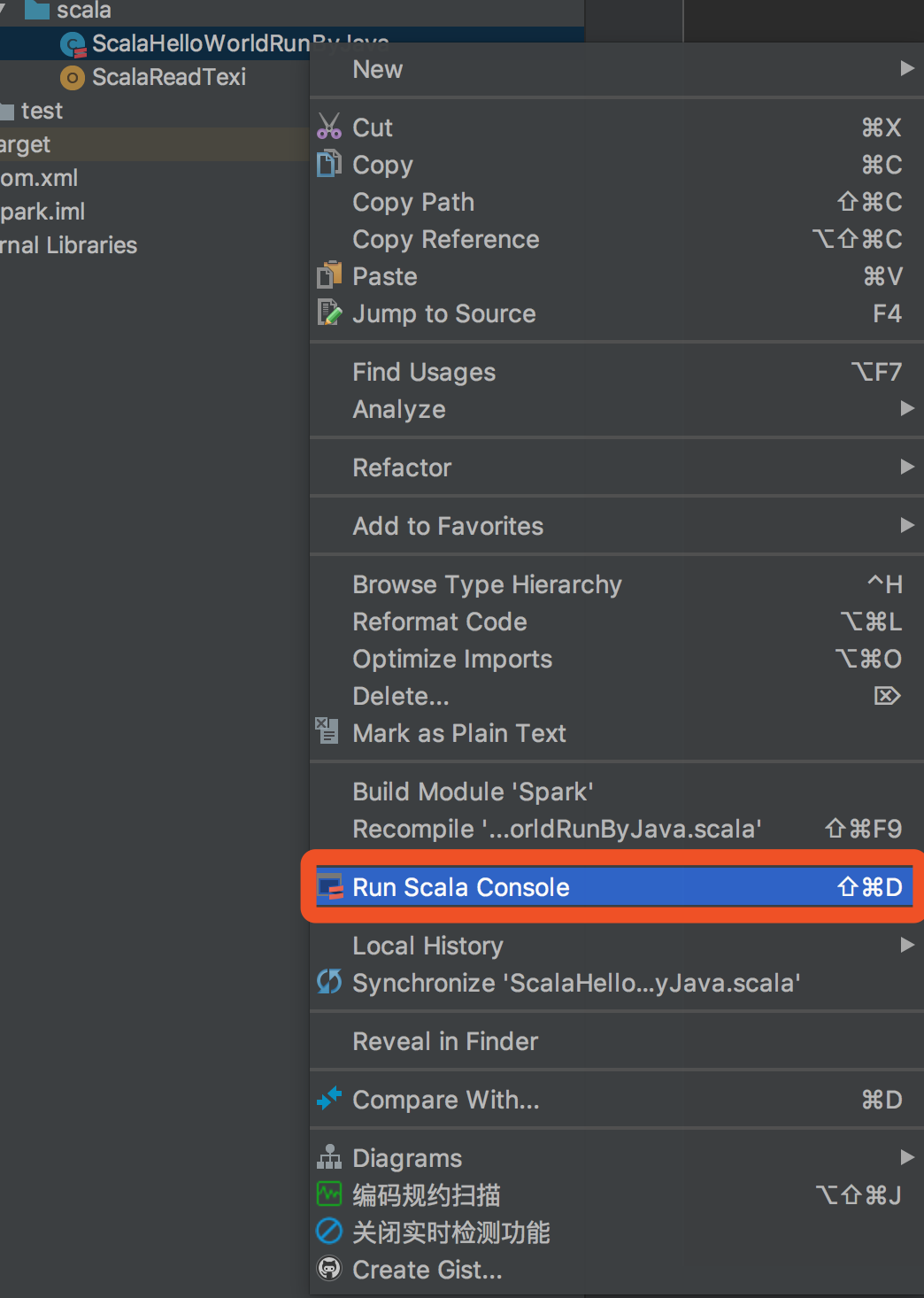
点它会出现控制台,然而这会你什么语法都不会..
所以没办法了,新建一个java文件来运行scala文件吧,可别忘了,scala也是jvm语言,再加上kotlin,这俩语言可是号称能和java项目"无缝衔接"的,scala项目当然能用java来运行了,如下图:

