面试整理:数据库
数据库基本操作


# 数据库操作 1. 显示数据库 show databases; 2. 进入指定数据库 use 数据库名称; 3. 创建数据库 create database 数据库名称 default character set=utf8; 4.删除数据库 drop database 数据库名称; # 数据库表操作: 1.创建表: create table studentInfo2( name VARCHAR(10) not NULL, sex char(10) null, age int(5), phone BIGINT(11) ) 2.删除表 drop table 表名; # 新增表数据 #一次增加一条数据 insert into studentinfo (name,sex,age) VALUES('大花','男','12') #一次增加多条数据 insert into studentinfo (name,sex,age) VALUES('大花','男','12'),('二花','女','32') insert into 表名称 (字段名称,多个以“,”间隔)values(‘具体的值’多个以“,”间隔) # 修改 update studentinfo set name='花花' where name='二花' # 删除 delete from 表名 where 条件
引擎
1、Myisam
支持全文索引 查询速度相对快 支持表锁 - 加锁语句:select * from tb for update;(锁:for update)
2、InnoDB
支持事务操作 支持行锁/表锁
- 表锁:select * from tb for update;(锁:for update)
- 行锁:select id ,name from tb where id = 2 for update; (用索引去检索)(锁:for update)
表设计(★★★★★)
3、基本表设计
FK的使用情景(一对多:书和出版社) M2M的使用情景(多对多:学生和老师) PS: 可以从下面项目实例中详细了解 - 数据库部分: 课程、老师、学生、分数 - 博客 - 权限
查询表数据
4、各种查询操作
参见:Mysql41题
http://www.cnblogs.com/wupeiqi/articles/5729934.html
优化: 查询时尽量不要用 select *
连表操作
5、连表操作
left join
- 左边表全部显示出来,右边有就有没有 显示 Null- select * from tb1 left join tb2 on tb1.xx = tb2.xx # tb1所有都显示,如果tb2中未找到对应项则显示Null
inner join
- 只显示公共部分,null行全部去掉- select * from tb1 inner join tb2 on tb1.xx = tb2.xx # Null行全部去掉
分组操作
6、分组操作
select 部门ID,max(id) from 用户表 group 部门ID
