MySQL学习(一)
前言
我们对于MySQL的使用已经不再陌生.毕竟已经用了好几年,但是可能也仅仅是停留在表面上,这次我本着在深入一点了解来写这个系列的博客以做备忘
MySQL:开源的免费的数据库,已经被Oracle收购了,MySQL5.5版本后都是由Oracle发布版本
Oracle:收费的大型的数据库,Oracle公司的产品,Oracle收购SUN公司,收购MySQL
DB2: IBM公司的数据产品,收费的常用在银行系统中,在中国的互联网公司要求去IOE(I:IBM小型机,Oracle数据库,EMC存储设备)要不然出现问题都得去找他们去解决.
SQLServer:MicroSoft 公司收费的中型的数据库。C#、.net等语言常使用。
SyBase :已经淡出历史舞台。提供了一个非常专业数据建模的工具PowerDesigner。
SQLite : 嵌入式的小型数据库,应用在手机端。
历程:
2000,MySQL不仅公布自己的源代码,并采用GPL(GNU General Public License)许可协议,正式进入开源世界。同年4月,MySQL对旧的存储引擎ISAM进行了整理,将其命名为MyISAM。
2001年,集成Heikki Tuuri的存储引擎InnoDB,这个引擎不仅能持事务处理,并且支持行级锁。后来该引擎被证明是最为成功的MySQL事务存储引擎。MySQL与InnoDB的正式结合版本是4.0
2003年12月,MySQL 5.0版本发布,提供了视图、存储过程等功能
2008年1月,MySQL AB公司被Sun公司以10亿美金收购,MySQL数据库进入Sun时代。在Sun时代,Sun公司对其进行了大量的推广、优化、Bug修复等工作
2008年11月,MySQL 5.1发布,它提供了分区、事件管理,以及基于行的复制和基于磁盘的NDB集群系统,同时修复了大量的Bug。
2009年4月,Oracle公司以74亿美元收购Sun公司,自此MySQL数据库进入Oracle时代,而其第三方的存储引擎InnoDB早在2005年就被Oracle公司收购。
2010年12月,MySQL 5.5发布,其主要新特性包括半同步的复制及对SIGNAL/RESIGNAL的异常处理功能的支持,最重要的是InnoDB存储引擎终于变为当前MySQL的默认存储引擎。MySQL 5.5不是时隔两年后的一次简单的版本更新,而是加强了MySQL各个方面在企业级的特性。Oracle公司同时也承诺MySQL 5.5和未来版本仍是采用GPL授权的开源产品。
下载地址:https://dev.mysql.com/downloads/mysql/
安装问题
解决linux mysql命令 bash: mysql: command not found 的方法
1.首先得知道mysql命令或mysqladmin命令的完整路径
比如mysql的命令在/usr/local/mysql/bin/mysql
liunx系统或者mac系统默认会加载/usr/bin下面的命令,我们只需要将mysql的命令软连接到里面即可
sudo ln -s /usr/local/mysql/bin/mysql /usr/bin
当我们运行这个命令的时候报错!
