

3.2 卷积
一维卷积
Convolution
卷积也是很常用的一种计算模式。卷积计算方法如下:对输出数据中的每一个元素,它的值是输入数据中相同位置上的元素与该元素周边元素的值的加权和。卷积中有一个被称为卷积核(Kernel)或卷积码(Mask)的数据段,指定了周边元素的权值。为了避免混淆,以后都称为卷积码。计算如下图所示:

图中的M向量为卷积码,N向量为输入,P向量为输出。其中P[2] = N[0] * M[0] + ... + N[4] * M[4]。卷积计算需要考虑边界问题,如图,码长度为5,在计算前2个元素和后2个元素时需要的输入数据位置会越过边界。
这时我们需要手动地添加被称为Ghost Cell的元素,该元素的值视情况而定,这里为了简便,取0值即可。在由的应用里面也会把这个值设定为P[0].
一维卷积kernel 代码:
__global__ void convolution_1D_basic_kernel(float* N, float* M, float* P, int Mask_Width, int Width){ int i = blockIdx.x*blockDim.x + threadIdx.x; float Pvalue = 0; int N_start_point = i - (Mask_Width/2); for(int j = 0; j < Mask_Width; j++) { if(N_start_point + j >= 0 && N_start_point + j < Width){ Pvalue+= N[N_start_point+j] * M[j]; } } P[i] = Pvalue; }
二维卷积
二维的卷积计算是一维卷积的推广,如下所示:

注意由此产生的Ghost Cell也是二维的。
使用Tile 来计算卷积
1D卷积tile优化
一维卷积中,从N里面取值,有的值会被取多次的情况,分析如下:
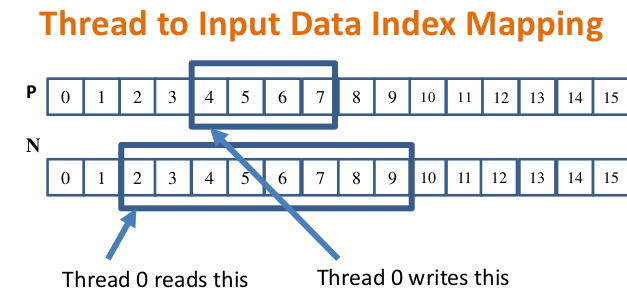
如果计算P4,需要使用到N2,N3,N4,N5,N6.计算P5,需要使用到N3,N4,N5,N6,N7. 计算P7,需要使用到N5,N6,N7,N8,N9.
可以看出有很多重复计算,如果以tile来划分,tile的长度是4,如上图,要计算P4,5,6,7.我们需要用到N2,N3,N4,N5,N6,N7,N8,N9.
把这几个数保存在sharedMemory里面,可以减少对globalMemory的取值次数.
对应代码如下:
#define TILE_WIDTH 4
#define MASK_WIDTH 5
#define n MASK_WIDTH/2
#define BLOCK_WIDTH TILE_WIDTH+MASK_WIDTH-1
dim3 dimBlock(BLOCK_WIDTH,1, 1);
dim3 dimGrid((Width-1)/O_TILE_WIDTH+1, 1, 1).
kernel代码:
float output = 0.0f;
if((index_i >= 0) && (index_i < Width) ) {
Ns[tx] = N[index_i];
}
else{
Ns[tx] = 0.0f;
}
if (threadIdx.x < O_TILE_WIDTH){
output = 0.0f;
for(j = 0; j < Mask_Width; j++) {
output += M[j] * Ns[j+threadIdx.x]; //从sharedMemory中取值.
}
P[index_o] = output;
}
2D卷积tile优化
二维卷积基于一维卷积, M由于是常量,可以利用 constant memory来提高访问速度. constant缓存在一个warp中是以广播的形式发送给每个thread.
二维卷积的经常是用到图像处理.
Image Matrix Type in HPP Course
// Image Matrix Structure declaration
typedef struct {
int width;
int height;
int pitch;
int channels;
float* data;
} * wbImage_t;
图像一个点表示一个信息,由于很多图像是彩色的,所以一个点是不够的,所以有这个channels的概念,比如RGB就分别表示R channel, G channel, B channel.