select 部门ID,max(id) from 用户表 group 部门ID having count(id) > 3
概念性问题
7、存储过程:
- 将提前定义好的SQL语句保存到数据库中,并命名;以后在代码中调用时,直接通过名称即可
- 参数类型:in 、out 、 inout
8、触发器:
- 对数据库某个表进行【增、删、改】前后,自定义的一些SQL操作
9、视图:
- 对某些表进行SQL查询,将结果实时显示出来(是虚拟表),只能查询,不能更新
10、函数:
- 在SQL语句中使用的函数 #例子:select sleep(2) - 聚合 max、sam、min、avg - 时间格式化 date_format - 字符串拼接 concat
- 自定制函数
(触发函数通过 select ) # 以上内容都是保存在数据库中的。
11、存储过程

12、函数和存储过程的区别
- 函数:
- 参数
- 返回值:return
- 存储过程:
- 参数
- 返回值:out/inout
- 返回结果集:select * from tb;
索引
13、索引都有哪些?
总共五种索引+两个关键词:
单列: 1、主键索引 - primary key - 加速查找 + 约束: 不能重复 + 不能为空 2、普通索引 - 加速查找 3、唯一索引 - unique - 加速查找 + 约束: 不能重复 多列: 4、联合索引 - 查询时根据多列进行查询(最左前缀) 5、联合唯一索引 PS: 遵循最左前缀规则(命中索引) 其他词语: 1、索引合并:利用多个单例索引查询 2、覆盖索引:在索引表中就能将想要的数据查询到
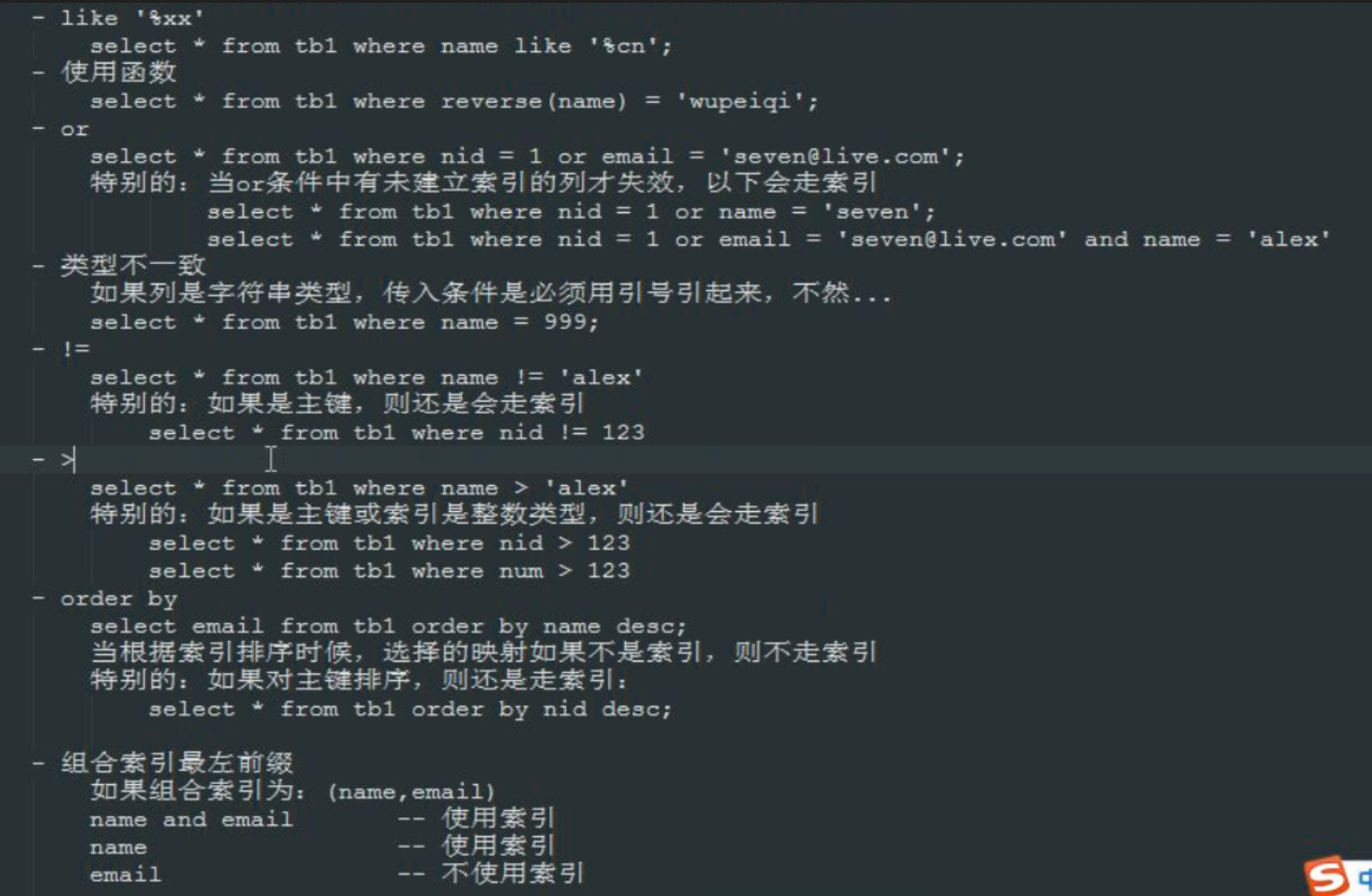
14、创建了索引应该如何命中索引?(★★★★★)
(哪种情况下创建了索引,无法命中索引?)
有些 order by
数据库分页
15、如何进行分页合适?
可能会存在的问题以及如何解决: 常规分页,往后翻的越多,查询速度越慢(limit xx offset xx 查询的越多,扫描的数目越多)
models.User.objects.all()[0:10] 本质:select * from tb limit 3 offset 5
答案一
#先查主键,再分页: select * from tb where id in (select id from tb where limit 10 offset 30)
答案二
# 可以按照当前业务实际需求,看是否可以设置只允许看前200页; # 一般情况下,没几个人会 咔咔看个几十上百页的
答案三
# 记录当前页,数据 ID 最大值和最小值(用于 where 查询) # 在翻页时,根据条件进行筛选, 筛选完毕后,再根据 limit offset 查询 select * from (select * from tb where id > 22222) as B limit 10 offset 0; # 如果用户自己修改页码,也可能导致变慢, 此时可对 url 页码进行加密,例如 rest framework
其他
16、如何开启慢日志查询?