ln: /usr/bin/mysql: Operation not permitted
这是因为苹果在OS X 10.11中引入的SIP特性使得即使加了sudo(也就是具有root权限)也无法修改系统级的目录,其中就包括了/usr/bin。要解决这个问题有两种做法:
一种是比较不安全的就是关闭SIP,也就是rootless特性;
另一种是将本要链接到/usr/bin下的改链接到/usr/local/bin下就好了。
sudo ln -s /usr/local/mysql/bin/mysql /usr/local/bin
在使用mysql命令 这次就可以了
SQL分类:
数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等。关键字:create,alter,drop等
数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。关键字:insert,delete,update等
数据控制语言:简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户;关键字:grant等
数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。关键字:select,from,where等
SQL查询
执行顺序
select * from user left join product on user.id=product.uid where prodcut.price > 10 group user.name order by user.id having count(1) >5 order by user.name limit 10
1.from(将最近的俩张表笛卡尔积)->形成一张虚拟的表1
2.on (将虚拟表进行过滤)-->vt2
3.left join (决定保留左表还是右表的记录) -->vt3
4.where (过滤vt3中的记录)-->vt4.....vtn 每次重新生成一个虚拟表
5.group by (对vt4中的数据进行分组)-->vt5
6.having (vt5中的数据进行过滤)-->vt6
7.select (对vt6 中的记录进行过滤列,选取指定的列)-->vt7
7.order by (对vt7的记录进行排序)-->游标的一个东西,没有对vt7的数据进行改变
9.limit (对排序之后的数据进行分页)
SQL优化原则
where 条件执行顺序的很重要(影响性能)
1.mysql 从左到右
2.Oracle 从右往左执行where条件
结论:写where提交的时候,先去编写过滤力度最大的条件语句
MySql 架构
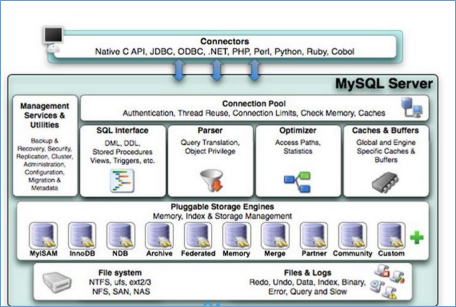
1. connectors:
指的是不同语言与sql的交互
2.Connection Pool: 连接池,
管理用户的连接,线程处理等需要缓存的需求. 负责监听对MySQL server的各种请求.接受连接请求.转发所有连接请求到线程管理模块,每一个连接上MySQLserver的客户端,都会分配(或者创建)一个连接线程为其单独服务,而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递 Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的 cache 等。
3.SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
4.parse:解析
SQL命令传递到解析器的时候会被解析器验证和解析, 主要功能.将sql语句进行 语义和语法的分析,分解数据结构.然后按照不同的操作类型进行分类.针对性的转发到后续的步骤,如果在解析的过程中出现错误,那么这个SQL就是不合理的
5. Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。
它使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
6.cache和buffer :查询缓存
他的主要功能是将客户端提交给MySQL的 select请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该 query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
参考:https://www.cnblogs.com/snifferhu/p/4734339.html
7.存储引擎接口
存储引擎接口模块可以说是 MySQL 数据库中最有特色的一点了。目前各种数据库产品中,基本上只有 MySQL 可以实现其底层数据存储引擎的插件式管理。这个模块实际上只是 一个抽象类,但正是因为它成功地将各种数据处理高度抽象化,才成就了今天 MySQL 可插拔存储引擎的特色。
从图还可以看出,MySQL区别于其他数据库的最重要的特点就是其插件式的表存储引擎。MySQL插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都必需的,如SQL分析器和优化器等,而存储引擎是底层物理结构的实现,每个存储引擎开发者都可以按照自己的意愿来进行开发。
注意:存储引擎是基于表的,而不是数据库。
8.logs
最后一层就是文件和日志信息 .