二维卷积的code1 :


#include <wb.h> #define wbCheck(stmt) do { \ cudaError_t err = stmt; \ if (err != cudaSuccess) { \ wbLog(ERROR, "Failed to run stmt ", #stmt); \ wbLog(ERROR, "Got CUDA error ... ", cudaGetErrorString(err)); \ return -1; \ } \ } while(0) #define MASK_WIDTH 5 #define MASK_RADIUS MASK_WIDTH/2 #define O_TILE_WIDTH 16 //12 #define BLOCK_WIDTH (O_TILE_WIDTH + MASK_WIDTH - 1) #define CLAMP(x) (min(max((x), 0.0), 1.0)) //@@ INSERT CODE HERE __global__ void convolution_2d_kernel(float *I, const float* __restrict__ M, float *P, int channels, int width, int height) { __shared__ float Ns[BLOCK_WIDTH][BLOCK_WIDTH]; int i,j,k; int tx = threadIdx.x; int ty = threadIdx.y; int row_o = blockIdx.y*O_TILE_WIDTH + ty; int col_o = blockIdx.x*O_TILE_WIDTH + tx; int row_i = row_o - MASK_RADIUS; int col_i = col_o - MASK_RADIUS; for (k = 0; k < channels; k++) { if((row_i >=0 && row_i < height) && (col_i >=0 && col_i < width)) Ns[ty][tx] = I[(row_i * width + col_i) * channels + k]; else Ns[ty][tx] = 0.0f; __syncthreads(); float output = 0.0f; if(ty < O_TILE_WIDTH && tx < O_TILE_WIDTH){ for(i = 0; i < MASK_WIDTH; i++) { for(j = 0; j < MASK_WIDTH; j++) { output += M[j * MASK_WIDTH + i] * Ns[i+ty][j+tx]; } } if(row_o < height && col_o < width) P[(row_o * width + col_o) * channels + k] = CLAMP(output); } __syncthreads(); // printf("kernel %f \n ",P[row_o * width + col_o]); } } int main(int argc, char* argv[]) { wbArg_t args; int maskRows; int maskColumns; int imageChannels; int imageWidth; int imageHeight; char * inputImageFile; char * inputMaskFile; wbImage_t inputImage; wbImage_t outputImage; float * hostInputImageData; float * hostOutputImageData; float * hostMaskData; float * deviceInputImageData; float * deviceOutputImageData; float * deviceMaskData; args = wbArg_read(argc, argv); /* parse the input arguments */ inputImageFile = wbArg_getInputFile(args, 0); inputMaskFile = wbArg_getInputFile(args, 1); inputImage = wbImport(inputImageFile); hostMaskData = (float *) wbImport(inputMaskFile, &maskRows, &maskColumns); assert(maskRows == 5); /* mask height is fixed to 5 in this mp */ assert(maskColumns == 5); /* mask width is fixed to 5 in this mp */ imageWidth = wbImage_getWidth(inputImage); imageHeight = wbImage_getHeight(inputImage); imageChannels = wbImage_getChannels(inputImage); printf("imageChannels =%d\n", imageChannels); outputImage = wbImage_new(imageWidth, imageHeight, imageChannels); hostInputImageData = wbImage_getData(inputImage); hostOutputImageData = wbImage_getData(outputImage); wbTime_start(GPU, "Doing GPU Computation (memory + compute)"); wbTime_start(GPU, "Doing GPU memory allocation"); cudaMalloc((void **) &deviceInputImageData, imageWidth * imageHeight * imageChannels * sizeof(float)); cudaMalloc((void **) &deviceOutputImageData, imageWidth * imageHeight * imageChannels * sizeof(float)); cudaMalloc((void **) &deviceMaskData, maskRows * maskColumns * sizeof(float)); wbTime_stop(GPU, "Doing GPU memory allocation"); wbTime_start(Copy, "Copying data to the GPU"); cudaMemcpy(deviceInputImageData, hostInputImageData, imageWidth * imageHeight * imageChannels * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(deviceMaskData, hostMaskData, maskRows * maskColumns * sizeof(float), cudaMemcpyHostToDevice); wbTime_stop(Copy, "Copying data to the GPU"); wbTime_start(Compute, "Doing the computation on the GPU"); //@@ INSERT CODE HERE dim3 dimGrid(ceil((float)imageWidth/O_TILE_WIDTH), ceil((float)imageHeight/O_TILE_WIDTH)); dim3 dimBlock(BLOCK_WIDTH, BLOCK_WIDTH, 1); convolution_2d_kernel<<<dimGrid, dimBlock>>>(deviceInputImageData, deviceMaskData, deviceOutputImageData, imageChannels, imageWidth, imageHeight); cudaDeviceSynchronize(); // note this wbTime_stop(Compute, "Doing the computation on the GPU"); wbTime_start(Copy, "Copying data from the GPU"); cudaMemcpy(hostOutputImageData, deviceOutputImageData, imageWidth * imageHeight * imageChannels * sizeof(float), cudaMemcpyDeviceToHost); wbTime_stop(Copy, "Copying data from the GPU"); wbTime_stop(GPU, "Doing GPU Computation (memory + compute)"); wbSolution(args, outputImage); cudaFree(deviceInputImageData); cudaFree(deviceOutputImageData); cudaFree(deviceMaskData); free(hostMaskData); wbImage_delete(outputImage); wbImage_delete(inputImage); return 0; }
二维卷积的code2,和code1的区别是,block的设置不同,这里设置的blocksize 是tile size,所以input 的值是不够的,在kernel中加载input分成两次来做.