可以通过修改配置文件来开启

17、执行计划
# explain + SQL语句 # SQL在数据库中执行时的表现情况,通常用于SQL性能分析,优化等场景。 'explain select * from rbac_userinfo where id=1;'
+----+-------------+---------------+-------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------------+-------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | rbac_userinfo | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL | +----+-------------+---------------+-------+---------------+---------+---------+-------+------+-------+
18、导入导出数据库
桌面版操作工具,直接右键选项找导入\导出 1.导出整个数据库 mysqldump -u用户名 -p密码 数据库名 > 导出的文件名 2.导出一个表,包括表结构和数据 mysqldump -u用户名 -p 密码 数据库名 表名> 导出的文件名 4.导出一个表,只有表结构 mysqldump -u用户名 -p 密码 -d数据库名 表名> 导出的文件名 5.导入数据库 - 进入数据库 mysql -u root -p use 数据库 - 导入 mysql>source ./dabebase.sql
优化方案
19、数据库优化方案
1、创建数据表时把固定长度的放在前面() 2、将固定数据放入内存: 例如:choice字段 (django中有用到,数字1、2、3…… 对应相应内容) 3、char 和 varchar 的区别(char不可变, varchar可变) 4、联合索引遵循最左前缀(从最左侧开始检索) 5、避免使用 select *
6、读写分离
- 实现:两台服务器同步数据
- 利用数据库的主从分离:主,用于删除、修改、更新;从,用于查;

7、分库
- 当数据库中的表太多,将某些表分到不同的数据库,例如:1W张表时
- 代价:连表查询跨数据库,代码变多
8、分表
- 水平分表:将某些列拆分到另外一张表,例如:博客+博客详情
- 垂直分表:将某些历史信息分到另外一张表中,例如:支付宝账单
9、加缓存
- 利用redis、memcache (常用数据放到缓存里,提高取数据速度)
- 缓存不够可能会造成雪崩现象
如果只想获取一条数据 - select * from tb where name=‘alex’ limit 1
ORM
20、什么是ORM?
ORM是一种关系对象映射
类 ---> 表 属性 ---> 字段 对象 --->一条数据
21、ORM创建数据库
class WebGroup(models.Model): name = models.CharField(max_length=64) brief = models.CharField(max_length=255,blank=True,null=True) owner = models.ForeignKey(UserProfile) admins = models.ManyToManyField(UserProfile,blank=True,related_name='group_admins') members = models.ManyToManyField(UserProfile,blank=True,related_name='group_members') max_members = models.IntegerField(default=200) def __str__(self): return self.name
基本增删改查
22、增
if request.method == "POST": input_em = request.POST['em'] # em 和 pwd都是和form表单里面的一一对应 input_pw = request.POST['pwd'] print(input_pw,input_em) models.UserInfo.objects.create(email=input_em, pwd=input_pw) #models调用的是先前创建好的数据库
23、删
models.UserInfo.objects.filter(email=input_em).delete()
24、改
models.UserInfo.objects.filter(email=input_em).update(pwd='nihao')
25、查
def index(request): # 数据库获取数据,数据和HTML渲染 from app01 import models user_info_list = models.UserInfo.objects.all() return render(request,'index.html',{'user_info_list':user_info_list}) # 前端拿到数据进行渲染展示
26、ORM的Model查询操作(★★★★★)
models.UserInfo.objects.create() # 添加数据方法1 obj = models.UserInfo(name='xx') # 添加数据方法2 obj.save() models.UserInfo.objects.bulk_create([models.UserInfo(name='xx'),models.UserInfo(name='xx')]) #创建多个 models.UserInfo.objects.all().delete() #删除 models.UserInfo.objects.all().update(age=18) #查 models.UserInfo.objects.all().update(salary=F('salary')+1000) #更新 # 各种models方法 .get() #用于查询数据,如果没有则报错 .filter(id__gt=1) # 获取id大于1的值 .filter(id__gte=1) # 获取id大于等于1的值 .filter(id__lt=10) # 获取id小于10的值 .filter(id__lte=10) # 获取id小于10的值 .filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 .filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 .exclude(id__in=[11, 22, 33]) # not in(不包括\排除) .values() .values_list() .anotate() # 分组 .order_by() .order_by('-id') .first() #... .laste() #... .exsit() #... .reverse() # 反转 .distinct() # 去重 .extra() #在QuerySet生成的SQL从句中注入新子句 #例如:queryResult=models.Article.objects.extra(select={'is_recent': "create_time > '2017-09-05'"}) .raw() # F查询 #主要用来获取原数据进行计算 例如: #Goods.objects.update(price=F("price")+10) #对于goods表中每件商品的价格都在原价格的基础上增加10元 Q查询 #主要用来进行复杂查询 #例如: Book.objects.filter(Q(id=3))[0] # 因为获取的结果是一个QuerySet,所以使用下标的方式获取结果 Book.objects.filter(Q(id=3)|Q(title="Go"))[0] # 查询id=3或者标题是“Go”的书 Book.objects.filter(Q(price__gt=70)&Q(title__startswith="J")) # 查询价格大于等于70并且标题是“J”开头的书 Book.objects.filter(Q(title__startswith="J") & ~Q(id=3)) # 查询标题是“J”开头并且id不是3的书 Book.objects.filter(Q(price=70)|Q(title="Python"), publication_date="2017-09-26") # Q对象可以与关键字参数查询一起使用,必须把普通关键字查询放到Q对象查询的后面 #连表查询 .select_related() #为了减少SQL查询次数 class UserInfo(models.Model): #示例 name = models.CharField(max_length=32) email = models.CharField(max_length=32) ut = models.ForeignKey(to='UserType') ut = models.ForeignKey(to='UserType') # 1次SQL查询 # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: print(item.name) # n+1次SQL查询 # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: # select * from usertype where id = item.id print(item.name,item.ut.title) # 1次SQL查询 # select * from userinfo inner join usertype on userinfo.ut_id = usertype.id objs = UserInfo.obejcts.all().select_related('ut') for item in objs: print(item.name,item.ut.title) .prefetch_related() #为了减少SQL查询次数 # select * from userinfo where id <= 8 # 计算:[1,2] # select * from usertype where id in [1,2] objs = UserInfo.obejcts.filter(id__lte=8).prefetch_related('ut') for obj in objs: print(obj.name,obj.ut.title) .using #用于分库,指定数数据库创建数据,或者指定使用哪个数据库 .count #计数 .only #只查某一项 .defer #排除某一项 .