dex文件格式二
一. dex文件头
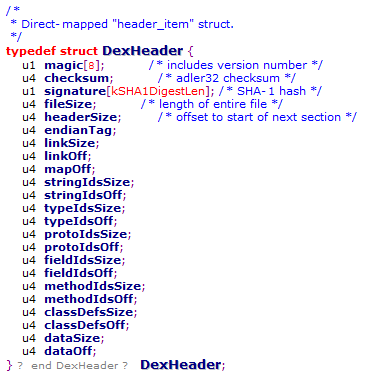
(1) magic value
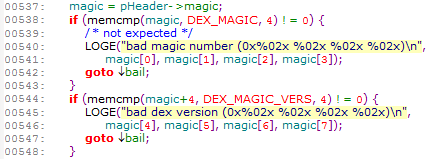
在DexFile.c dexFileParse函数中 会先检查magic opt
啥是magic opt呢? 我们刚刚从cache目录拷贝出来的那个

前面的dey 036就是magic opt
在源码中会先解析magic opt,然后重设dexfile指针

重设magic opt指针后开始解析magic value
这 8 个 字节一般是常量。数组的值可以转换为一个字符串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex\n035\0"
(2) checksum
文件校验码 ,使用alder32 算法校验文件
先用dexheader先校验,校验失败在使用opt header去校验

其校验算法如下除去maigc,checksum 外余下的所有文件区域 ,用于检查文件错误

(3) signature
signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,用于唯一识别本文件

由此可见我们在修改了dex文件之后,得先修正signature然后在修正checksum
(4) file_size
Dex 文件的大小 ,源码中会拿该字段和传入的长度值进行比较

(5) header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量
在DexSwapVerify.c dexSwapAndVerify

高版本不知道是不是这样校验的 大于居然没有置为okay
(6) endian_tag
大小端标签 ,标准 .dex 文件格式为小端 ,此项一般固定为 0x12345678常量
CmdUtils.c 程序调用主线从
dexOpenAndMap->dexSwapAndVerifyIfNecessary->dexSwapAndVerify->swapDexHeader

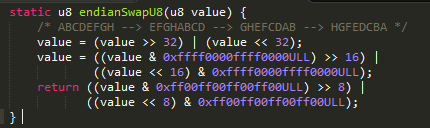
这里逻辑有点绕,他默认就会转换一次, 如果是小尾,转换之后就是大尾,那么校验就不会通过
如果是大尾方式, 就转换成小尾, 校验通过,继续后面的转换流程
还一个校验是如果是odex格式,那么已经是优化之后的,则不需要转换

其转换算法如下:
(6) link_size和link_off
这个两个字段是表示链接数据的大小和偏移值

CHECK_OFFSET_RANGE 只是检查是否超出文件指针范围

(7) map_off
map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。

其结构体指向:

MapItem

对应的枚举值
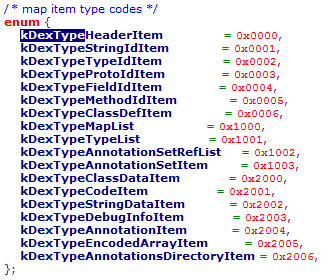
010Editor中呈现

(8) string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
(9) type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构
(10) proto_ids_size和type_ids_off
这两个字段表示dex中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息,后面会详细介绍proto_ids的数据结构
(11) field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
(12) method_ids_size和method_ids_off
这两个字段表示dex中的方法信息数据结构的大小和偏移值,后面会详细介绍method_ids的数据结构
(13) class_defs_size和class_defs_off
这两个字段表示dex中的类信息数据结构的大小和偏移值,这个数据结构是整个dex中最复杂的数据结构,
他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦,所以后面会着重讲解这个数据结构

没有类的话,dex校验会失败
(14) data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
到这里我们就看完了dex的头部信息,头部包含的信息还是很多的,主要就两个个部分:
1) 魔数+签名+文件大小等信息
2) 后面的各个数据结构的大小和偏移值,都是成对出现的
下一节我们就来开始介绍各个数据结构的信息