执行流程
简单的执行流程
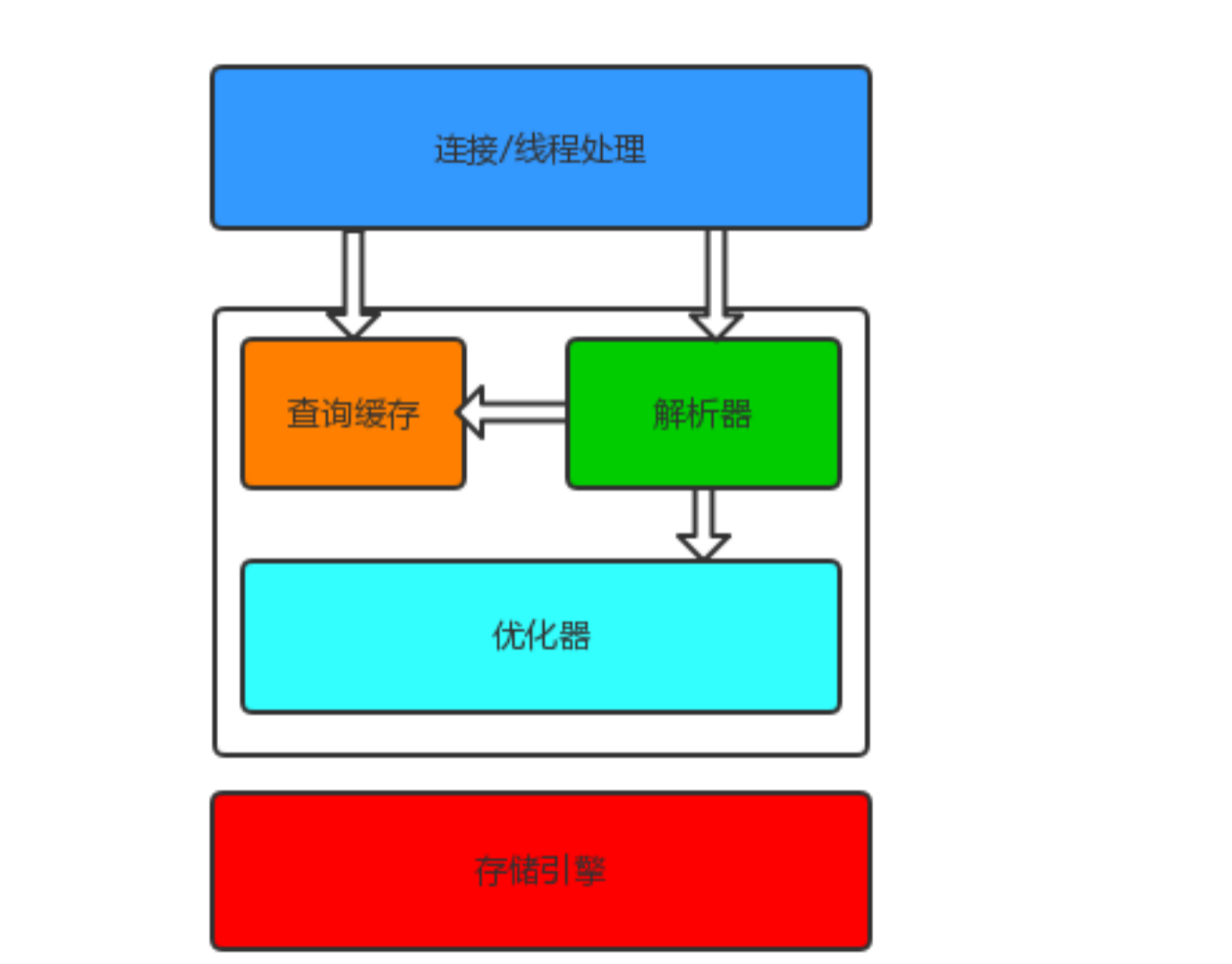
1.一个SQL来了先去缓存看看有没有他的数据,
2.没有的话就就进入解析器模块 parse进行对SQL进行解析
3.然后进如优化器
4.然后调用存储引擎
MySQL的存储引擎有几个?

| innodb | myisam | |
| 存储文件 | .frm表定义文件. idb数据文件(和索引文件一起) | .frm表定义文件 .myd数据文件 .myi索引文件 |
| 锁 | 表锁 行锁 | 表锁 |
| 事务 | ACID | 不支持事务 |
| CRUD | 读 写用的多 | 读多 |
| count | 扫表->统计数据 | 将count数值统计出来了.供我们读取 |
| 索引结构 | b+tree | b+tree |
一起交流进步.扫描下方QQ二维码即可