[1,100] .aggregate #聚合函数 # 多对多 .add #把指定的模型对象添加到关联对象爱集中 .set #先清空再设置 .remove #从关联的对象集中移除执行的模型对象 # 补充: # 无约束: class UserType(models.Model): title = models.CharField(max_length=32) class UserInfo(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) # 无数据库约束,但可以进行链表 ut = models.ForeignKey(to='UserType',db_constraint=False) # 有约束: class UserType(models.Model): title = models.CharField(max_length=32) class UserInfo(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) # 有数据库约束,可以进行链表 ut = models.ForeignKey(to='UserType') 示例
27、ORM常用内容
- order_by
- group_by
- limit
- 连表/跨表
28、ORM中靠近原生SQL的用法
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid,name as title from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default")
from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..)
29、高级些的ORM操作
- F
- Q
- select_related
- prefech_related
- (答案见第26问)
30、ORM其他方法汇总
################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 # 获取所有用户表 # 获取用户类型表where id in (用户表中的查到的所有用户ID) models.UserInfo.objects.prefetch_related('外键字段') from django.db.models import Count, Case, When, IntegerField Article.objects.annotate( numviews=Count(Case( When(readership__what_time__lt=treshold, then=1), output_field=CharField(), )) ) students = Student.objects.all().annotate(num_excused_absences=models.Sum( models.Case( models.When(absence__type='Excused', then=1), default=0, output_field=models.IntegerField() ))) def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values('nid').distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) ===> {'k': 3, 'n': 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self):
31、ORM和Sql用哪个?
- 快速开发用 ORM
- 性能要求的话用 Sql语句
32、 db first 还是 code first?
- db first 根据数据库的表生成类
- 原生SQL
- Django:
- Python manage.py inspectdb
- code first 根据类创建数据库表
- ORM操作
- Django:
- Python manage.py makemigrations
- Python manage.py migrate
33、多数据库相关操作?
python manage.py makemigraions #数据迁移 python manage.py migrate app名称 --databse=配置文件数据名称的别名
models.UserType.objects.using('db1').create(title='普通用户') result = models.UserType.objects.all().using('default')
class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ return 'default'
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), }, 'db1': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db1.sqlite3'), }, } DATABASE_ROUTERS = ['db_router.Router1',]
models.UserType.objects.create(title='VVIP') result = models.UserType.objects.all() print(result)
class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.model_name == 'usertype': return 'db1' else: return 'default' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ return 'default'
问题:
#app01中的表在default数据库创建 #app02中的表在db1数据库创建
# 第一步: python manage.py makemigraions # 第二步: app01中的表在default数据库创建 python manage.py migrate app01 --database=default # 第三步: app02中的表在db1数据库创建 python manage.py migrate app02 --database=db1 # 手动操作: m1.UserType.objects.using('default').create(title='VVIP') m2.Users.objects.using('db1').create(name='VVIP',email='xxx') # 自动操作: #配置: class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' DATABASE_ROUTERS = ['db_router.Router1',] #使用: m1.UserType.objects.using('default').create(title='VVIP') m2.Users.objects.using('db1').create(name='VVIP',email='xxx')
其他:
class Router1: def allow_migrate(self, db, app_label, model_name=None, **hints): """ All non-auth models end up in this pool. """ if db=='db1' and app_label == 'app02': return True elif db == 'default' and app_label == 'app01': return True else: return False # 如果返回None,那么表示交给后续的router,如果后续没有router,则相当于返回True def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1'
34、原生SQL和ORM的区别?