就把scala当一个java的类去调就行了,还是很方便的...的....吧...
6.直接运行scala文件
然而scala其实也有自己的运行方式,这点在创建文件的时候你要选择,不要用默认的class,要用object...(或者你把上面的class改成object也可以)

这样的话这里就有运行选项啦,注意区别,这里是object
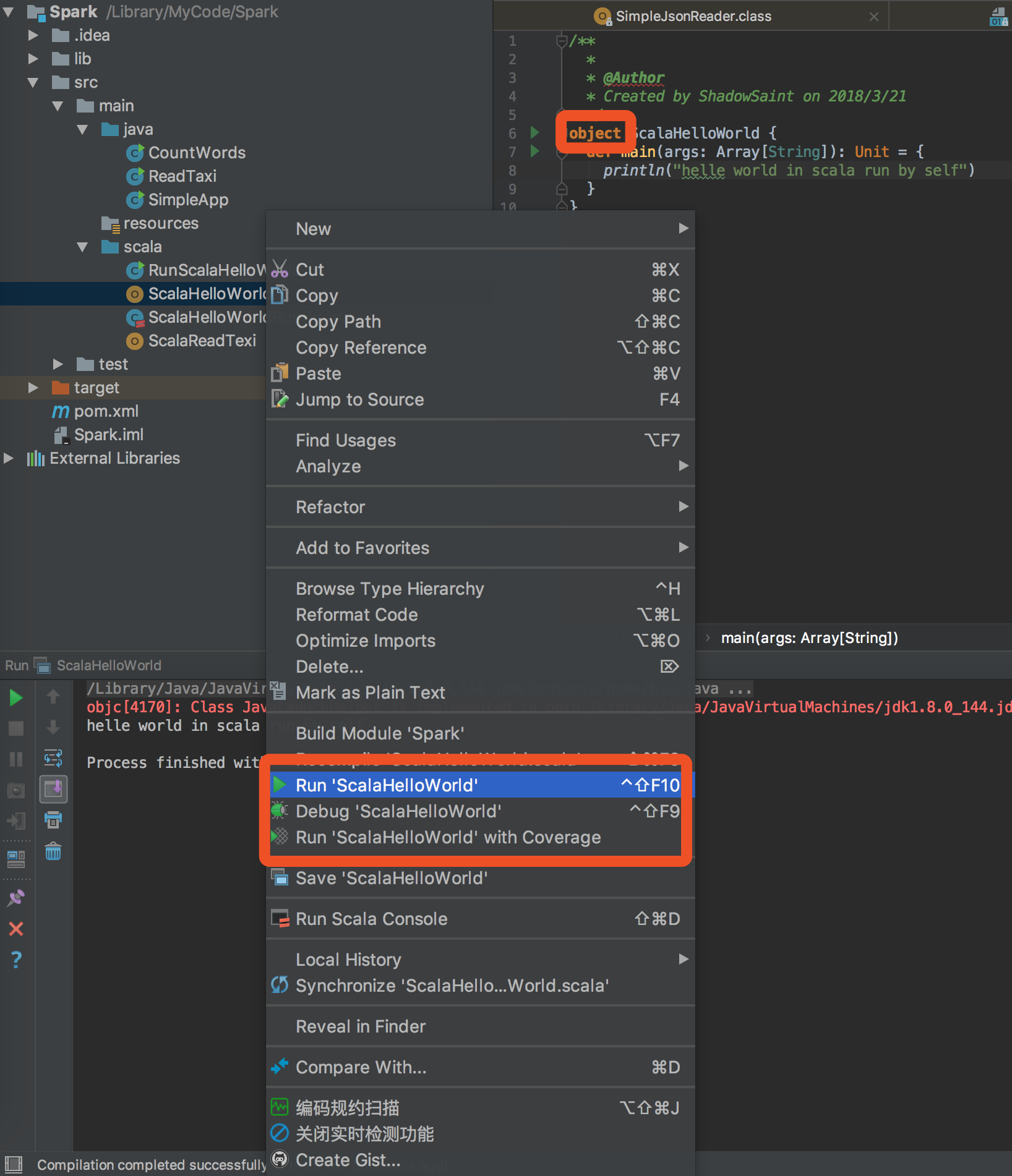
好了,今天就到这了

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步