


java根据URL获取网页编码
由于很多原因,我们要获取网页的编码(多半是写批量抓取的脚本吧...嘻嘻嘻)
注意:
如果你的目的是获取不乱码的网页内容(而不是根据网址发送post请求获取返回值),切记切记,移步这里
java根据URL获取HTML内容
先说思路:
有三种方法:
1,根据responseHeaders获取Content-Type里的charset,如下图
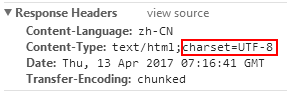
这种方法最好,最推荐,然而,很多网站都没有,要么是像百度这样:
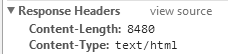
有Content-Type,然而没有指定charset
要么是像博客园这样:

???Content-Type都不给我么...???

所以虽然这种方法最准确.但是...并不是每个网站都有的...
2.根据html标签里的meta取
这里还以百度为例:

怎么取标签,我就不说了,如果不会就留言,如有需要我再写博客(然而也没什么人看我博客,更没什么人会留言...悲伤...我就默认你们都会取了)
虽然中文乱码,但是英文是不乱的,哪怕你不知道编码,随便用个GBK,UTF-8都能取...
但是,这种方法不准...不保证一定能取到正确的
并且..由于这种方法你还得拿到HTML内容...所以,还得判断一下是不是GZIP方式压缩了...贼麻烦...所以我就放弃了
3.通过第三方库,去猜格式
这种方法,原则上讲是存在一定的猜错几率的...
原理是同时进行多种编码的尝试(gb2312啊,utf-8啊,windows-XXXX啊),哪个先返回正确的格式就认定是哪个...虽然根据我的尝试很准,然而理论上还是会不贴切的,没有第一种准.
文件下载:https://files.cnblogs.com/files/blog5277/cpdetector_1.0.10_binary.zip
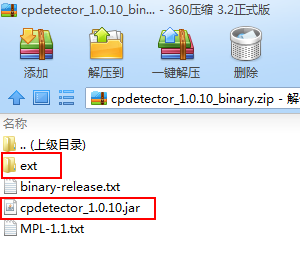
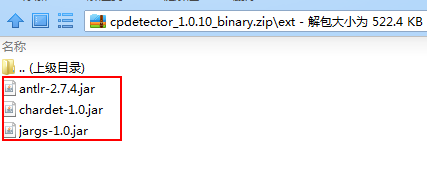
切记切记,总共是4个jar包...别的教程里并没有告诉我,害得我分别去找这三个编码jar包,好气...最后才发现原来就在这个压缩包里...吃了眼瞎的亏了
这四个jar包放进你项目里就行
最后,经过慎重的考虑与取舍,我决定先用第一种方法取(毕竟最准确),放弃第二种方法(贼麻烦...),第一种取不到了,再用第三种猜,如下

public static String getUrlCharset(String url){ try { String urlNameString = url; URL realUrl = new URL(urlNameString); // 打开和URL之间的连接 URLConnection connection = realUrl.openConnection(); // 设置通用的请求属性 connection.setRequestProperty("accept", "*/*"); connection.setRequestProperty("connection", "Keep-Alive"); connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)"); // 建立实际的连接 connection.connect(); // 获取所有响应头字段 Map<String, List<String>> map = connection.getHeaderFields(); // 遍历所有的响应头字段 System.out.println("Content-Type" + "--->" + map.get("Content-Type")); List<String> list=map.get("Content-Type"); if (list.size()>0){ String contentType=list.toString().toUpperCase(); if (contentType.contains("UTF-8")){ return "UTF-8"; } if(contentType.contains("GB2312")){ return "GB2312"; } if (contentType.contains("GBK")){ return "GBK"; } } //如果相应头里面没有编码格式,用下面这种 CodepageDetectorProxy codepageDetectorProxy = CodepageDetectorProxy.getInstance(); codepageDetectorProxy.add(JChardetFacade.getInstance()); codepageDetectorProxy.add(ASCIIDetector.getInstance()); codepageDetectorProxy.add(UnicodeDetector.getInstance()); codepageDetectorProxy.add(new ParsingDetector(false)); codepageDetectorProxy.add(new ByteOrderMarkDetector()); Charset charset = codepageDetectorProxy.detectCodepage(new URL(url)); return charset.name(); }catch (Exception e){} return null; }
如果返回值是null,那很不幸,我也不知道哪里出异常了,自己debug解决吧,嘻嘻.一般是没事.最多就是网络不好timeout了
就这样

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步