# ORM是一种关系对象映射 类 ---> 表 属性 ---> 字段 对象 --->一条数据 # 原生SQL是直接写SQL语句 #但ORM的本质还是SQL语句,ORM效率比SQL高,但速度没SQL快
SQLAlchemy
35、SQLAlchemy中的 session 的创建有几种方式?
# 直接创建Session对象 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) def task(arg): session = Session() obj1 = Users(name="alex1") session.add(obj1) session.commit() for i in range(10): t = threading.Thread(target=task, args=(i,)) t.start() # 基于scoped_session(Flask-SQLAlchemy中的连接默认使用该方法) engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) session = scoped_session(Session) def task(arg): obj1 = Users(name="alex1") session.add(obj1) session.commit() for i in range(10): t = threading.Thread(target=task, args=(i,)) t.start()
Redis
36、你了解的Redis?
#Redis是一种键值数据库,而非关系型;也就是NoSQL数据库; #支持五大数据类型: 字符串 字典 列表 集合 有序集合
37、你用redis做过什么?
#a、配合django做缓存,常用且不易修改的数据放进来(博客) #b、购物车信息 #c、Session - 缓存配置文件 - session配置文件中指定使用缓存 #d、rest api中访问频率控制 #e、基于flask、websocket实现的投票系统(redis做消息队列) #f、scrapy中 - 去重规则 - 调度器:先进先出、后进先出、优先级队列 - pipelines - 起始URL #g、商品热点信息 #h、计数器 #i、排行
38、为什么redis要做主从复制?
#目的是对redis做高可用,为每一个redis实例创建一个备份称为slave,让主和备之间进行数据同步,save/bsave。 主:写 从:读 #优点: - 性能提高,“从”分担“读”的压力。 - 高可用,一旦主redis挂了,从可以直接代替。 #存在问题:当主挂了之后,需要人为手工将从变成主。
39、redis的sentinel(哨兵)是什么?
帮助我们自动在主从之间进行切换
检测主从中 主是否挂掉,且超过一半的sentinel检测到挂了之后才进行进行切换。
如果主修复好了,再次启动时候,会变成从。
40、redis的cluster(集群)是什么?
#集群方案: - redis cluster:官方提供的集群方案。 - codis:豌豆荚技术团队。 - tweproxy:Twiter技术团队。
41、redis cluster的原理?
#基于【分片】来完成。 - 将你的数据拆分到多个 Redis 实例的过程 - 可以使用很多电脑的内存总和来支持更大的数据库。 - 没有分片,你就被局限于单机能支持的内存容量。 #redis将所有能放置数据的地方创建了 16384 个哈希槽。 #如果设置集群的话,就可以为每个实例分配哈希槽: - 192.168.1.20【0-5000】 - 192.168.1.21【5001-10000】 - 192.168.1.22【10001-16384】 #以后想要在redis中写值时:set k1 123 - 将k1通过crc16的算法转换成一个数字,然后再将该数字和16384求余, - 如果得到的余数 3000,那么就将该值写入到 192.168.1.20 实例中。
42、redis是否可以做持久化?
#RDB:每隔一段时间对redis进行一次持久化。 - 缺点:数据不完整 - 优点:速度快 #AOF:把所有命令保存起来,如果想重新生成到redis,那么就要把命令重新执行一次。 - 缺点:速度慢,文件比较大 - 优点:数据完整
43、redis的过期策略?
a、voltile-lru: #从已设置过期时间的数据集(server.db[i].expires)中挑选最近频率最少数据淘汰 b、volatile-ttl: #从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 c、volatile-random:#从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 d、allkeys-lru: #从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 e、allkeys-random: #从数据集(server.db[i].dict)中任意选择数据淘汰 f、no-enviction(驱逐):#禁止驱逐数据
44、redis的分布式锁如何实现?
写值并设置超时时间
超过一半的redis实例设置成功,就表示加锁完成。
#使用:安装redlock-py from redlock import Redlock dlm = Redlock( [ {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, ] ) # 加锁,acquire my_lock = dlm.lock("my_resource_name",10000) if my_lock: # J进行操作 # 解锁,release dlm.unlock(my_lock) else: print('获取锁失败') 官方中文文档:http://www.redis.cn/