#include <wb.h> // Check ec2-174-129-21-232.compute-1.amazonaws.com:8080/mp/6 for more information #define wbCheck(stmt) do { \ cudaError_t err = stmt; \ if (err != cudaSuccess) { \ wbLog(ERROR, "Failed to run stmt ", #stmt); \ return -1; \ } \ } while(0) #define Mask_width 5 #define Mask_radius Mask_width/2 #define TILE_WIDTH 16 #define w (TILE_WIDTH + Mask_width - 1) #define clamp(x) (min(max((x), 0.0), 1.0)) //@@ INSERT CODE HERE __global__ void convolution(float *I, const float* __restrict__ M, float *P, int channels, int width, int height) { __shared__ float N_ds[w][w]; int k; for (k = 0; k < channels; k++) { // First batch loading int dest = threadIdx.y * TILE_WIDTH + threadIdx.x, destY = dest / w, destX = dest % w, srcY = blockIdx.y * TILE_WIDTH + destY - Mask_radius, srcX = blockIdx.x * TILE_WIDTH + destX - Mask_radius, src = (srcY * width + srcX) * channels + k; if (srcY >= 0 && srcY < height && srcX >= 0 && srcX < width) N_ds[destY][destX] = I[src]; else N_ds[destY][destX] = 0; // Second batch loading dest = threadIdx.y * TILE_WIDTH + threadIdx.x + TILE_WIDTH * TILE_WIDTH; destY = dest / w, destX = dest % w; srcY = blockIdx.y * TILE_WIDTH + destY - Mask_radius; srcX = blockIdx.x * TILE_WIDTH + destX - Mask_radius; src = (srcY * width + srcX) * channels + k; if (destY < w) { if (srcY >= 0 && srcY < height && srcX >= 0 && srcX < width) N_ds[destY][destX] = I[src]; else N_ds[destY][destX] = 0; } __syncthreads(); float accum = 0; int y, x; for (y = 0; y < Mask_width; y++) for (x = 0; x < Mask_width; x++) accum += N_ds[threadIdx.y + y][threadIdx.x + x] * M[y * Mask_width + x]; y = blockIdx.y * TILE_WIDTH + threadIdx.y; x = blockIdx.x * TILE_WIDTH + threadIdx.x; if (y < height && x < width) P[(y * width + x) * channels + k] = clamp(accum); __syncthreads(); } } int main(int argc, char* argv[]) { wbArg_t arg; int maskRows; int maskColumns; int imageChannels; int imageWidth; int imageHeight; char * inputImageFile; char * inputMaskFile; wbImage_t inputImage; wbImage_t outputImage; float * hostInputImageData; float * hostOutputImageData; float * hostMaskData; float * deviceInputImageData; float * deviceOutputImageData; float * deviceMaskData; arg = wbArg_read(argc, argv); /* parse the input arguments */ inputImageFile = wbArg_getInputFile(arg, 0); inputMaskFile = wbArg_getInputFile(arg, 1); inputImage = wbImport(inputImageFile); hostMaskData = (float *) wbImport(inputMaskFile, &maskRows, &maskColumns); assert(maskRows == 5); /* mask height is fixed to 5 in this mp */ assert(maskColumns == 5); /* mask width is fixed to 5 in this mp */ imageWidth = wbImage_getWidth(inputImage); imageHeight = wbImage_getHeight(inputImage); imageChannels = wbImage_getChannels(inputImage); outputImage = wbImage_new(imageWidth, imageHeight, imageChannels); hostInputImageData = wbImage_getData(inputImage); hostOutputImageData = wbImage_getData(outputImage); wbTime_start(GPU, "Doing GPU Computation (memory + compute)"); wbTime_start(GPU, "Doing GPU memory allocation"); cudaMalloc((void **) &deviceInputImageData, imageWidth * imageHeight * imageChannels * sizeof(float)); cudaMalloc((void **) &deviceOutputImageData, imageWidth * imageHeight * imageChannels * sizeof(float)); cudaMalloc((void **) &deviceMaskData, maskRows * maskColumns * sizeof(float)); wbTime_stop(GPU, "Doing GPU memory allocation"); wbTime_start(Copy, "Copying data to the GPU"); cudaMemcpy(deviceInputImageData, hostInputImageData, imageWidth * imageHeight * imageChannels * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(deviceMaskData, hostMaskData, maskRows * maskColumns * sizeof(float), cudaMemcpyHostToDevice); wbTime_stop(Copy, "Copying data to the GPU"); wbTime_start(Compute, "Doing the computation on the GPU"); //@@ INSERT CODE HERE dim3 dimGrid(ceil((float)imageWidth/TILE_WIDTH), ceil((float)imageHeight/TILE_WIDTH)); dim3 dimBlock(TILE_WIDTH, TILE_WIDTH, 1); convolution<<<dimGrid, dimBlock>>>(deviceInputImageData, deviceMaskData, deviceOutputImageData, imageChannels, imageWidth, imageHeight); wbTime_stop(Compute, "Doing the computation on the GPU"); wbTime_start(Copy, "Copying data from the GPU"); cudaMemcpy(hostOutputImageData, deviceOutputImageData, imageWidth * imageHeight * imageChannels * sizeof(float), cudaMemcpyDeviceToHost); wbTime_stop(Copy, "Copying data from the GPU"); wbTime_stop(GPU, "Doing GPU Computation (memory + compute)"); wbSolution(arg, outputImage); cudaFree(deviceInputImageData); cudaFree(deviceOutputImageData); cudaFree(deviceMaskData); free(hostMaskData); wbImage_delete(outputImage); wbImage_delete(inputImage); return 0; }

